





































![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)
![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)




































































































.webp?#)





















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)





































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























































Postgres Is All You Need
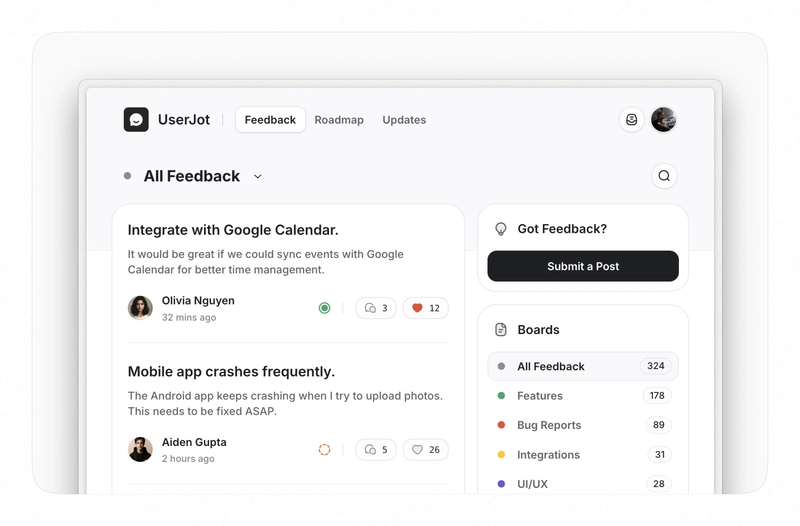
When I started working on my second SaaS product, UserJot, I decided to simplify everything about the tech stack. My first SaaS product, LogSnag is an analytics tool built on a fairly complex infrastructure: Redis, Postgres, ClickHouse, Amazon SQS, and more. That complexity serves its purpose well, given LogSnag's demands. But for UserJot, a user feedback platform, I challenged myself to go in the complete opposite direction: simplicity above all. The question was: Could I run an entire, production-ready SaaS app exclusively on Postgres? The answer turned out to be a resounding yes. Complexity Is Not Your Friend (Early On) Early-stage products rarely die because of scaling challenges. They suffer from premature complexity and lack of market fit. Every external service you add—Redis, BullMQ, Pinecone, SQS—introduces complexity, maintenance, and potential points of failure. With UserJot, I focused on one guiding principle: Don't solve problems you don't have. Turns out, Postgres alone solved nearly every data-related challenge I had. Using Postgres as Your Job Queue Event-driven architectures are great. Side-effects stay isolated, and your core logic remains clean. Traditionally, achieving this would mean using Redis and BullMQ or similar services. But there's a simpler way: Enter pg-boss pg-boss is a lightweight, PostgreSQL-based job queue using SELECT FOR UPDATE SKIP LOCKED. It provides reliable job scheduling, retries, delayed jobs, and concurrency—without external dependencies. I've written about it in detail here. This means: No Redis. Fewer moving parts. Easy to debug. And if your volume increases dramatically? You can always add Redis back later—when you actually have that problem. Vector Search with Postgres (Goodbye Pinecone) UserJot includes a number of features that rely on vector search. Typically, you'd reach for a specialized vector database like Pinecone or Weaviate. Instead, I used pgvector—a PostgreSQL extension that adds native vector search capabilities directly inside your database. It allows you to store embeddings and perform similarity searches seamlessly: SELECT id, title FROM submissions WHERE project_id = 'xyz' ORDER BY embedding $1 LIMIT 5; Benefits: Single source of truth: Data stays unified. Easy joins and filters: Combine vector similarity queries with standard SQL queries effortlessly. Simplified infrastructure: No additional data synchronization or dual writes. Again, if scale demands it, migrating to a dedicated vector database is straightforward—but likely unnecessary for most SaaS businesses. If you're interested in learning more about vector search with Postgres, I've written about it in detail here. Postgres as a Key-Value Store Need key-value storage for temporary tokens, feature flags, or configuration values? Typically, you'd reach for Redis. But again, Postgres has you covered: CREATE TABLE kv_store ( key TEXT PRIMARY KEY, value TEXT, expires_at TIMESTAMP WITH TIME ZONE ); -- Retrieve keys that haven't expired yet SELECT * FROM kv_store WHERE key = 'feature_flag' AND (expires_at IS NULL OR expires_at > NOW()); Postgres handles this effortlessly with added benefits: Persistent data storage Easy migrations and schema evolution Rich querying capabilities For most indie or smaller SaaS products (small meaning smaller than Netflix-scale products), Postgres is more than sufficient here. But Will It Actually Scale? Absolutely. Postgres can scale vertically exceptionally well. You can easily handle millions of rows, thousands of queries per second, and complex querying. Modern Postgres provides advanced indexing, caching, partitioning, and optimization strategies to meet high performance needs. When I say it's enough for "small products," I mean small relative to massive-scale tech giants. In reality, 99.9% of SaaS businesses—including highly successful indie products—will never push Postgres to its limits. And if you're lucky enough to hit that scale? Congratulations! You can easily break out the parts that need dedicated infrastructure. What UserJot Runs Entirely on Postgres Today, the UserJot backend runs exclusively on PostgreSQL for: Core relational data Job queues (pg-boss) AI embedding storage and vector search (pgvector) Key-value data storage Event-driven side-effects (triggers) And these are just the tip of the iceberg. Postgres has a ton more features and extensions that can be used for a variety of different use cases. // Detect dark theme var iframe = document.getElementById('tweet-1809032371586367695-977'); if (document.body.className.includes('dark-theme')) { iframe.src = "https://platform.twitter.com/embed/Tweet.html?id=1809032371586367695&theme=dark" } Final Thoughts Your infrastructure should reflect the size of the problems you're actually facing, not hypothetic
When I started working on my second SaaS product, UserJot, I decided to simplify everything about the tech stack.
My first SaaS product, LogSnag is an analytics tool built on a fairly complex infrastructure: Redis, Postgres, ClickHouse, Amazon SQS, and more. That complexity serves its purpose well, given LogSnag's demands. But for UserJot, a user feedback platform, I challenged myself to go in the complete opposite direction: simplicity above all.
The question was: Could I run an entire, production-ready SaaS app exclusively on Postgres?
The answer turned out to be a resounding yes.
Complexity Is Not Your Friend (Early On)
Early-stage products rarely die because of scaling challenges. They suffer from premature complexity and lack of market fit. Every external service you add—Redis, BullMQ, Pinecone, SQS—introduces complexity, maintenance, and potential points of failure.
With UserJot, I focused on one guiding principle:
Don't solve problems you don't have.
Turns out, Postgres alone solved nearly every data-related challenge I had.
Using Postgres as Your Job Queue
Event-driven architectures are great. Side-effects stay isolated, and your core logic remains clean. Traditionally, achieving this would mean using Redis and BullMQ or similar services.
But there's a simpler way:
Enter pg-boss
pg-boss is a lightweight, PostgreSQL-based job queue using SELECT FOR UPDATE SKIP LOCKED. It provides reliable job scheduling, retries, delayed jobs, and concurrency—without external dependencies. I've written about it in detail here.
This means:
- No Redis.
- Fewer moving parts.
- Easy to debug.
And if your volume increases dramatically? You can always add Redis back later—when you actually have that problem.
Vector Search with Postgres (Goodbye Pinecone)
UserJot includes a number of features that rely on vector search. Typically, you'd reach for a specialized vector database like Pinecone or Weaviate.
Instead, I used pgvector—a PostgreSQL extension that adds native vector search capabilities directly inside your database. It allows you to store embeddings and perform similarity searches seamlessly:
SELECT id, title
FROM submissions
WHERE project_id = 'xyz'
ORDER BY embedding <-> $1
LIMIT 5;
Benefits:
- Single source of truth: Data stays unified.
- Easy joins and filters: Combine vector similarity queries with standard SQL queries effortlessly.
- Simplified infrastructure: No additional data synchronization or dual writes.
Again, if scale demands it, migrating to a dedicated vector database is straightforward—but likely unnecessary for most SaaS businesses. If you're interested in learning more about vector search with Postgres, I've written about it in detail here.
Postgres as a Key-Value Store
Need key-value storage for temporary tokens, feature flags, or configuration values?
Typically, you'd reach for Redis. But again, Postgres has you covered:
CREATE TABLE kv_store (
key TEXT PRIMARY KEY,
value TEXT,
expires_at TIMESTAMP WITH TIME ZONE
);
-- Retrieve keys that haven't expired yet
SELECT * FROM kv_store
WHERE key = 'feature_flag'
AND (expires_at IS NULL OR expires_at > NOW());
Postgres handles this effortlessly with added benefits:
- Persistent data storage
- Easy migrations and schema evolution
- Rich querying capabilities
For most indie or smaller SaaS products (small meaning smaller than Netflix-scale products), Postgres is more than sufficient here.
But Will It Actually Scale?
Absolutely.
Postgres can scale vertically exceptionally well. You can easily handle millions of rows, thousands of queries per second, and complex querying. Modern Postgres provides advanced indexing, caching, partitioning, and optimization strategies to meet high performance needs.
When I say it's enough for "small products," I mean small relative to massive-scale tech giants. In reality, 99.9% of SaaS businesses—including highly successful indie products—will never push Postgres to its limits.
And if you're lucky enough to hit that scale? Congratulations! You can easily break out the parts that need dedicated infrastructure.
What UserJot Runs Entirely on Postgres
Today, the UserJot backend runs exclusively on PostgreSQL for:
- Core relational data
- Job queues (pg-boss)
- AI embedding storage and vector search (pgvector)
- Key-value data storage
- Event-driven side-effects (triggers)
And these are just the tip of the iceberg. Postgres has a ton more features and extensions that can be used for a variety of different use cases.
// Detect dark theme var iframe = document.getElementById('tweet-1809032371586367695-977'); if (document.body.className.includes('dark-theme')) { iframe.src = "https://platform.twitter.com/embed/Tweet.html?id=1809032371586367695&theme=dark" }
Final Thoughts
Your infrastructure should reflect the size of the problems you're actually facing, not hypothetical future ones.
Choosing simplicity early on means:
- Reduced infrastructure complexity and costs
- Faster development cycles
- Easier debugging and maintenance
- Ownership of the infrastructure
- Easier to setup a local development environment
- Easier to scale
Complexity will always find you eventually, but simplicity won't return easily once lost.
Postgres is more than a database—it's the ideal foundation for building great products quickly and effectively.
If you're building or considering a simplified stack around Postgres, I'd love to hear your story! And if you're looking for a customer feedback platform, I would love to hear what you think about UserJot.