_NicoElNino_Alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)































































![At Least Three iPhone 17 Models to Feature 12GB RAM [Kuo]](https://www.iclarified.com/images/news/97122/97122/97122-640.jpg)
![Dummy Models Showcase 'Unbelievably' Thin iPhone 17 Air Design [Images]](https://www.iclarified.com/images/news/97114/97114/97114-640.jpg)









































































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)























































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)























































































































![API design for precomputation cache [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
















































































































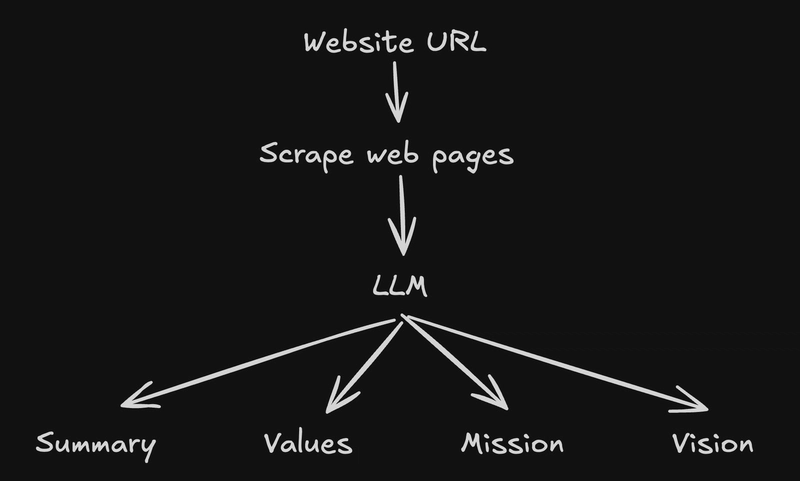
LLM Agent Architecture for Scalable Company Summaries
At RiddleStory, we're building an online onboarding platform that helps new hires get up to speed faster and feel more connected from day one. But to create meaningful onboarding experiences, we need to deeply understand the companies we're working with. We need to know their values, culture, tone, and mission. That's why we built a Company Profile Summarizer powered by LLMs. Here's how the idea evolved and what we learned along the way. The Idea Given a company's website URL, we wanted to scrape and extract the most important elements that define the company's identity. The Approach Naive Approach: Simple LLM summarization Our first idea was straightforward: scrape all the URLs we could find on a company's website (using recursive crawling), combine the content, and pass everything to GPT-4o in a single prompt. It kind of worked. But not really. We ran into 2 issues: Token limits Many sites have dozens of pages, and GPT quickly hits the limit. Quality Even when it stayed within the limit, the summarization and other outputs were too shallow. With so much context, the LLM struggled to produce high quality results. Page by Page Approach Our second approach produces better output. Each scraped page was summarized, so we have multiple page summaries. We then combined those summaries to generate the final output, including mission, vision, values, and more. However, there are still some issues: Token limits Again, even with smaller summaries page by page, generating the final summary may also reach token limit. Quality LLM tends to hallucinates when given too much context. Thus the output may not be too accurate. This approach works, and we thought it's production ready. But we knew there had to be a smarter way. RAG Powered Agent To solve the token limit and quality problem, we moved towards a Retrieval Augmented Generation (RAG) approach: Scrape & Chunk the Website We crawled the company's website and broke down the content into smaller chunks, in this case per 1 page. Each chunk was stored with metadata like the source URL and its page context. Embed the Content Each chunk was turned into a vector using OpenAI embeddings and stored in a vector database (MongoDB in our case). This allows us to later search semantically, not just by keyword. Ask Only What's Needed When we need to summarize, say, the company's mission or values, we run a vector search to retrieve only the most relevant chunks. These chunks are passed into a specialized GPT prompt that focuses on extracting just that one piece of information. This approach dramatically improved the output. It was more focused, accurate, and easier to scale. The LLM had less to think about. And the output was more accurate. . . . . . But again, even though this approach is far more efficient and accurate than before, there are some issues: Inaccurate scraped web pages The scraped web pages were not accurate. Given the website url, we recursively scrape the web pages. Yes we can get all dozens if not hundreds of web pages from the url, but it isn't worth the cost to scrape hundreds of web pages blindly while we may not need all those web pages. So we decided to cap the scraped urls up to 50 pages. Static search query for searching Vector DB The vector search used fixed queries. For example, we'd always use the same phrase like "Company Values", regardless of the context. Smart LLM Agent Approach This is where things get really interesting. Instead of manually controlling the flow or relying on static queries, we decided to build an autonomous agent using the ReAct pattern (combining reasoning and action). The idea: give the agent a clear goal, equip it with the right tools, and let it figure out the rest. This is a smarter approach. Make an agent, give it a ReAct prompt, give it some tools. Then simply ask what you want it to do. It will do all the research for you, and generate the outcome for you. Here's how it works: Ask the Agent with an Objective For example: "Summarize this company's mission, vision, values, etc" Let the Agent Plan The agent decides what it needs to find first. Maybe it needs to scrape specific pages, maybe it needs to search the vector DB, maybe both. Tool Driven It uses available tools like Web Scraper, Vector Search, and Web Search. Reasoning Loop The agent uses a ReAct loop: Thought → Action → Observation → Repeat until it's confident in the output. Final Output Once done, the agent produces structured summaries for mission, vision, values, culture, etc just like a human researcher would. This approach gave us maximum flexibility and minimal manual tweaking. It also unlocked the potential for scaling. We can now give it different objectives for different use cases, and it will adapt accordingly. Conclusion There are so many ways to utilize LLM, from Naive approach to a more
At RiddleStory, we're building an online onboarding platform that helps new hires get up to speed faster and feel more connected from day one. But to create meaningful onboarding experiences, we need to deeply understand the companies we're working with. We need to know their values, culture, tone, and mission.
That's why we built a Company Profile Summarizer powered by LLMs. Here's how the idea evolved and what we learned along the way.
The Idea
Given a company's website URL, we wanted to scrape and extract the most important elements that define the company's identity.
The Approach
Naive Approach: Simple LLM summarization
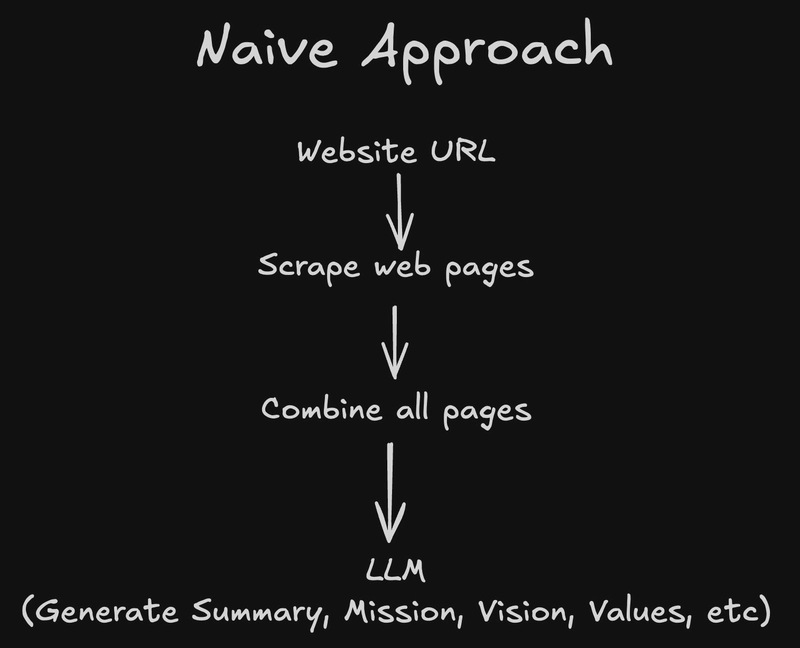
Our first idea was straightforward: scrape all the URLs we could find on a company's website (using recursive crawling), combine the content, and pass everything to GPT-4o in a single prompt.
It kind of worked. But not really. We ran into 2 issues:
- Token limits
Many sites have dozens of pages, and GPT quickly hits the limit.
- Quality
Even when it stayed within the limit, the summarization and other outputs were too shallow. With so much context, the LLM struggled to produce high quality results.
Page by Page Approach

Our second approach produces better output. Each scraped page was summarized, so we have multiple page summaries. We then combined those summaries to generate the final output, including mission, vision, values, and more.
However, there are still some issues:
- Token limits
Again, even with smaller summaries page by page, generating the final summary may also reach token limit.
- Quality
LLM tends to hallucinates when given too much context. Thus the output may not be too accurate.
This approach works, and we thought it's production ready. But we knew there had to be a smarter way.
RAG Powered Agent
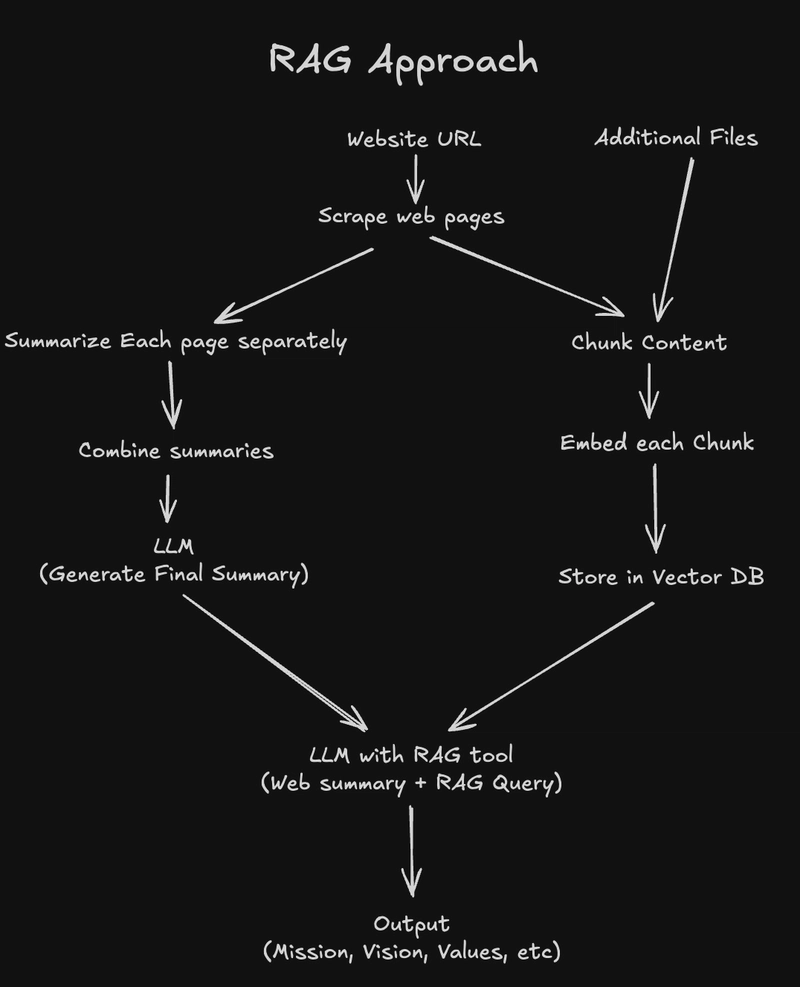
To solve the token limit and quality problem, we moved towards a Retrieval Augmented Generation (RAG) approach:
- Scrape & Chunk the Website
We crawled the company's website and broke down the content into smaller chunks, in this case per 1 page. Each chunk was stored with metadata like the source URL and its page context.
- Embed the Content
Each chunk was turned into a vector using OpenAI embeddings and stored in a vector database (MongoDB in our case). This allows us to later search semantically, not just by keyword.
- Ask Only What's Needed
When we need to summarize, say, the company's mission or values, we run a vector search to retrieve only the most relevant chunks. These chunks are passed into a specialized GPT prompt that focuses on extracting just that one piece of information.
This approach dramatically improved the output. It was more focused, accurate, and easier to scale. The LLM had less to think about. And the output was more accurate.
. . . . .
But again, even though this approach is far more efficient and accurate than before, there are some issues:
- Inaccurate scraped web pages
The scraped web pages were not accurate. Given the website url, we recursively scrape the web pages. Yes we can get all dozens if not hundreds of web pages from the url, but it isn't worth the cost to scrape hundreds of web pages blindly while we may not need all those web pages. So we decided to cap the scraped urls up to 50 pages.
- Static search query for searching Vector DB
The vector search used fixed queries. For example, we'd always use the same phrase like "Company Values", regardless of the context.
Smart LLM Agent Approach
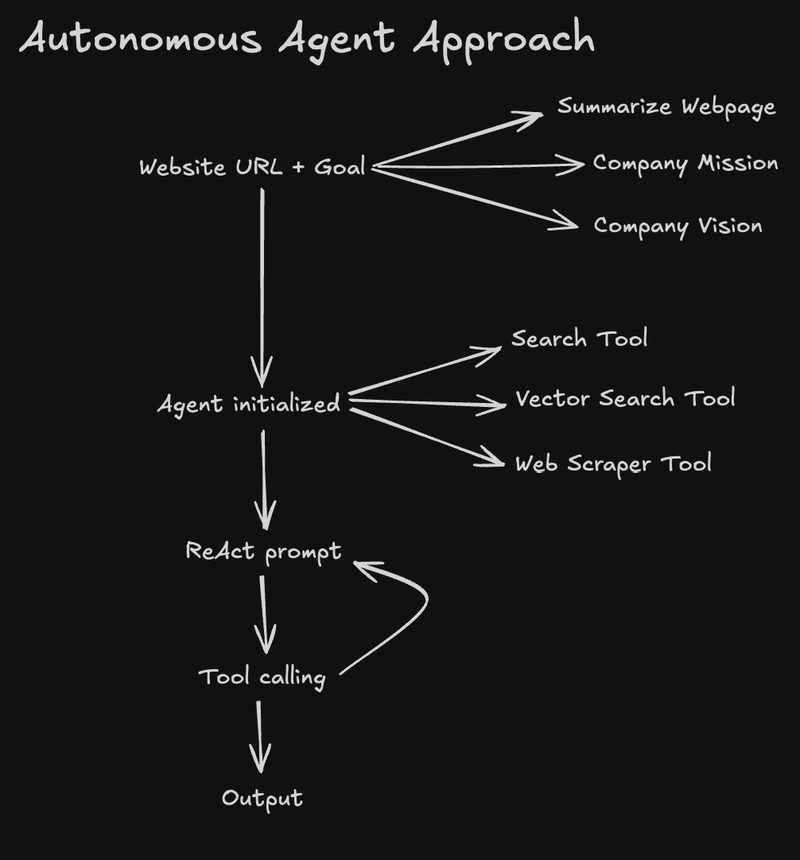
This is where things get really interesting.
Instead of manually controlling the flow or relying on static queries, we decided to build an autonomous agent using the ReAct pattern (combining reasoning and action). The idea: give the agent a clear goal, equip it with the right tools, and let it figure out the rest.
This is a smarter approach. Make an agent, give it a ReAct prompt, give it some tools. Then simply ask what you want it to do. It will do all the research for you, and generate the outcome for you.
Here's how it works:
- Ask the Agent with an Objective
For example: "Summarize this company's mission, vision, values, etc"
- Let the Agent Plan
The agent decides what it needs to find first. Maybe it needs to scrape specific pages, maybe it needs to search the vector DB, maybe both.
- Tool Driven
It uses available tools like Web Scraper, Vector Search, and Web Search.
- Reasoning Loop
The agent uses a ReAct loop:
Thought → Action → Observation → Repeat
until it's confident in the output.
- Final Output
Once done, the agent produces structured summaries for mission, vision, values, culture, etc just like a human researcher would.
This approach gave us maximum flexibility and minimal manual tweaking. It also unlocked the potential for scaling. We can now give it different objectives for different use cases, and it will adapt accordingly.
Conclusion
There are so many ways to utilize LLM, from Naive approach to a more Smart and Advanced Agentic flow.
Each iteration taught us something:
- The naive approach was quick build, but the output was not good
- The page-by-page approach improves structure but still struggles with scale
- The RAG based flow brings precision, relevance, and performance
- The autonomous agent was more flexible. It can dynamically deciding what to look for and how to get it
In the end, we learned that using LLMs well isn't just about the model.
It's about how you guide it. What you feed it, what tools it has, and what goal it's trying to reach.
Smarter people than me had done research and written papers about this. Check it out: