


















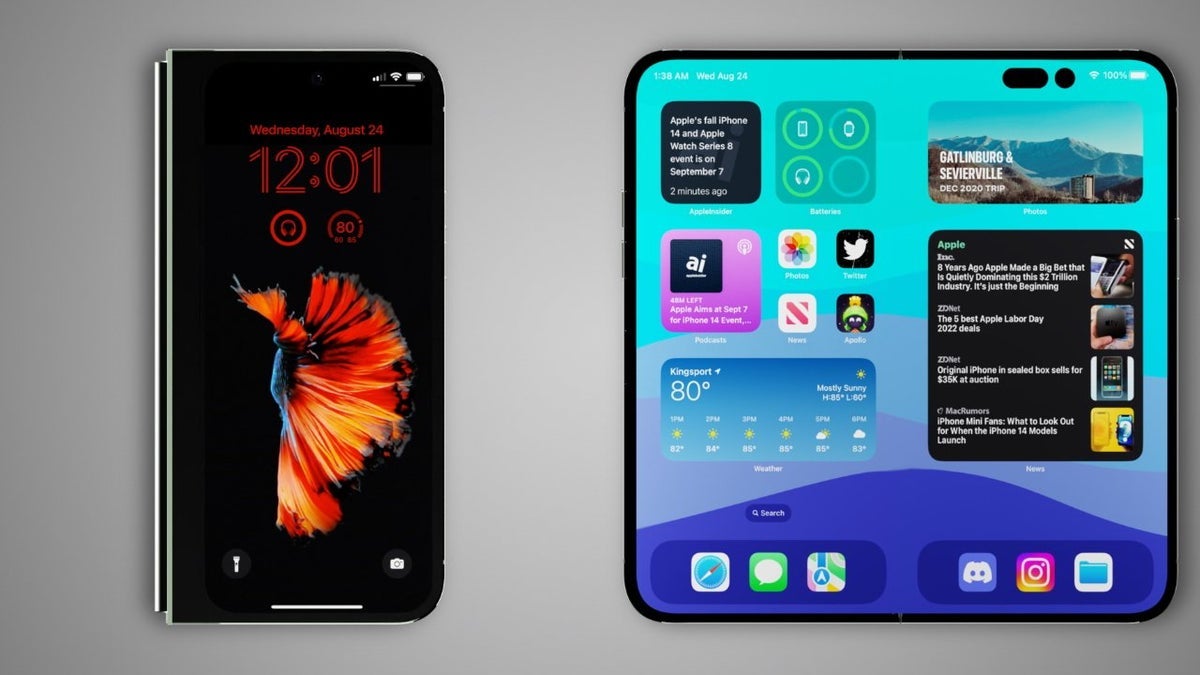







































![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)

![Apple Reorganizes Executive Team to Rescue Siri [Report]](https://www.iclarified.com/images/news/96777/96777/96777-640.jpg)








































































































_Federico_Caputo_Alamy.jpg?#)


































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)































































































































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


















.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)











![Release: Rendering Ranger: R² [Rewind]](https://images-3.gog-statics.com/48a9164e1467b7da3bb4ce148b93c2f92cac99bdaa9f96b00268427e797fc455.jpg)











































KBLAM: Efficient Knowledge Base Augmentation for Large Language Models Without Retrieval Overhead
LLMs have demonstrated strong reasoning and knowledge capabilities, yet they often require external knowledge augmentation when their internal representations lack specific details. One method for incorporating new information is supervised fine-tuning, where models are trained on additional datasets to update their weights. However, this approach is inefficient as it requires retraining whenever new knowledge is […] The post KBLAM: Efficient Knowledge Base Augmentation for Large Language Models Without Retrieval Overhead appeared first on MarkTechPost.



LLMs have demonstrated strong reasoning and knowledge capabilities, yet they often require external knowledge augmentation when their internal representations lack specific details. One method for incorporating new information is supervised fine-tuning, where models are trained on additional datasets to update their weights. However, this approach is inefficient as it requires retraining whenever new knowledge is introduced and may lead to catastrophic forgetting, degrading the model’s performance on general tasks. To overcome these limitations, alternative techniques that preserve the model’s weights have gained popularity. RAG is one approach that retrieves relevant knowledge from unstructured text and appends it to the input query before passing it through the model. By dynamically retrieving information, RAG enables LLMs to access large knowledge bases while maintaining a smaller context size. However, as long-context models such as GPT-4 and Gemini have emerged, researchers have explored in-context learning, where external knowledge is directly provided in the model’s input. This eliminates the need for retrieval but comes with computational challenges, as processing long contexts requires significantly more memory and time.
Several advanced techniques have been developed to enhance LLMs’ ability to integrate external knowledge more efficiently. Structured attention mechanisms improve memory efficiency by segmenting the context into independent sections, reducing the computational load of self-attention. Key-value (KV) caching optimizes response generation by storing precomputed embeddings at different layers, allowing the model to recall relevant information without recalculating it. This reduces the complexity from quadratic to linear concerning context length. Unlike traditional KV caching, which requires full recomputation when the input changes, newer methods allow selective updates, making external knowledge integration more flexible.
Researchers from Johns Hopkins University and Microsoft propose a Knowledge Base Augmented Language Model (KBLAM), a method for integrating external knowledge into LLMs. KBLAM converts structured knowledge base (KB) triples into key-value vector pairs, seamlessly embedding them within the LLM’s attention layers. Unlike RAG, it eliminates external retrievers, and unlike in-context learning, it scales linearly with KB size. KBLAM enables efficient dynamic updates without retraining and enhances interpretability. Trained using instruction tuning on synthetic data, it improves reliability by refusing to answer when relevant knowledge is absent, reducing hallucinations and enhancing scalability.
KBLAM enhances LLMs by integrating a KB through two steps. First, each KB triple is converted into continuous key-value embeddings, termed knowledge tokens, using a pre-trained sentence encoder and linear adapters. These tokens are then incorporated into each attention layer via a rectangular attention structure, allowing efficient retrieval without altering the LLM’s core parameters. This method ensures scalability, mitigates positional bias and maintains reasoning abilities. Additionally, instruction tuning optimizes knowledge token projection without modifying the LLM, using a synthetic KB to prevent memorization. This approach efficiently integrates large KBs while preserving the model’s original capabilities.
The empirical evaluation of KBLAM demonstrates its effectiveness as a knowledge retrieval and reasoning model. After instruction tuning, its attention matrix exhibits interpretable patterns, allowing accurate retrieval. KBLAM achieves performance comparable to in-context learning while significantly reducing memory usage and maintaining scalability up to 10K triples. It can also refuse to answer when no relevant knowledge is found, with “over-refusal” occurring later than in-context learning. The model is trained on an instruction-tuned Llama3-8B and optimized using AdamW. Evaluation of synthetic and Enron datasets confirms KBLAM’s strong retrieval accuracy, efficient knowledge integration, and ability to minimize hallucinations.
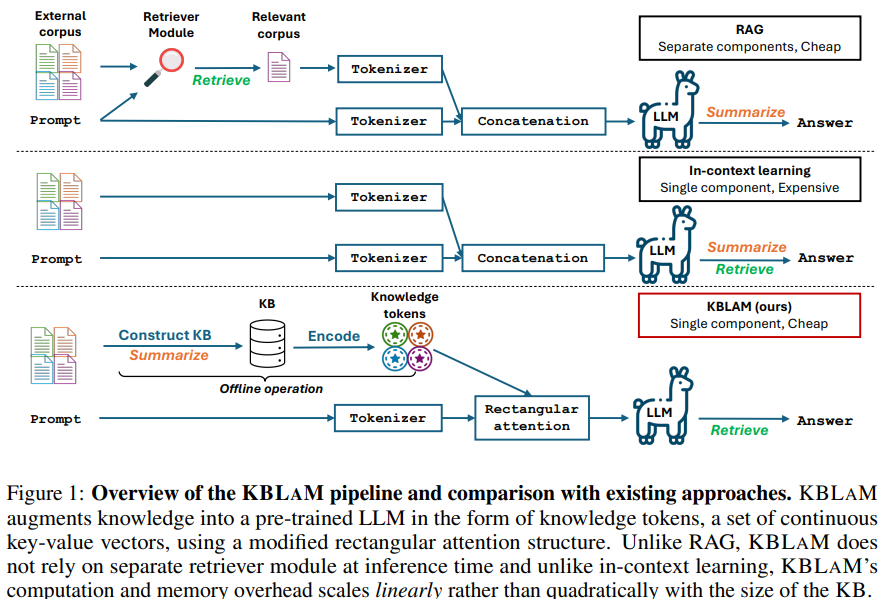
In conclusion, KBLAM is an approach for enhancing LLMs with external KBs. It encodes KB entries as continuous key-value vector pairs using pre-trained sentence encoders with linear adapters and integrates them into LLMs through a specialized attention mechanism. Unlike Retrieval-Augmented Generation, KBLAM removes external retrieval modules, and unlike in-context learning, it scales linearly with KB size. This enables efficient integration of over 10K triples into an 8B LLM within an 8K context window on a single A100 GPU. Experiments show its effectiveness in question-answering and reasoning tasks while maintaining interpretability and enabling dynamic knowledge updates.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post KBLAM: Efficient Knowledge Base Augmentation for Large Language Models Without Retrieval Overhead appeared first on MarkTechPost.







