![T-Mobile says it didn't compromise its values to get FCC to approve fiber deal [UPDATED]](https://m-cdn.phonearena.com/images/article/169088-two/T-Mobile-says-it-didnt-compromise-its-values-to-get-FCC-to-approve-fiber-deal-UPDATED.jpg?#)











































![Nomad Goods Launches 15% Sitewide Sale for 48 Hours Only [Deal]](https://www.iclarified.com/images/news/96899/96899/96899-640.jpg)


![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)













































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

















































































































![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)



















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)























































































Less Is More: Why Retrieving Fewer Documents Can Improve AI Answers
Retrieval-Augmented Generation (RAG) is an approach to building AI systems that combines a language model with an external knowledge source. In simple terms, the AI first searches for relevant documents (like articles or webpages) related to a user’s query, and then uses those documents to generate a more accurate answer. This method has been celebrated […] The post Less Is More: Why Retrieving Fewer Documents Can Improve AI Answers appeared first on Unite.AI.


Retrieval-Augmented Generation (RAG) is an approach to building AI systems that combines a language model with an external knowledge source. In simple terms, the AI first searches for relevant documents (like articles or webpages) related to a user’s query, and then uses those documents to generate a more accurate answer. This method has been celebrated for helping large language models (LLMs) stay factual and reduce hallucinations by grounding their responses in real data.
Intuitively, one might think that the more documents an AI retrieves, the better informed its answer will be. However, recent research suggests a surprising twist: when it comes to feeding information to an AI, sometimes less is more.
Fewer Documents, Better Answers
A new study by researchers at the Hebrew University of Jerusalem explored how the number of documents given to a RAG system affects its performance. Crucially, they kept the total amount of text constant – meaning if fewer documents were provided, those documents were slightly expanded to fill the same length as many documents would. This way, any performance differences could be attributed to the quantity of documents rather than simply having a shorter input.
The researchers used a question-answering dataset (MuSiQue) with trivia questions, each originally paired with 20 Wikipedia paragraphs (only a few of which actually contain the answer, with the rest being distractors). By trimming the number of documents from 20 down to just the 2–4 truly relevant ones – and padding those with a bit of extra context to maintain a consistent length – they created scenarios where the AI had fewer pieces of material to consider, but still roughly the same total words to read.
The results were striking. In most cases, the AI models answered more accurately when they were given fewer documents rather than the full set. Performance improved significantly – in some instances by up to 10% in accuracy (F1 score) when the system used only the handful of supporting documents instead of a large collection. This counterintuitive boost was observed across several different open-source language models, including variants of Meta’s Llama and others, indicating that the phenomenon is not tied to a single AI model.
One model (Qwen-2) was a notable exception that handled multiple documents without a drop in score, but almost all the tested models performed better with fewer documents overall. In other words, adding more reference material beyond the key relevant pieces actually hurt their performance more often than it helped.
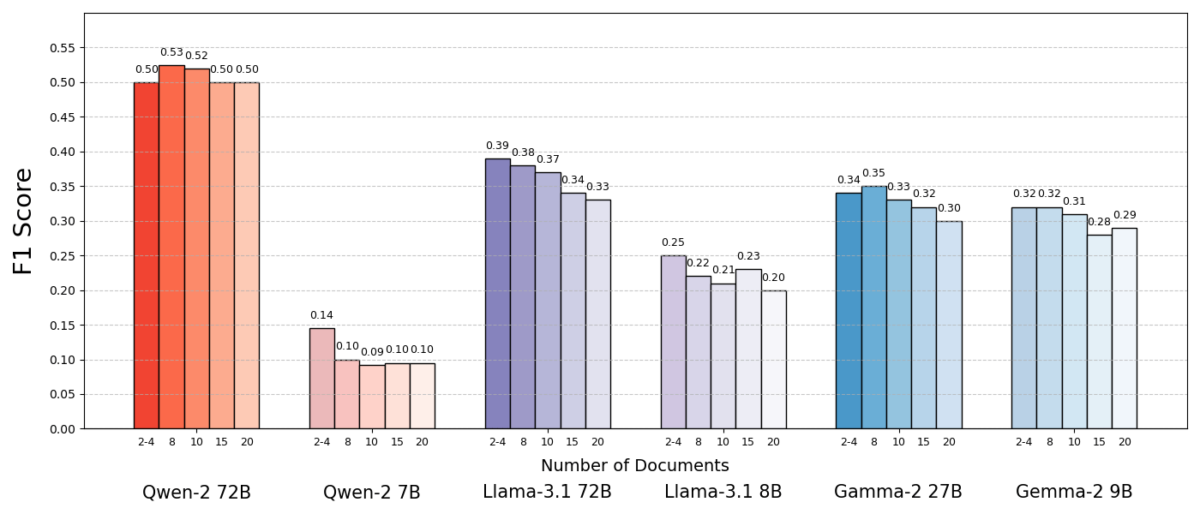
Source: Levy et al.
Why is this such a surprise? Typically, RAG systems are designed under the assumption that retrieving a broader swath of information can only help the AI – after all, if the answer isn’t in the first few documents, it might be in the tenth or twentieth.
This study flips that script, demonstrating that indiscriminately piling on extra documents can backfire. Even when the total text length was held constant, the mere presence of many different documents (each with their own context and quirks) made the question-answering task more challenging for the AI. It appears that beyond a certain point, each additional document introduced more noise than signal, confusing the model and impairing its ability to extract the correct answer.
Why Less Can Be More in RAG
This “less is more” result makes sense once we consider how AI language models process information. When an AI is given only the most relevant documents, the context it sees is focused and free of distractions, much like a student who has been handed just the right pages to study.
In the study, models performed significantly better when given only the supporting documents, with irrelevant material removed. The remaining context was not only shorter but also cleaner – it contained facts that directly pointed to the answer and nothing else. With fewer documents to juggle, the model could devote its full attention to the pertinent information, making it less likely to get sidetracked or confused.
On the other hand, when many documents were retrieved, the AI had to sift through a mix of relevant and irrelevant content. Often these extra documents were “similar but unrelated” – they might share a topic or keywords with the query but not actually contain the answer. Such content can mislead the model. The AI might waste effort trying to connect dots across documents that don’t actually lead to a correct answer, or worse, it might merge information from multiple sources incorrectly. This increases the risk of hallucinations – instances where the AI generates an answer that sounds plausible but is not grounded in any single source.
In essence, feeding too many documents to the model can dilute the useful information and introduce conflicting details, making it harder for the AI to decide what’s true.
Interestingly, the researchers found that if the extra documents were obviously irrelevant (for example, random unrelated text), the models were better at ignoring them. The real trouble comes from distracting data that looks relevant: when all the retrieved texts are on similar topics, the AI assumes it should use all of them, and it may struggle to tell which details are actually important. This aligns with the study’s observation that random distractors caused less confusion than realistic distractors in the input. The AI can filter out blatant nonsense, but subtly off-topic information is a slick trap – it sneaks in under the guise of relevance and derails the answer. By reducing the number of documents to only the truly necessary ones, we avoid setting these traps in the first place.
There’s also a practical benefit: retrieving and processing fewer documents lowers the computational overhead for a RAG system. Every document that gets pulled in has to be analyzed (embedded, read, and attended to by the model), which uses time and computing resources. Eliminating superfluous documents makes the system more efficient – it can find answers faster and at lower cost. In scenarios where accuracy improved by focusing on fewer sources, we get a win-win: better answers and a leaner, more efficient process.

Source: Levy et al.
Rethinking RAG: Future Directions
This new evidence that quality often beats quantity in retrieval has important implications for the future of AI systems that rely on external knowledge. It suggests that designers of RAG systems should prioritize smart filtering and ranking of documents over sheer volume. Instead of fetching 100 possible passages and hoping the answer is buried in there somewhere, it may be wiser to fetch only the top few highly relevant ones.
The study’s authors emphasize the need for retrieval methods to “strike a balance between relevance and diversity” in the information they supply to a model. In other words, we want to provide enough coverage of the topic to answer the question, but not so much that the core facts are drowned in a sea of extraneous text.
Moving forward, researchers are likely to explore techniques that help AI models handle multiple documents more gracefully. One approach is to develop better retriever systems or re-rankers that can identify which documents truly add value and which ones only introduce conflict. Another angle is improving the language models themselves: if one model (like Qwen-2) managed to cope with many documents without losing accuracy, examining how it was trained or structured could offer clues for making other models more robust. Perhaps future large language models will incorporate mechanisms to recognize when two sources are saying the same thing (or contradicting each other) and focus accordingly. The goal would be to enable models to utilize a rich variety of sources without falling prey to confusion – effectively getting the best of both worlds (breadth of information and clarity of focus).
It’s also worth noting that as AI systems gain larger context windows (the ability to read more text at once), simply dumping more data into the prompt isn’t a silver bullet. Bigger context does not automatically mean better comprehension. This study shows that even if an AI can technically read 50 pages at a time, giving it 50 pages of mixed-quality information may not yield a good result. The model still benefits from having curated, relevant content to work with, rather than an indiscriminate dump. In fact, intelligent retrieval may become even more crucial in the era of giant context windows – to ensure the extra capacity is used for valuable knowledge rather than noise.
The findings from “More Documents, Same Length” (the aptly titled paper) encourage a re-examination of our assumptions in AI research. Sometimes, feeding an AI all the data we have is not as effective as we think. By focusing on the most relevant pieces of information, we not only improve the accuracy of AI-generated answers but also make the systems more efficient and easier to trust. It’s a counterintuitive lesson, but one with exciting ramifications: future RAG systems might be both smarter and leaner by carefully choosing fewer, better documents to retrieve.
The post Less Is More: Why Retrieving Fewer Documents Can Improve AI Answers appeared first on Unite.AI.