







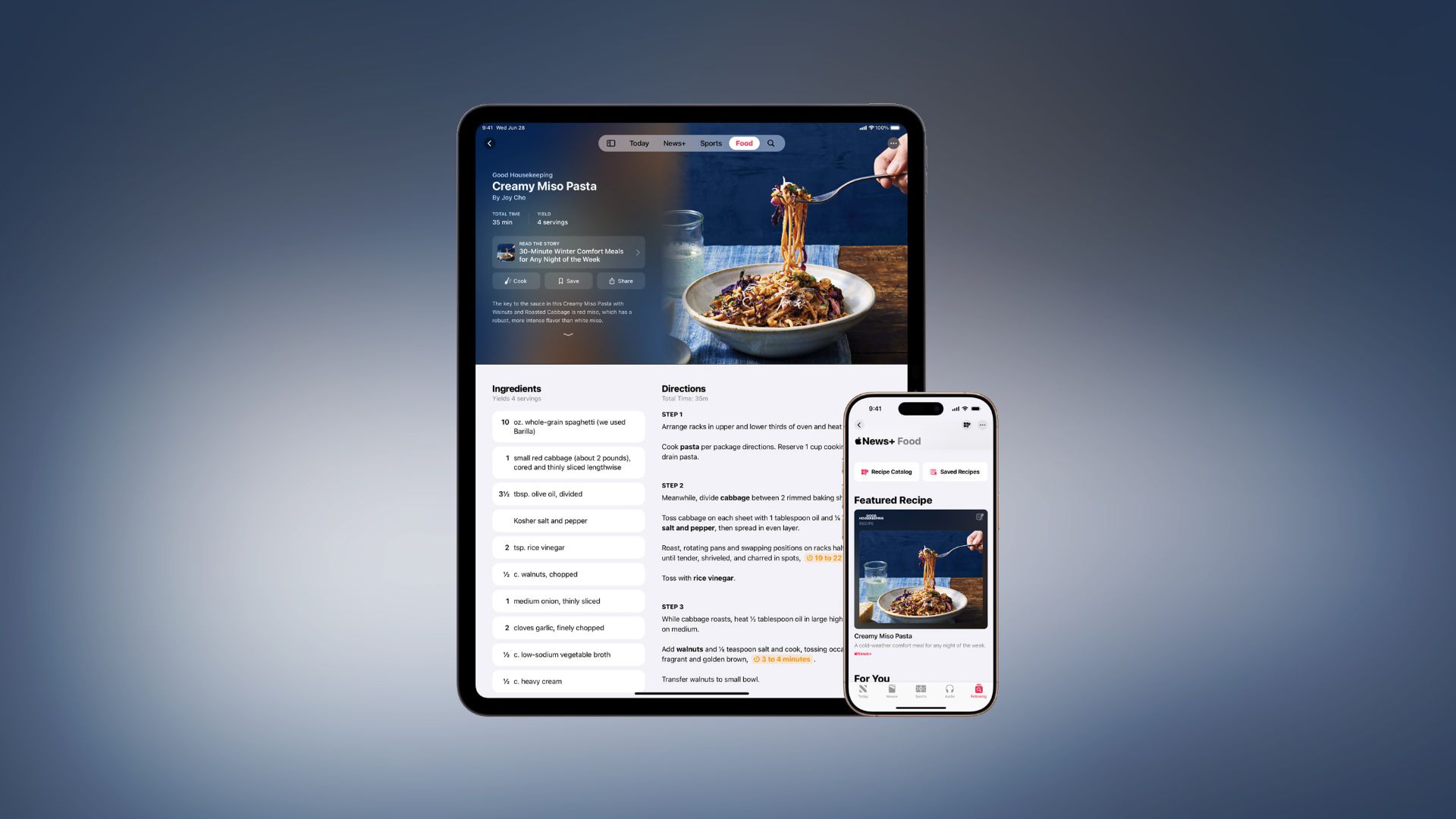


















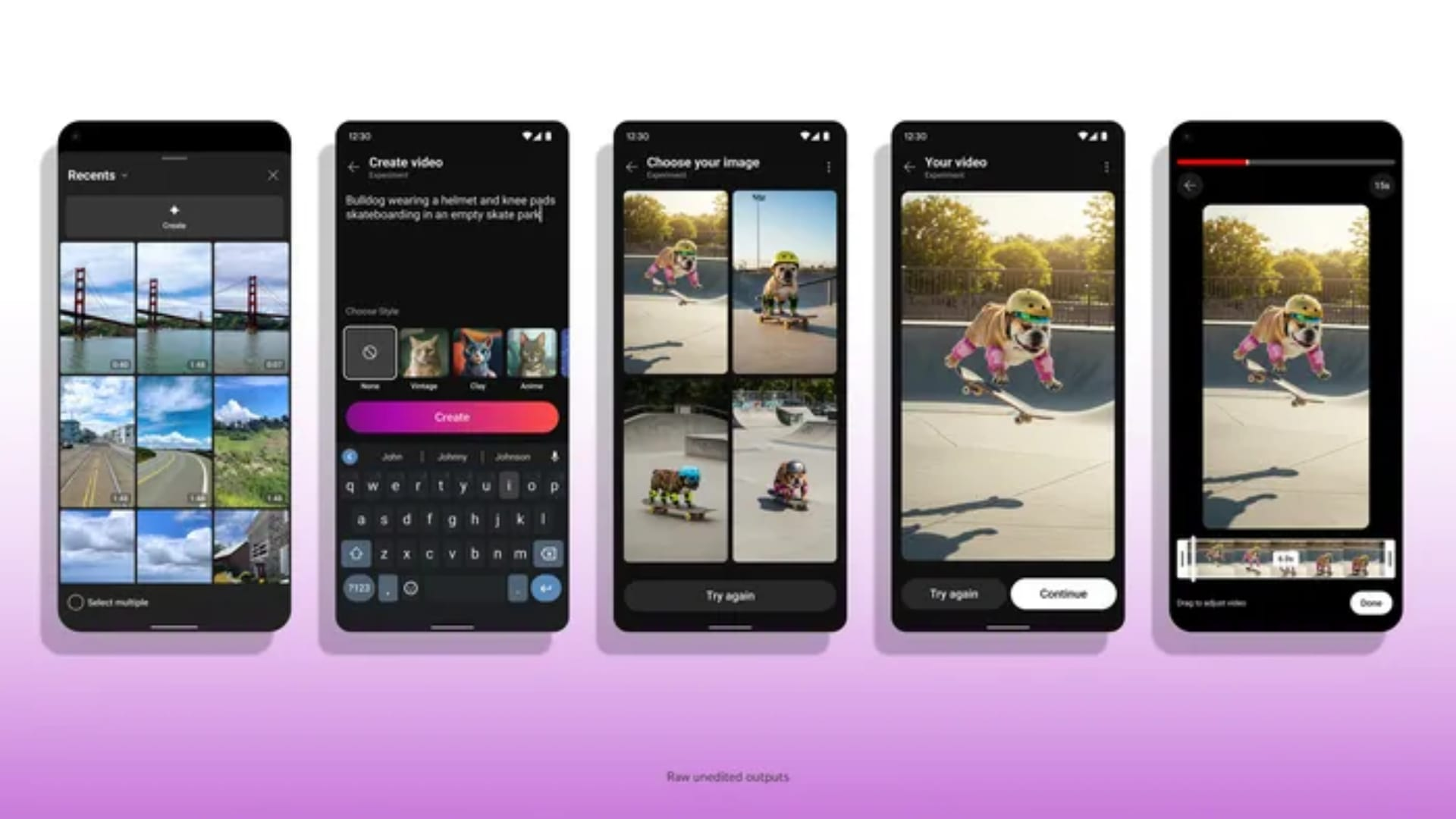












![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)

![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
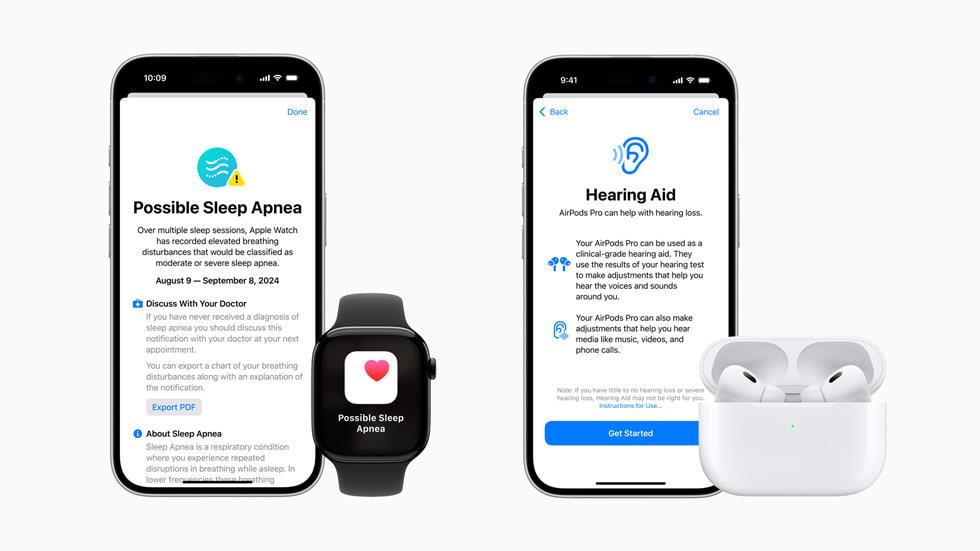
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)











![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













-xl-xl.jpg)

















































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)















































































































![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)



























-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















































Utility to split the HTML content in Ck Editor plugin without breaking the hierarchy
Introduction I was working in a React project that uses Ck Editor as a Editor plugin. And our functionality is to generate a PDF document by processing the content in the editor. And we were using Aspose for that purpose to convert Html to Word to PDF. Later we got a new requirement to implement the page break utility of Ck Editor plugin. It was a very simple step to include Page break plugin in Ck Editor as it was one of the inbuilt utility and we just have to allow that plugin. But the toughest part was to process this page break while generating the word document using Aspose. Expectation is, when there is a page break, word document has to split the content into 2 pages without breaking the hierarchy and the styles applied on parent component. But, when we tried to generate the word document using Aspose, The styles applied in parent were not reflecting and the styles applied to particular class which is dependent on parent class were also not applied in the second page after split. Problem: In order to fix this issue, we have to split the HTML into 2 parts based on the page break element as a separator, without breaking the hierarchy and classes. But there were no utility package available in npm for splitting the HTML. Also there were no proper solution for this in any of the blog sites as well as Chat GPT. Problem Statement Split the given HTML element based on the Separator Element without breaking the hierarchy Solution: This Solution has 3 different parts. Whenever it identifies a page break element, then store the hierarchy and split the elements If it finds a list item, then store the order of list to maintain the hierarchy After the page break is identified inside the list, use this list order hierarchy for maintaining the order for the remaining elements in the list. const defineNumbering = (element: Node, startInd: number[]) => { let ind = startInd.length - 1; const clonedInd = [...startInd]; clonedInd[ind]++; while (ind >= 0) { if (["UL", "OL"].includes(element.nodeName)) { (element as Element).setAttribute("start", `${clonedInd[ind]}`); ind--; } if (element.parentNode) element = element.parentNode; } while (element.lastChild) element = element.lastChild; return element; }; const getRoot = (element: Node) => { let root = element; while (root.parentElement) { root = root.parentElement; } return root; }; const clonedRoot = (element: Node) => { let clonedRoot = getRoot(element).cloneNode(true); while (clonedRoot.lastChild) clonedRoot = clonedRoot.lastChild; return clonedRoot; }; const splitEl = (element: Element | null, selector: string) => { const clonedEl = element?.cloneNode(true) as Element; const seperators = clonedEl.querySelectorAll(selector); let sepInd = 0; const splitVals: Node[] = []; let tempEl = clonedEl.cloneNode(false); let hierarchyEl: Node; let temp2: Node; let resetTemp2 = false; let listIndex: number[] = []; let activeListIndex: number; const processChild = (childEl: ChildNode, hierarchy: Node, initial: Node) => { let childHierarchy = clonedRoot(hierarchy); temp2 = clonedRoot(initial); childEl.childNodes.forEach((nestedChild, index) => { if (nestedChild.nodeName === "LI") listIndex[activeListIndex]++; if (sepInd === seperators.length) { if (["OL", "UL"].includes(nestedChild.nodeName)) { listIndex[activeListIndex]--; temp2 = defineNumbering(clonedRoot(childHierarchy), listIndex); } temp2.appendChild(nestedChild.cloneNode(true)); } else if ( nestedChild === seperators[sepInd] || (nestedChild.childNodes.length === 1 && nestedChild.firstChild === seperators[sepInd]) ) { if (index === childEl.childNodes.length - 1) resetTemp2 = true; else if (index === 0 && temp2.parentNode) { const removeChild2 = temp2; temp2 = temp2.parentNode; temp2.removeChild(removeChild2); listIndex[activeListIndex]--; } tempEl.appendChild(getRoot(temp2).cloneNode(true)); temp2 = defineNumbering(clonedRoot(childHierarchy), listIndex); splitVals.push(tempEl); sepInd++; tempEl = clonedEl.cloneNode(false); } else if (nestedChild.contains(seperators[sepInd])) { childHierarchy.appendChild(nestedChild.cloneNode(false)); childHierarchy = childHierarchy.lastChild ?? childHierarchy; temp2.appendChild(nestedChild.cloneNode(false)); if (["OL", "UL"].includes(nestedChild.nodeName)) { const initialNumber = (nestedChild as Element).getAttribute("start"); listIndex.push(initialNumber ? parseInt(initialNumber) : 0); activeListIndex++; } processChild(nestedChild, childHierarchy, temp2); if (childHierarchy.parentNode && temp2.parentNode) { const tempChild = childHierarchy; childHierarchy = childHierarchy.parentNode;

Introduction
I was working in a React project that uses Ck Editor as a Editor plugin. And our functionality is to generate a PDF document by processing the content in the editor. And we were using Aspose for that purpose to convert Html to Word to PDF.
Later we got a new requirement to implement the page break utility of Ck Editor plugin. It was a very simple step to include Page break plugin in Ck Editor as it was one of the inbuilt utility and we just have to allow that plugin.
But the toughest part was to process this page break while generating the word document using Aspose. Expectation is, when there is a page break, word document has to split the content into 2 pages without breaking the hierarchy and the styles applied on parent component. But, when we tried to generate the word document using Aspose, The styles applied in parent were not reflecting and the styles applied to particular class which is dependent on parent class were also not applied in the second page after split.
Problem:
In order to fix this issue, we have to split the HTML into 2 parts based on the page break element as a separator, without breaking the hierarchy and classes. But there were no utility package available in npm for splitting the HTML. Also there were no proper solution for this in any of the blog sites as well as Chat GPT.
Problem Statement
Split the given HTML element based on the Separator Element without breaking the hierarchy
Solution:
This Solution has 3 different parts.
Whenever it identifies a page break element, then store the hierarchy and split the elements
If it finds a list item, then store the order of list to maintain the hierarchy
After the page break is identified inside the list, use this list order hierarchy for maintaining the order for the remaining elements in the list.
const defineNumbering = (element: Node, startInd: number[]) => {
let ind = startInd.length - 1;
const clonedInd = [...startInd];
clonedInd[ind]++;
while (ind >= 0) {
if (["UL", "OL"].includes(element.nodeName)) {
(element as Element).setAttribute("start", `${clonedInd[ind]}`);
ind--;
}
if (element.parentNode) element = element.parentNode;
}
while (element.lastChild) element = element.lastChild;
return element;
};
const getRoot = (element: Node) => {
let root = element;
while (root.parentElement) {
root = root.parentElement;
}
return root;
};
const clonedRoot = (element: Node) => {
let clonedRoot = getRoot(element).cloneNode(true);
while (clonedRoot.lastChild) clonedRoot = clonedRoot.lastChild;
return clonedRoot;
};
const splitEl = (element: Element | null, selector: string) => {
const clonedEl = element?.cloneNode(true) as Element;
const seperators = clonedEl.querySelectorAll(selector);
let sepInd = 0;
const splitVals: Node[] = [];
let tempEl = clonedEl.cloneNode(false);
let hierarchyEl: Node;
let temp2: Node;
let resetTemp2 = false;
let listIndex: number[] = [];
let activeListIndex: number;
const processChild = (childEl: ChildNode, hierarchy: Node, initial: Node) => {
let childHierarchy = clonedRoot(hierarchy);
temp2 = clonedRoot(initial);
childEl.childNodes.forEach((nestedChild, index) => {
if (nestedChild.nodeName === "LI") listIndex[activeListIndex]++;
if (sepInd === seperators.length) {
if (["OL", "UL"].includes(nestedChild.nodeName)) {
listIndex[activeListIndex]--;
temp2 = defineNumbering(clonedRoot(childHierarchy), listIndex);
}
temp2.appendChild(nestedChild.cloneNode(true));
} else if (
nestedChild === seperators[sepInd] ||
(nestedChild.childNodes.length === 1 &&
nestedChild.firstChild === seperators[sepInd])
) {
if (index === childEl.childNodes.length - 1) resetTemp2 = true;
else if (index === 0 && temp2.parentNode) {
const removeChild2 = temp2;
temp2 = temp2.parentNode;
temp2.removeChild(removeChild2);
listIndex[activeListIndex]--;
}
tempEl.appendChild(getRoot(temp2).cloneNode(true));
temp2 = defineNumbering(clonedRoot(childHierarchy), listIndex);
splitVals.push(tempEl);
sepInd++;
tempEl = clonedEl.cloneNode(false);
} else if (nestedChild.contains(seperators[sepInd])) {
childHierarchy.appendChild(nestedChild.cloneNode(false));
childHierarchy = childHierarchy.lastChild ?? childHierarchy;
temp2.appendChild(nestedChild.cloneNode(false));
if (["OL", "UL"].includes(nestedChild.nodeName)) {
const initialNumber = (nestedChild as Element).getAttribute("start");
listIndex.push(initialNumber ? parseInt(initialNumber) : 0);
activeListIndex++;
}
processChild(nestedChild, childHierarchy, temp2);
if (childHierarchy.parentNode && temp2.parentNode) {
const tempChild = childHierarchy;
childHierarchy = childHierarchy.parentNode;
if (
childHierarchy.nodeName === "LI" &&
["OL", "UL"].includes(tempChild.nodeName)
) {
listIndex.pop();
activeListIndex--;
}
childHierarchy.removeChild(tempChild);
}
if (resetTemp2 && temp2.parentNode) {
resetTemp2 = false;
const tempChild2 = temp2;
temp2 = temp2.parentNode;
temp2.removeChild(tempChild2);
} else temp2 = temp2.parentNode || temp2;
} else {
temp2.appendChild(nestedChild.cloneNode(true));
}
});
};
clonedEl.childNodes.forEach((child) => {
if (sepInd === seperators.length) {
tempEl.appendChild(child.cloneNode(true));
} else if (child === seperators[sepInd]) {
splitVals.push(tempEl);
tempEl = clonedEl.cloneNode(false);
sepInd++;
} else if (
child.contains(seperators[sepInd]) &&
["OL", "UL"].includes(child.nodeName)
) {
const initialNumber = (child as Element).getAttribute("start");
listIndex.push(initialNumber ? parseInt(initialNumber) : 0);
activeListIndex = 0;
hierarchyEl = child.cloneNode(false);
processChild(child, hierarchyEl, hierarchyEl);
tempEl.appendChild(getRoot(temp2));
} else {
tempEl.appendChild(child.cloneNode(true));
}
listIndex = [];
activeListIndex = -1;
});
splitVals.push(tempEl);
return splitVals
.map((val) => (val as Element).outerHTML)
.join("");
};
export { splitEl };
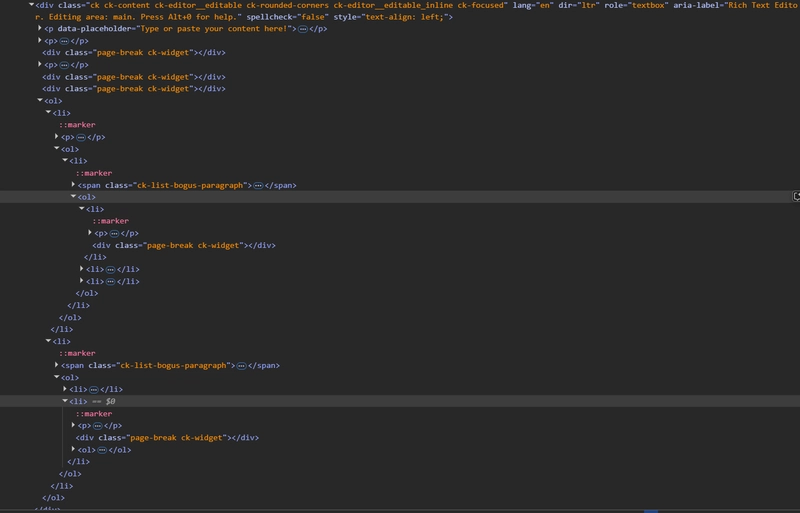
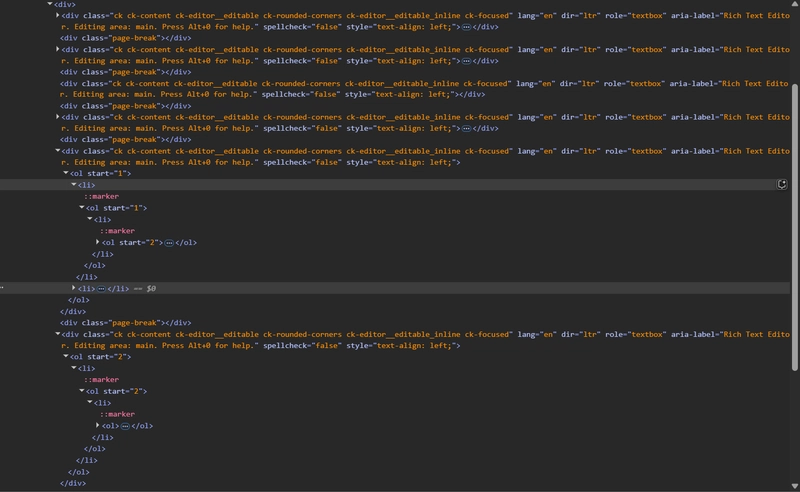
In this Above Example, The Lines in between the texts, resembles the page break. And below is the processing done in the input html
When the page break is identified between paragraphs, it simply splits the html.
When there are multiple page breaks one below the other, it creates an empty container in between the page breaks.
When there is a page break inside the lists, it maintains the order and continues the same list numbering after the split. For instance, we have 1. 1. 1. (3 levels) before the page break, and after the split, the content continues from 1. 1. 2 till 1. 1. 3. Hence in the output html, you can see that the list starts from 1. 1. 2 after the page break.
Also, before the last page break, after the 2nd list item there is a page break and after the page break, we don’t have a 3rd list item, instead we have a sub list. so the hierarchy should flow like 2. 2. 1.
Below is the elements structure for Input and Output HTML.