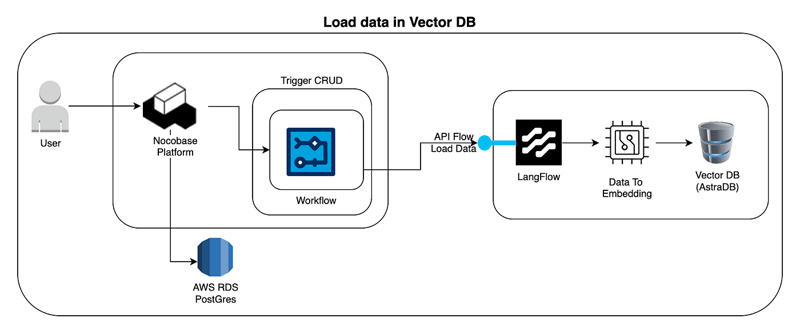





























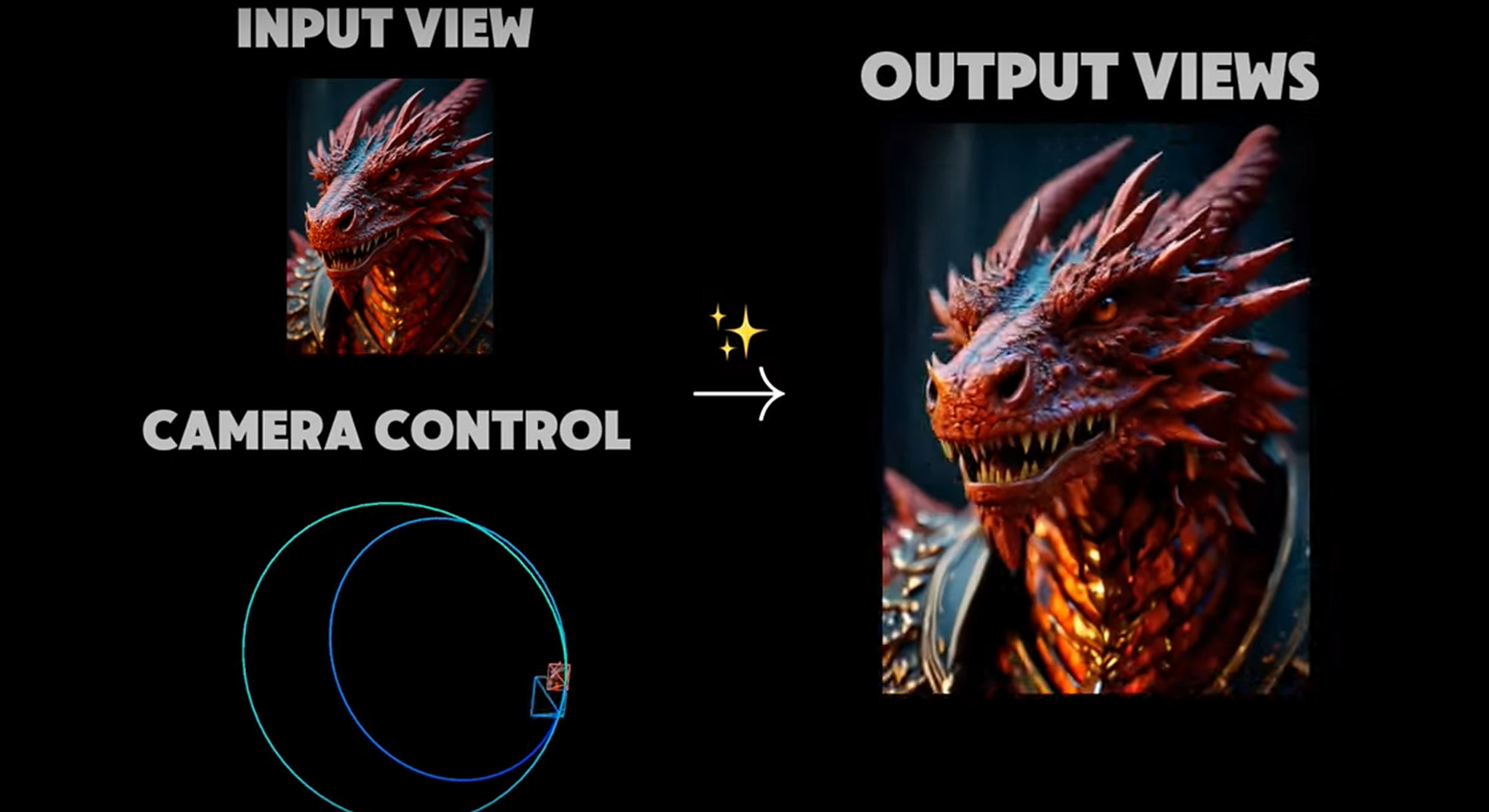












![Apple C1 vs Qualcomm Modem Performance [Speedtest]](https://www.iclarified.com/images/news/96767/96767/96767-640.jpg)
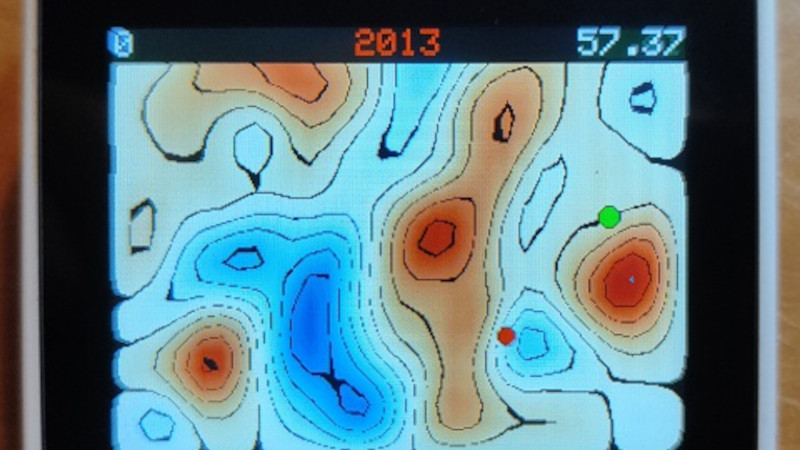
![Apple Studio Display On Sale for $1249 [Lowest Price Ever]](https://www.iclarified.com/images/news/96770/96770/96770-640.jpg)












![[Fixed] Chromecast (2nd gen) and Audio can’t Cast in ‘Untrusted’ outage](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2019/08/chromecast_audio_1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

























































































































































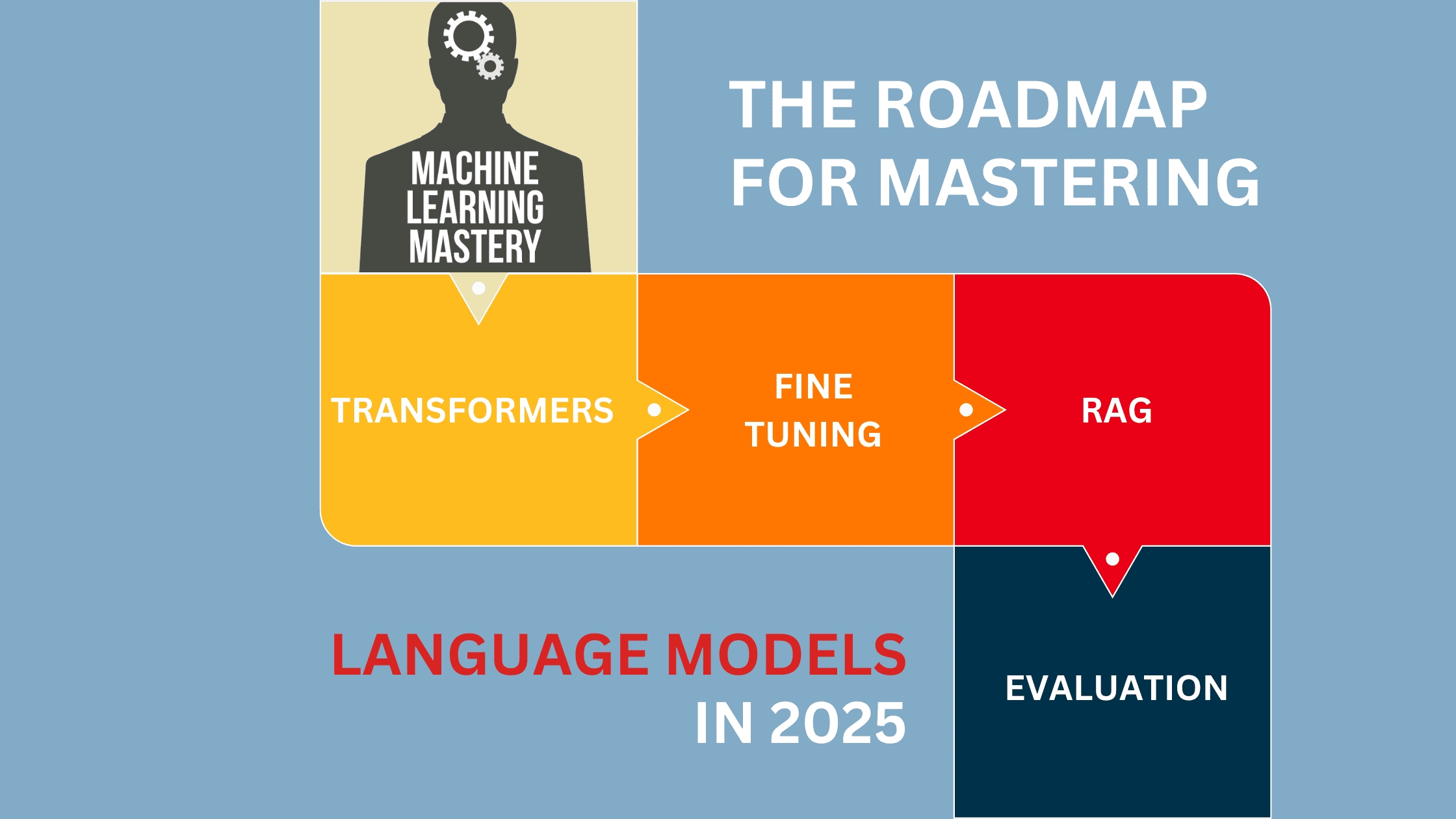
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)

































































































![Is XMPP a good option for a messaging system in an app? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
































































































(Developer Tutorial) How to Read PDF Tables in C#?
Extracting structured data from PDF files is often challenging, especially when dealing with tables. Business analysts, data scientists, and developers frequently need to extract tabular data for further processing, reporting, or analysis. Fortunately, IronPDF, a powerful C# PDF library, makes this task easy by providing robust methods for reading and extracting tables from PDF documents. In this article, you'll learn how to extract table data from PDFs in C# using IronPDF. Why Use IronPDF for Reading Tables? IronPDF is a .NET library that provides a simple way to create, manipulate, and extract data from PDF files. It supports the latest .NET versions and allows developers to work with PDFs seamlessly without requiring external dependencies like Adobe Acrobat. Key Features: ✅ Load and create PDF files from HTML, images, and other formats ✅ Extract data such as text, images, and tables from PDFs ✅ Save and print PDF documents ✅ Merge and split PDFs easily ✅ Works with .NET Core, .NET 6/7/8, and .NET Framework The PDF file format is widely used for sharing documents due to its consistency across devices. In this guide, we'll extract data from a sample PDF file while ensuring the extracted content maintains its original PDF format. Steps to Extract Table Data in C To extract tables from PDF documents using IronPDF, follow these steps: Step 1: Install IronPDF in C Before you begin, ensure you have Visual Studio installed. You can install IronPDF using NuGet Package Manager: Open Visual Studio and create a new Console Application. Open the NuGet Package Manager by right-clicking the project in the Solution Explorer. Search for IronPDF and install it. Alternatively, you can install it using the Package Manager Console: Install-Package IronPDF Step 2: Create a PDF Document with Table Data Before extracting data, let's create a sample PDF document containing a table. We will generate this using HTML and convert it to PDF.
Extracting structured data from PDF files is often challenging, especially when dealing with tables. Business analysts, data scientists, and developers frequently need to extract tabular data for further processing, reporting, or analysis. Fortunately, IronPDF, a powerful C# PDF library, makes this task easy by providing robust methods for reading and extracting tables from PDF documents.
In this article, you'll learn how to extract table data from PDFs in C# using IronPDF.
Why Use IronPDF for Reading Tables?
IronPDF is a .NET library that provides a simple way to create, manipulate, and extract data from PDF files. It supports the latest .NET versions and allows developers to work with PDFs seamlessly without requiring external dependencies like Adobe Acrobat.
Key Features:
✅ Load and create PDF files from HTML, images, and other formats
✅ Extract data such as text, images, and tables from PDFs
✅ Save and print PDF documents
✅ Merge and split PDFs easily
✅ Works with .NET Core, .NET 6/7/8, and .NET Framework
The PDF file format is widely used for sharing documents due to its consistency across devices. In this guide, we'll extract data from a sample PDF file while ensuring the extracted content maintains its original PDF format.
Steps to Extract Table Data in C
To extract tables from PDF documents using IronPDF, follow these steps:
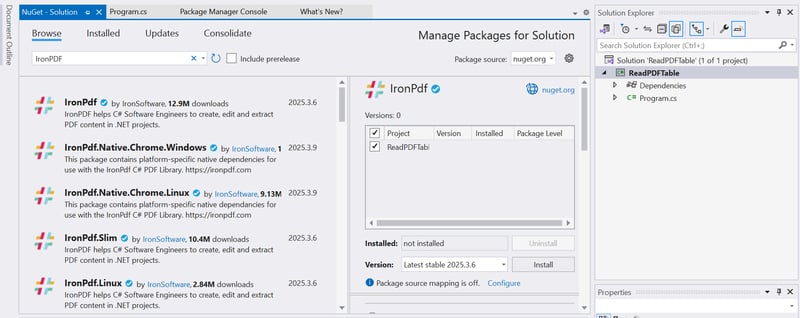
Step 1: Install IronPDF in C
Before you begin, ensure you have Visual Studio installed. You can install IronPDF using NuGet Package Manager:
- Open Visual Studio and create a new Console Application.
- Open the NuGet Package Manager by right-clicking the project in the Solution Explorer.
- Search for IronPDF and install it.
Alternatively, you can install it using the Package Manager Console:
Install-Package IronPDF
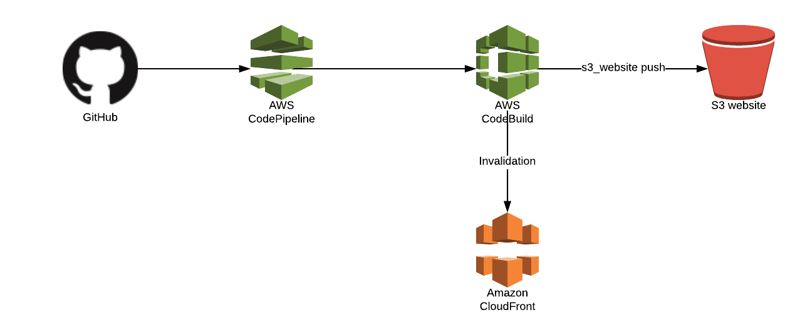
Step 2: Create a PDF Document with Table Data
Before extracting data, let's create a sample PDF document containing a table. We will generate this using HTML and convert it to PDF.