




















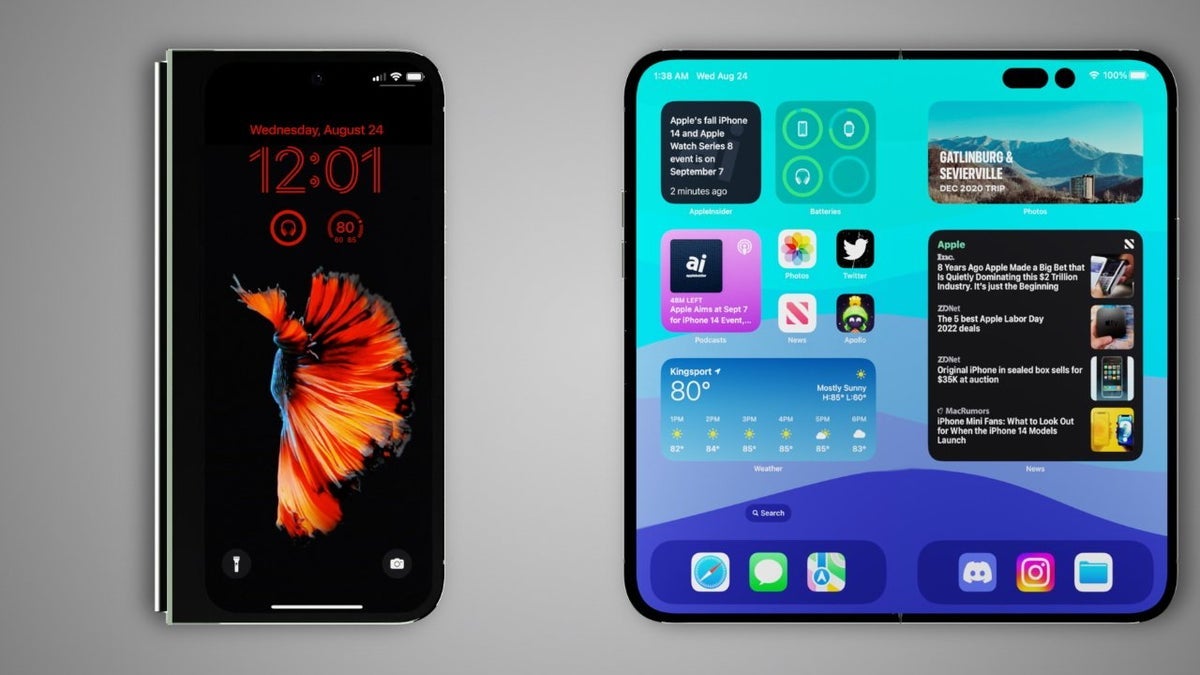






































![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)

![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)











![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













-xl-xl.jpg)

















































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)















































































































![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)



























-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















































I Built an LLM Framework in just 100 Lines — Here is Why
Have you ever stared at a complex AI framework and wondered, "Does it really need to be this complicated?" After a year of struggling with bloated frameworks, I decided to strip away anything unnecessary. The result is Pocket Flow, a minimalist LLM framework in just 100 lines of code. Current LLM Frameworks Are Bloated! For the past year, I've been building AI applications using popular frameworks like LangChain. The experience has been consistently frustrating: Bloated Abstraction: As Octomind's engineering team explains: "LangChain was helpful at first when our simple requirements aligned with its usage presumptions. But its high-level abstractions soon made our code more difficult to understand and frustrating to maintain." These frameworks hide simple functionality behind unnecessary complexity. Implementation Nightmares: Beyond the abstractions, these frameworks burden developers with dependency bloat, version conflicts, and constantly changing interfaces. Developers often complain: "It's unstable, the interface constantly changes, the documentation is regularly out of date." Another developer jokes: "In the time it took to read this sentence langchain deprecated 4 classes without updating documentation." This led me to wonder: Do we really need so many wrappers? What if we stripped everything away? What is truly minimal and viable? Enter Pocket Flow: 100 Lines For the Core Abstraction After a year of building LLM applications from scratch, I had a revelation: beneath all the complexity, LLM systems are fundamentally just simple directed graphs. By stripping away the unnecessary layers, I created Pocket Flow—a framework with zero bloat, zero dependencies, and zero vendor lock-in, all in just 100 lines of code. The Simple Building Blocks Think of Pocket Flow like a well-organized kitchen: Nodes are like cooking stations (chopping, cooking, plating) Flow is the recipe dictating which station to visit next Shared store is the countertop where ingredients are visible to all stations In our kitchen (agent system): Each station (Node) performs three simple operations: Prep: Retrieve what you need from the shared store (gather ingredients) Exec: Perform your specialized task (cook the ingredients) Post: Return results to the shared store and determine next steps (serve the dish and decide what to make next) The recipe (Flow) directs execution based on conditions: "If vegetables are chopped, proceed to cooking station" "If meal is cooked, move to plating station" We also support batch processing, asynchronous execution, and parallel processing for both nodes and flows. And that's it! That's all you need to build LLM applications. No unnecessary abstractions, no complex architecture—just simple building blocks that can be composed to create powerful systems. What About Wrappers Like OpenAI? Unlike other frameworks, Pocket Flow deliberately avoids bundling vendor-specific APIs. Here's why: No Dependency Issues: Current LLM frameworks come with hundreds of MBs of dependencies. Pocket Flow has zero dependencies, keeping your project lean and nimble. No Vendor Lock-in: You're free to use any model you want, including local models like OpenLLaMA, without changing your core architecture. Customized Full Control: Want prompt caching, batching, and streaming? Build exactly what you need without fighting against pre-baked abstractions. What if you need an API wrapper? Just ask models like ChatGPT to write one on-the-fly. It's usually just 20 lines of code. This approach is far more flexible than rigid built-in wrappers or abstractions that quickly become outdated. With this minimal but powerful building blocks, you can build sophisticated agents, RAG systems, and LLM workflows with complete transparency and control over every component. Let's see an example! Let's build a Web Search Agent with Pocket Flow Let's build a simple web search agent using the building blocks from Pocket Flow. Such a simple web search AI agent that can search the web and answer questions - similar to tools like Perplexity AI. The Flow Design Here's the agent's behavior modeled as a simple flow graph: What Happens at Each Node? DecideAction — "Should we search the web, or do we already know enough?" Prep: Pulls in the original question and any previous search context from shared memory Exec: Asks the LLM whether to perform a web search or answer directly Post: Saves a search query if needed, and returns either "search" or "answer" as the next action SearchWeb — "Let's go fetch some fresh information." Prep: Retrieves the query generated in the last step Exec: Calls a web search API (Google, Bing, etc.), fetches results, and distills them into readable chunks Post: Adds the search results back into context, then loops back to DecideAction for re-evaluation AnswerQuestion — "We've got enough info—let's an
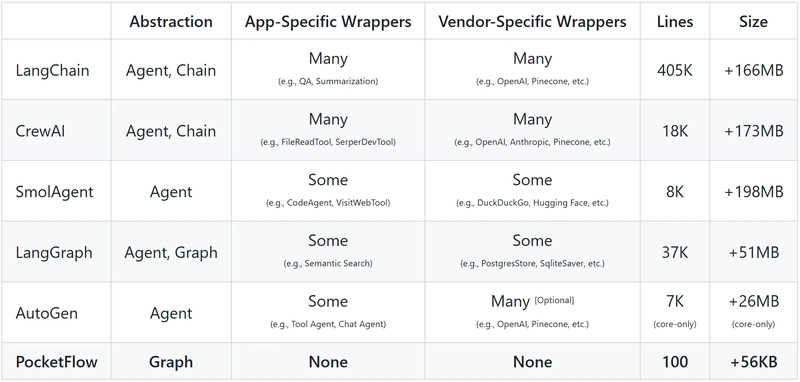
Have you ever stared at a complex AI framework and wondered, "Does it really need to be this complicated?" After a year of struggling with bloated frameworks, I decided to strip away anything unnecessary. The result is Pocket Flow, a minimalist LLM framework in just 100 lines of code.
Current LLM Frameworks Are Bloated!
For the past year, I've been building AI applications using popular frameworks like LangChain. The experience has been consistently frustrating:
Bloated Abstraction: As Octomind's engineering team explains: "LangChain was helpful at first when our simple requirements aligned with its usage presumptions. But its high-level abstractions soon made our code more difficult to understand and frustrating to maintain." These frameworks hide simple functionality behind unnecessary complexity.
Implementation Nightmares: Beyond the abstractions, these frameworks burden developers with dependency bloat, version conflicts, and constantly changing interfaces. Developers often complain: "It's unstable, the interface constantly changes, the documentation is regularly out of date." Another developer jokes: "In the time it took to read this sentence langchain deprecated 4 classes without updating documentation."
This led me to wonder: Do we really need so many wrappers? What if we stripped everything away? What is truly minimal and viable?
Enter Pocket Flow: 100 Lines For the Core Abstraction
After a year of building LLM applications from scratch, I had a revelation: beneath all the complexity, LLM systems are fundamentally just simple directed graphs. By stripping away the unnecessary layers, I created Pocket Flow—a framework with zero bloat, zero dependencies, and zero vendor lock-in, all in just 100 lines of code.
The Simple Building Blocks
Think of Pocket Flow like a well-organized kitchen:
- Nodes are like cooking stations (chopping, cooking, plating)
- Flow is the recipe dictating which station to visit next
- Shared store is the countertop where ingredients are visible to all stations
In our kitchen (agent system):
-
Each station (Node) performs three simple operations:
- Prep: Retrieve what you need from the shared store (gather ingredients)
- Exec: Perform your specialized task (cook the ingredients)
- Post: Return results to the shared store and determine next steps (serve the dish and decide what to make next)
-
The recipe (Flow) directs execution based on conditions:
- "If vegetables are chopped, proceed to cooking station"
- "If meal is cooked, move to plating station"
We also support batch processing, asynchronous execution, and parallel processing for both nodes and flows. And that's it! That's all you need to build LLM applications. No unnecessary abstractions, no complex architecture—just simple building blocks that can be composed to create powerful systems.
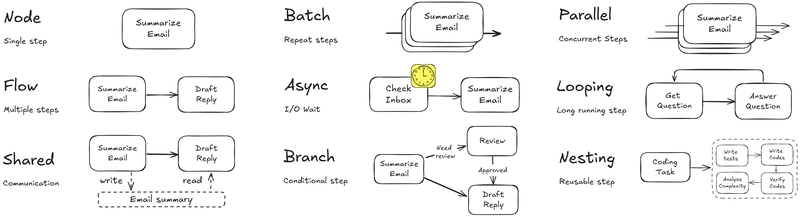
What About Wrappers Like OpenAI?
Unlike other frameworks, Pocket Flow deliberately avoids bundling vendor-specific APIs. Here's why:
- No Dependency Issues: Current LLM frameworks come with hundreds of MBs of dependencies. Pocket Flow has zero dependencies, keeping your project lean and nimble.
- No Vendor Lock-in: You're free to use any model you want, including local models like OpenLLaMA, without changing your core architecture.
- Customized Full Control: Want prompt caching, batching, and streaming? Build exactly what you need without fighting against pre-baked abstractions.
What if you need an API wrapper? Just ask models like ChatGPT to write one on-the-fly. It's usually just 20 lines of code. This approach is far more flexible than rigid built-in wrappers or abstractions that quickly become outdated.
With this minimal but powerful building blocks, you can build sophisticated agents, RAG systems, and LLM workflows with complete transparency and control over every component. Let's see an example!
Let's build a Web Search Agent with Pocket Flow
Let's build a simple web search agent using the building blocks from Pocket Flow.
Such a simple web search AI agent that can search the web and answer questions - similar to tools like Perplexity AI.
The Flow Design
Here's the agent's behavior modeled as a simple flow graph:
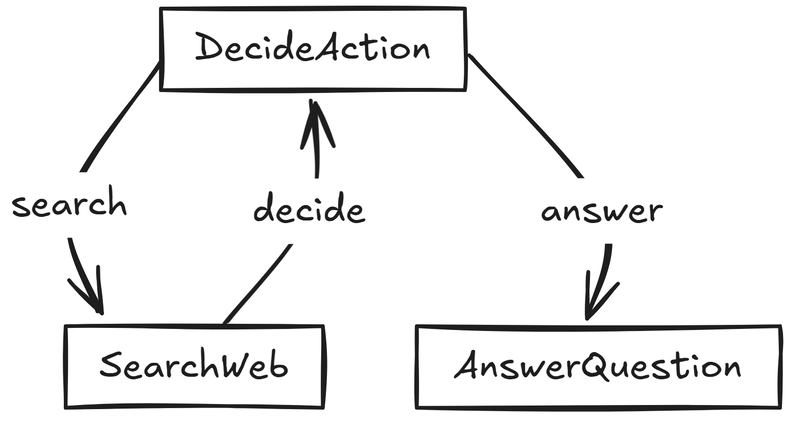
What Happens at Each Node?
-
DecideAction — "Should we search the web, or do we already know enough?"
- Prep: Pulls in the original question and any previous search context from shared memory
- Exec: Asks the LLM whether to perform a web search or answer directly
-
Post: Saves a search query if needed, and returns either
"search"or"answer"as the next action
-
SearchWeb — "Let's go fetch some fresh information."
- Prep: Retrieves the query generated in the last step
- Exec: Calls a web search API (Google, Bing, etc.), fetches results, and distills them into readable chunks
- Post: Adds the search results back into context, then loops back to DecideAction for re-evaluation
-
AnswerQuestion — "We've got enough info—let's answer the question."
- Prep: Collects the question and all search context
- Exec: Prompts the LLM to generate a well-researched, helpful answer
-
Post: Stores the final response and signals
"done"to finish the flow
The graph is dynamic, transparent, and easy to extend. You can plug in different LLMs, swap out the search engine, or insert new decision points—without ever breaking the core logic.
Let's Walk Through an Example
Imagine you asked our agent: "Who won the 2023 Super Bowl?" Here's what would happen step-by-step for each node:
-
DecideAction Node:
- LOOKS AT: Your question and what we know so far (nothing yet)
- THINKS: "I don't know who won the 2023 Super Bowl, I need to search"
- DECIDES: Search for "2023 Super Bowl winner"
- PASSES TO: SearchWeb station
-
SearchWeb Node:
- LOOKS AT: The search query "2023 Super Bowl winner"
- DOES: Searches the internet (imagine it finds "The Kansas City Chiefs won")
- SAVES: The search results to our shared countertop
- PASSES TO: Back to DecideAction station
-
DecideAction Node(second time):
- LOOKS AT: Your question and what we know now (search results)
- THINKS: "Great, now I know the Chiefs won the 2023 Super Bowl"
- DECIDES: We have enough info to answer
- PASSES TO: AnswerQuestion station
-
AnswerQuestion Node:
- LOOKS AT: Your question and all our research
- DOES: Creates a friendly answer using all the information
- SAVES: The final answer
- FINISHES: The task is complete!
And that's it! Simple, elegant, and powered by search. The entire agent implementation requires just a few hundred lines of code, built on our 100-line framework. You can see the complete code and run it yourself using this cookbook!
This is the essence of Pocket Flow: composable nodes and simple graphs creating smart, reactive AI agents. No hidden magic. No framework gymnastics. Just clear logic and complete control.
What else can we build?
Pocket Flow isn't limited to search agents. Build everything you love—Multi-Agents, Workflows, RAG systems, Map-Reduce operations, Streaming, Supervisors, Chat Memory, Model Context Protocol, and more—all with the same elegant simplicity. Each implementation follows the same pattern: a few hundred lines of code built on first principles, with our minimal 100-line framework as the foundation.
No unnecessary abstraction. No bloat. Instead of trying to understand a gigantic framework with hundreds of thousands of files, Pocket Flow gives you the fundamentals so you can build your own understanding from the ground up. Find complete tutorials for all these implementations in the Pocket Flow GitHub repository and explore our cookbooks to get started.
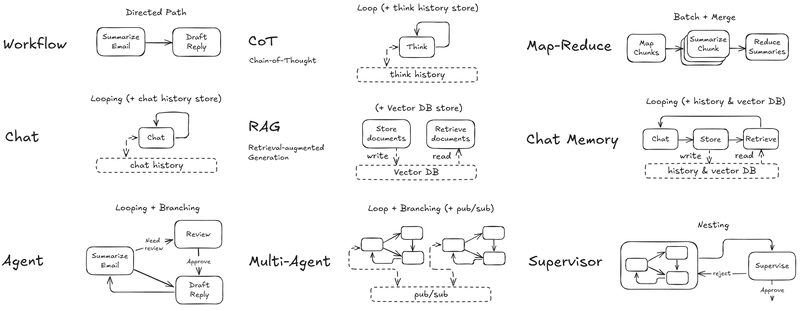
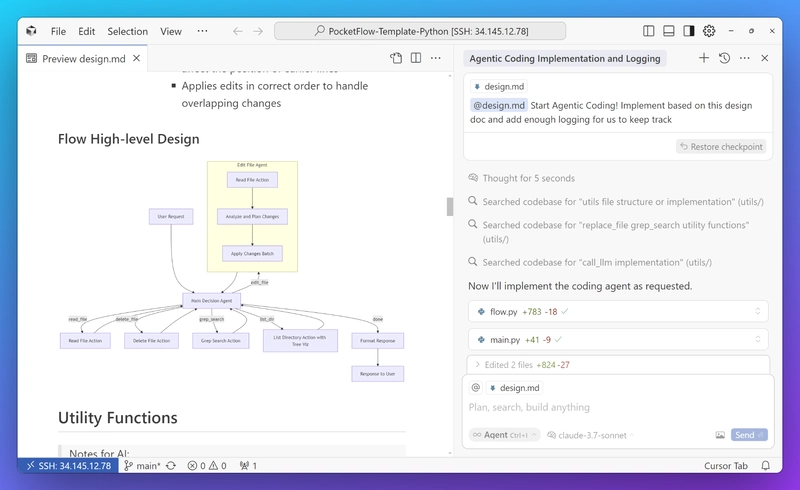
Future Vision of Pocket Flow: Agentic Coding
The true power of Pocket Flow extends beyond its minimalist design. Its most revolutionary aspect is enabling Agentic Coding - a new way of programming where AI assistants help you build and modify AI applications.
What is Agentic Coding?
Agentic coding is simply the practice of working alongside AI to build software. Think of it like building a house - you're the architect with the vision and expertise, while the AI is your construction crew handling the detailed work:
- You focus on high-level design and strategic decisions (the human strength)
- The AI assistant handles implementation details and technical execution (the AI strength)
- You review and refine the results, guiding the process
This 10x productivity multiplier means you spend less time coding repetitive patterns and more time on creative problem-solving.

Teaching AI to Build LLM Applications
How do we teach AI to build powerful LLM applications? Previous frameworks took the wrong approach - they create hard coded wrappers for specific applications like summarization, tagging, and web scraping that end up bewildering both human developers and AI assistants alike.
Our solution is elegantly simple: Documentation as the second codebase! Instead of hard coded wrappers, vibe code them in documentation. Pocket Flow provides just 100 lines of core building blocks, paired with clear documentation that teaches how to combine these blocks into powerful applications. We simply provide examples and let AI agents implement solutions on the fly. This documentation-as-code approach allows AI assistants to:
- Master the fundamentals: Learn a small set of building blocks instead of drowning in complex wrappers
- Build customized solutions: Generate implementations perfectly tailored to specific application needs
- Focus on architecture: Think about system design rather than fighting framework limitations
We pass these "instruction manuals" directly to AI assistants as rule files (e.g., .cursorrules for cursor AI), giving them the knowledge to build sophisticated systems from simple components.
The future vision is even more exciting: as Pocket Flow patterns spread through the developer ecosystem, they'll eventually be absorbed into future LLMs' training data. At that point, we won't even need explicit documentation - AI assistants will intrinsically understand these principles, making LLM application development truly frictionless.
For deeper exploration of this approach, visit: Agentic Coding: The Most Fun Way to Build LLM Apps or check out my YouTube channel for more tutorials.
Conclusion: Simplicity Is the Ultimate Sophistication
Pocket Flow strips away the complexity, offering just what you need: 100 lines of code that model LLM applications as simple directed graphs. No bloat, no magic, just transparent logic and complete control.
If you're tired of framework gymnastics and want to build your understanding from the ground up, Pocket Flow's minimalist approach lets you create powerful agents today while preparing for the agentic coding revolution of tomorrow.
Join our Discord community to connect with other developers building with Pocket Flow!
Try Pocket Flow today and experience how 100 lines can replace hundreds of thousands! GitHub Repository | Documentation | TypeScript Version







