
_Prostock-studio_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




























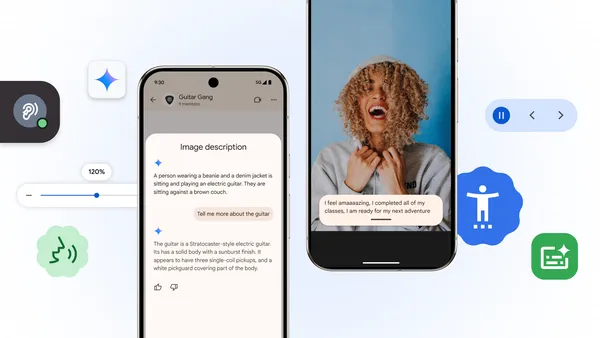












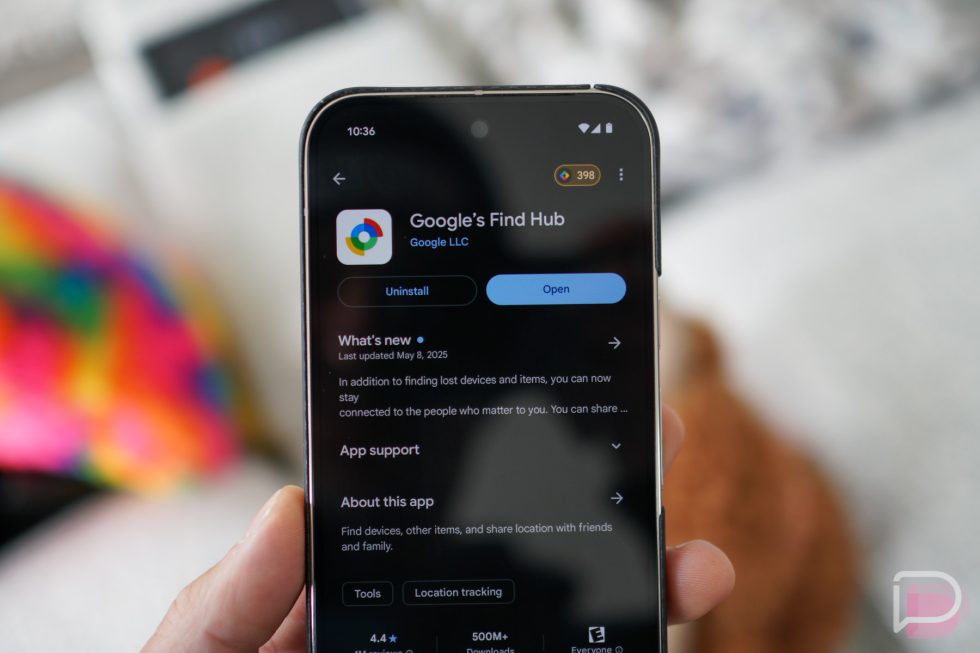






































![What’s new in Android’s May 2025 Google System Updates [U: 5/19]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)





















































































.webp?#)























































































































![[The AI Show Episode 147]: OpenAI Abandons For-Profit Plan, AI College Cheating Epidemic, Apple Says AI Will Replace Search Engines & HubSpot’s AI-First Scorecard](https://www.marketingaiinstitute.com/hubfs/ep%20147%20cover.png)






















































































































































![How to make Developer Friends When You Don't Live in Silicon Valley, with Iraqi Engineer Code;Life [Podcast #172]](https://cdn.hashnode.com/res/hashnode/image/upload/v1747360508340/f07040cd-3eeb-443c-b4fb-370f6a4a14da.png?#)































































































Salesforce AI Researchers Introduce UAEval4RAG: A New Benchmark to Evaluate RAG Systems’ Ability to Reject Unanswerable Queries
While RAG enables responses without extensive model retraining, current evaluation frameworks focus on accuracy and relevance for answerable questions, neglecting the crucial ability to reject unsuitable or unanswerable requests. This creates high risks in real-world applications where inappropriate responses can lead to misinformation or harm. Existing unanswerability benchmarks are inadequate for RAG systems, as they […] The post Salesforce AI Researchers Introduce UAEval4RAG: A New Benchmark to Evaluate RAG Systems’ Ability to Reject Unanswerable Queries appeared first on MarkTechPost.

While RAG enables responses without extensive model retraining, current evaluation frameworks focus on accuracy and relevance for answerable questions, neglecting the crucial ability to reject unsuitable or unanswerable requests. This creates high risks in real-world applications where inappropriate responses can lead to misinformation or harm. Existing unanswerability benchmarks are inadequate for RAG systems, as they contain static, general requests that cannot be customized to specific knowledge bases. When RAG systems reject queries, it often stems from retrieval failures rather than genuine recognition that certain requests should not be fulfilled, highlighting a critical gap in evaluation methodologies.
Unanswerable benchmarks research has provided insights into model noncompliance, exploring ambiguous questions and underspecified inputs. RAG evaluation has advanced through diverse LLM-based techniques, with methods like RAGAS and ARES evaluating retrieved document relevance, while RGB and MultiHop-RAG focus on output accuracy against ground truths. In Unanswerable RAG Evaluation, some benchmarks have begun evaluating rejection capabilities in RAG systems, but use LLM-generated unanswerable contexts as external knowledge and narrowly evaluate rejection of single-type unanswerable requests. However, current methods fail to adequately assess RAG systems’ ability to reject diverse unanswerable requests across user-provided knowledge bases.
Researchers from Salesforce Research have proposed UAEval4RAG, a framework designed to synthesize datasets of unanswerable requests for any external knowledge database and automatically evaluate RAG systems. UAEval4RAG not only assesses how well RAG systems respond to answerable requests but also their ability to reject six distinct categories of unanswerable queries: Underspecified, False-presuppositions, Nonsensical, Modality-limited, Safety Concerns, and Out-of-Database. Researchers also create an automated pipeline that generates diverse and challenging requests designed for any given knowledge base. The generated datasets are then used to evaluate RAG systems with two LLM-based metrics: Unanswerable Ratio and Acceptable Ratio.

UAEval4RAG evaluates how different RAG components affect performance on both answerable and unanswerable queries. After testing 27 combinations of embedding models, retrieval models, rewriting methods, rerankers, 3 LLMs, and 3 prompting techniques across four benchmarks, results show no single configuration optimizes performance across all datasets due to varying knowledge distribution. LLM selection proves critical, with Claude 3.5 Sonnet improving correctness by 0.4%, and the unanswerable acceptable ratio by 10.4% over GPT-4o. Prompt design impacts performance, with optimal prompts enhancing unanswerable query performance by 80%. Moreover, three metrics evaluate the capability of RAG systems to reject unanswerable requests: Acceptable Ratio, Unanswered Ratio, and Joint Score.
The UAEval4RAG shows high effectiveness in generating unanswerable requests, with 92% accuracy and strong inter-rater agreement scores of 0.85 and 0.88 for TriviaQA and Musique datasets, respectively. LLM-based metrics show robust performance with high accuracy and F1 scores across three LLMs, validating their reliability in evaluating RAG systems regardless of the backbone model used. Comprehensive analysis reveals that no single combination of RAG components excels across all datasets, while prompt design impacts hallucination control and query rejection capabilities. Dataset characteristics with modality-related performance correlate to keyword prevalence (18.41% in TriviaQA versus 6.36% in HotpotQA), and safety-concerned request handling based on chunk availability per question.

In conclusion, researchers introduced UAEval4RAG, a framework for evaluating RAG systems’ ability to handle unanswerable requests, addressing a critical gap in existing evaluation methods that predominantly focus on answerable queries. Future work could benefit from integrating more diverse human-verified sources to increase generalizability. While the proposed metrics demonstrate strong alignment with human evaluations, tailoring them to specific applications could further enhance effectiveness. Current evaluation focuses on single-turn interactions, whereas extending the framework to multi-turn dialogues would better capture real-world scenarios where systems engage in clarifying exchanges with users to manage underspecified or ambiguous queries.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter.
The post Salesforce AI Researchers Introduce UAEval4RAG: A New Benchmark to Evaluate RAG Systems’ Ability to Reject Unanswerable Queries appeared first on MarkTechPost.






