


















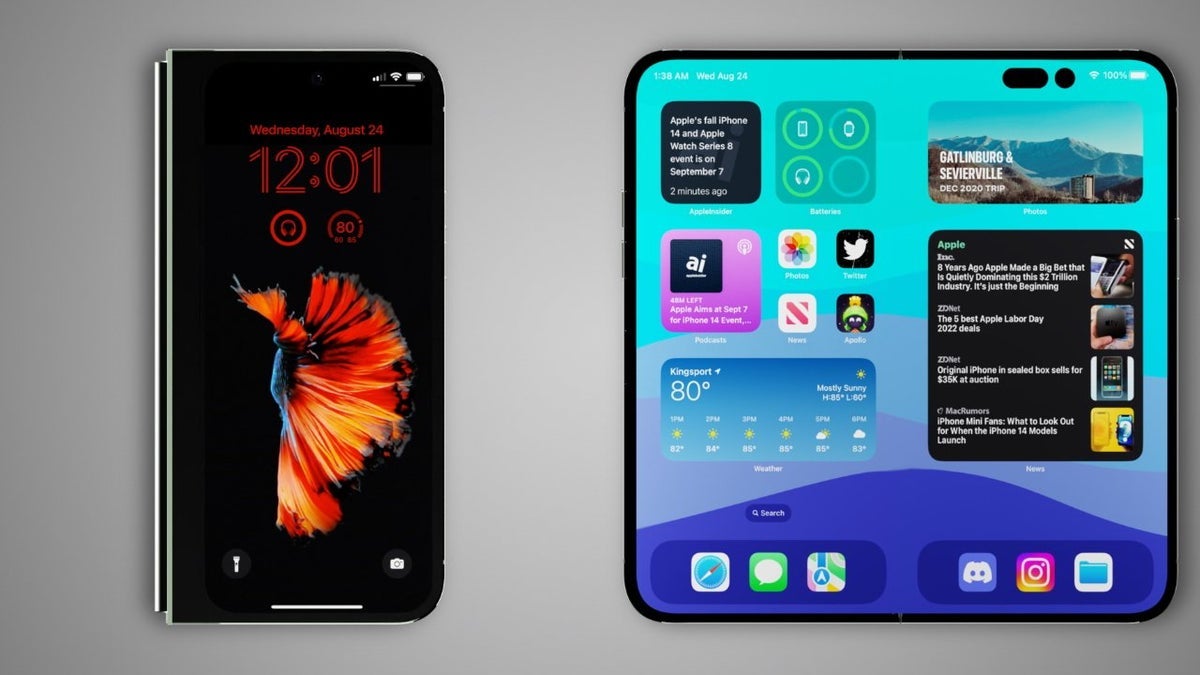







































![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)

![Apple Reorganizes Executive Team to Rescue Siri [Report]](https://www.iclarified.com/images/news/96777/96777/96777-640.jpg)








































































































_Federico_Caputo_Alamy.jpg?#)


































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)































































































































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


















.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)











![Release: Rendering Ranger: R² [Rewind]](https://images-3.gog-statics.com/48a9164e1467b7da3bb4ce148b93c2f92cac99bdaa9f96b00268427e797fc455.jpg)











































A Step-by-Step Guide to Building a Semantic Search Engine with Sentence Transformers, FAISS, and all-MiniLM-L6-v2
Semantic search goes beyond traditional keyword matching by understanding the contextual meaning of search queries. Instead of simply matching exact words, semantic search systems capture the intent and contextual definition of the query and return relevant results even when they don’t contain the same keywords. In this tutorial, we’ll implement a semantic search system using […] The post A Step-by-Step Guide to Building a Semantic Search Engine with Sentence Transformers, FAISS, and all-MiniLM-L6-v2 appeared first on MarkTechPost.



Semantic search goes beyond traditional keyword matching by understanding the contextual meaning of search queries. Instead of simply matching exact words, semantic search systems capture the intent and contextual definition of the query and return relevant results even when they don’t contain the same keywords.
In this tutorial, we’ll implement a semantic search system using Sentence Transformers, a powerful library built on top of Hugging Face’s Transformers that provides pre-trained models specifically optimized for generating sentence embeddings. These embeddings are numerical representations of text that capture semantic meaning, allowing us to find similar content through vector similarity. We’ll create a practical application: a semantic search engine for a collection of scientific abstracts that can answer research queries with relevant papers, even when the terminology differs between the query and relevant documents.
First, let’s install the necessary libraries in our Colab notebook:
!pip install sentence-transformers faiss-cpu numpy pandas matplotlib datasetsNow, let’s import the libraries we’ll need:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sentence_transformers import SentenceTransformer
import faiss
from typing import List, Dict, Tuple
import time
import re
import torchFor our demonstration, we’ll use a collection of scientific paper abstracts. Let’s create a small dataset of abstracts from various fields:
abstracts = [
{
"id": 1,
"title": "Deep Learning for Natural Language Processing",
"abstract": "This paper explores recent advances in deep learning models for natural language processing tasks. We review transformer architectures including BERT, GPT, and T5, and analyze their performance on various benchmarks including question answering, sentiment analysis, and text classification."
},
{
"id": 2,
"title": "Climate Change Impact on Marine Ecosystems",
"abstract": "Rising ocean temperatures and acidification are severely impacting coral reefs and marine biodiversity. This study presents data collected over a 10-year period, demonstrating accelerated decline in reef ecosystems and proposing conservation strategies to mitigate further damage."
},
{
"id": 3,
"title": "Advancements in mRNA Vaccine Technology",
"abstract": "The development of mRNA vaccines represents a breakthrough in immunization technology. This review discusses the mechanism of action, stability improvements, and clinical efficacy of mRNA platforms, with special attention to their rapid deployment during the COVID-19 pandemic."
},
{
"id": 4,
"title": "Quantum Computing Algorithms for Optimization Problems",
"abstract": "Quantum computing offers potential speedups for solving complex optimization problems. This paper presents quantum algorithms for combinatorial optimization and compares their theoretical performance with classical methods on problems including traveling salesman and maximum cut."
},
{
"id": 5,
"title": "Sustainable Urban Planning Frameworks",
"abstract": "This research proposes frameworks for sustainable urban development that integrate renewable energy systems, efficient public transportation networks, and green infrastructure. Case studies from five cities demonstrate reductions in carbon emissions and improvements in quality of life metrics."
},
{
"id": 6,
"title": "Neural Networks for Computer Vision",
"abstract": "Convolutional neural networks have revolutionized computer vision tasks. This paper examines recent architectural innovations including residual connections, attention mechanisms, and vision transformers, evaluating their performance on image classification, object detection, and segmentation benchmarks."
},
{
"id": 7,
"title": "Blockchain Applications in Supply Chain Management",
"abstract": "Blockchain technology enables transparent and secure tracking of goods throughout supply chains. This study analyzes implementations across food, pharmaceutical, and retail industries, quantifying improvements in traceability, reduction in counterfeit products, and enhanced consumer trust."
},
{
"id": 8,
"title": "Genetic Factors in Autoimmune Disorders",
"abstract": "This research identifies key genetic markers associated with increased susceptibility to autoimmune conditions. Through genome-wide association studies of 15,000 patients, we identified novel variants that influence immune system regulation and may serve as targets for personalized therapeutic approaches."
},
{
"id": 9,
"title": "Reinforcement Learning for Robotic Control Systems",
"abstract": "Deep reinforcement learning enables robots to learn complex manipulation tasks through trial and error. This paper presents a framework that combines model-based planning with policy gradient methods to achieve sample-efficient learning of dexterous manipulation skills."
},
{
"id": 10,
"title": "Microplastic Pollution in Freshwater Systems",
"abstract": "This study quantifies microplastic contamination across 30 freshwater lakes and rivers, identifying primary sources and transport mechanisms. Results indicate correlation between population density and contamination levels, with implications for water treatment policies and plastic waste management."
}
]
papers_df = pd.DataFrame(abstracts)
print(f"Dataset loaded with {len(papers_df)} scientific papers")
papers_df[["id", "title"]]Now we’ll load a pre-trained Sentence Transformer model from Hugging Face. We’ll use the all-MiniLM-L6-v2 model, which provides a good balance between performance and speed:
model_name = 'all-MiniLM-L6-v2'
model = SentenceTransformer(model_name)
print(f"Loaded model: {model_name}")Next, we’ll convert our text abstracts into dense vector embeddings:
documents = papers_df['abstract'].tolist()
document_embeddings = model.encode(documents, show_progress_bar=True)
print(f"Generated {len(document_embeddings)} embeddings with dimension {document_embeddings.shape[1]}")FAISS (Facebook AI Similarity Search) is a library for efficient similarity search. We’ll use it to index our document embeddings:
dimension = document_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(np.array(document_embeddings).astype('float32'))
print(f"Created FAISS index with {index.ntotal} vectors")Now let’s implement a function that takes a query, converts it to an embedding, and retrieves the most similar documents:
def semantic_search(query: str, top_k: int = 3) -> List[Dict]:
"""
Search for documents similar to query
Args:
query: Text to search for
top_k: Number of results to return
Returns:
List of dictionaries containing document info and similarity score
"""
query_embedding = model.encode([query])
distances, indices = index.search(np.array(query_embedding).astype('float32'), top_k)
results = []
for i, idx in enumerate(indices[0]):
results.append({
'id': papers_df.iloc[idx]['id'],
'title': papers_df.iloc[idx]['title'],
'abstract': papers_df.iloc[idx]['abstract'],
'similarity_score': 1 - distances[0][i] / 2
})
return resultsLet’s test our semantic search with various queries that demonstrate its ability to understand meaning beyond exact keywords:
test_queries = [
"How do transformers work in natural language processing?",
"What are the effects of global warming on ocean life?",
"Tell me about COVID vaccine development",
"Latest algorithms in quantum computing",
"How can cities reduce their carbon footprint?"
]
for query in test_queries:
print("\n" + "="*80)
print(f"Query: {query}")
print("="*80)
results = semantic_search(query, top_k=3)
for i, result in enumerate(results):
print(f"\nResult #{i+1} (Score: {result['similarity_score']:.4f}):")
print(f"Title: {result['title']}")
print(f"Abstract snippet: {result['abstract'][:150]}...")Let’s visualize the document embeddings to see how they cluster by topic:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(document_embeddings)
plt.figure(figsize=(12, 8))
plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1], s=100, alpha=0.7)
for i, (x, y) in enumerate(reduced_embeddings):
plt.annotate(papers_df.iloc[i]['title'][:20] + "...",
(x, y),
fontsize=9,
alpha=0.8)
plt.title('Document Embeddings Visualization (PCA)')
plt.xlabel('Component 1')
plt.ylabel('Component 2')
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
Let’s create a more interactive search interface:
from IPython.display import display, HTML, clear_output
import ipywidgets as widgets
def run_search(query_text):
clear_output(wait=True)
display(HTML(f"Query: {query_text}
"))
start_time = time.time()
results = semantic_search(query_text, top_k=5)
search_time = time.time() - start_time
display(HTML(f"Found {len(results)} results in {search_time:.4f} seconds"))
for i, result in enumerate(results):
html = f"""
{i+1}. {result['title']} (Score: {result['similarity_score']:.4f})
{result['abstract']}
"""
display(HTML(html))
search_box = widgets.Text(
value='',
placeholder='Type your search query here...',
description='Search:',
layout=widgets.Layout(width='70%')
)
search_button = widgets.Button(
description='Search',
button_style='primary',
tooltip='Click to search'
)
def on_button_clicked(b):
run_search(search_box.value)
search_button.on_click(on_button_clicked)
display(widgets.HBox([search_box, search_button]))
In this tutorial, we’ve built a complete semantic search system using Sentence Transformers. This system can understand the meaning behind user queries and return relevant documents even when there isn’t exact keyword matching. We’ve seen how embedding-based search provides more intelligent results than traditional methods.
Here is the Colab Notebook. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 85k+ ML SubReddit.
The post A Step-by-Step Guide to Building a Semantic Search Engine with Sentence Transformers, FAISS, and all-MiniLM-L6-v2 appeared first on MarkTechPost.







