


















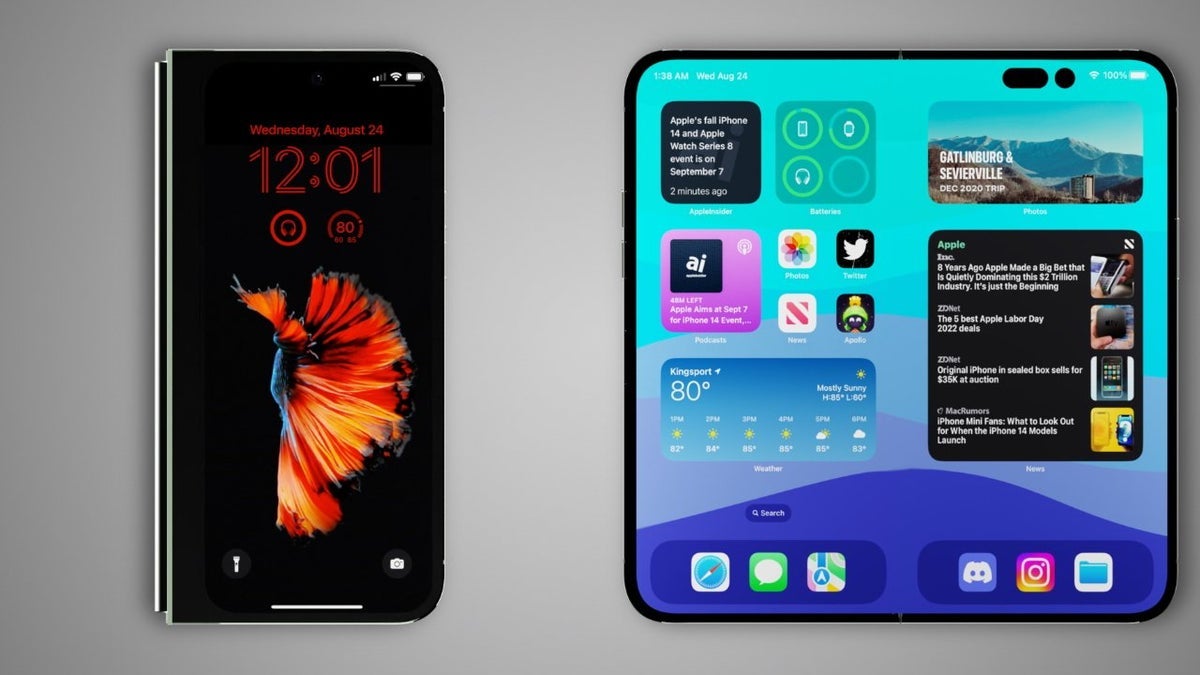







































![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)

![Apple Reorganizes Executive Team to Rescue Siri [Report]](https://www.iclarified.com/images/news/96777/96777/96777-640.jpg)








































































































_Federico_Caputo_Alamy.jpg?#)

































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)
































































































































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


















.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)











![Release: Rendering Ranger: R² [Rewind]](https://images-3.gog-statics.com/48a9164e1467b7da3bb4ce148b93c2f92cac99bdaa9f96b00268427e797fc455.jpg)











































Interview with AAAI Fellow Roberto Navigli: multilingual natural language processing
Each year the AAAI recognizes a group of individuals who have made significant, sustained contributions to the field of artificial intelligence by appointing them as Fellows. Over the course of the next few months, we’ll be talking to some of the 2025 AAAI Fellows. In this interview we hear from Roberto Navigli, Sapienza University of […]


Each year the AAAI recognizes a group of individuals who have made significant, sustained contributions to the field of artificial intelligence by appointing them as Fellows. Over the course of the next few months, we’ll be talking to some of the 2025 AAAI Fellows. In this interview we hear from Roberto Navigli, Sapienza University of Rome, who was elected as a Fellow for “significant contributions to multilingual Natural Language Understanding, and development of widely recognized methods for knowledge resource construction, text disambiguation, and semantic parsing”. We find out about his career path, some big research projects he’s led, and why it’s important to follow your passion.
Could you start by introducing yourself – where you work and your general area of research?
I’m a professor at the Sapienza University of Rome, Italy. My area of research is natural language processing (NLP). I’ve always worked in that area, and I’ve always been interested in language in general and in the way that computers can understand language. This interest started more than 20 years ago, way before the deep learning revolution and the widespread success of systems like ChatGPT, when NLP was certainly more creative and researchers like me were focused on the “meaning of meaning”.
Could you tell us about your career path?
I began my journey as a researcher, and since joining a big tech company after obtaining a PhD was far less obvious 20 years ago, I chose to pursue an academic career. Nine years ago, following the success of a big European Research Council (ERC) project, we created a university spin-off start-up company called Babelscape. Now, I’m essentially balancing both roles—academia and industry: I’m both a professor with a big group at Sapienza, about 20 people, and as many people in my company, where I am currently scientific director. As well as the research at Sapienza, we also do research at Babelscape because I wanted the company to be a research-oriented, research-driven company. We have several PhDs at the company, and we also have PhD students pursuing an industrial PhD in the company while being granted their PhD from Sapienza. It’s a mutually beneficial relationship because many people work for both the university and the company, or for either of the two and exchange knowledge, know-how and ideas.
For me it was a growth process, setting up this company. In academia, we write papers and do a lot of research, experiments and so on, but we rarely focus on making these research prototypes into real products that can be utilized by users. A company, in order to survive, needs to create systems that work. This is where you see the other side – the real-world use cases. You realise what the missing gap is between your super cool research prototype and the real product. The company also provides another way to retain talent in Rome, helping to counter the significant migration of people towards other countries or big tech companies. If you have a deep tech company next to university with a lot of enthusiasm, a lot of excitement, people will be happy to stay in their beloved city.

You’ve been involved in so many interesting projects during your career. A couple that particularly stand out are BabelNet and Minerva. Could you tell us a bit about BabelNet first?
I’m very proud of BabelNet because it was a dream come true. We embarked on this dream around 2009, and it was funded by the European Research Council (ERC). For me, that was a big thing because the ERC funded a €1.3 million project when I was a very young researcher. In Italy, this is quite uncommon, to be able to fund a group of 10-15 people out of the blue, “just” starting from an ambitious idea and a pretty good CV.
The idea was to create a huge repository of multilingual knowledge, in particular of lexical knowledge. By this I mean basically encoding the meaning of words – not only words you find in a dictionary but also words you would find in an encyclopaedia. The goal of BabelNet in a single sentence is to move dictionaries and encyclopaedias to the next level by bringing them together, within and across languages.
There are many dictionaries in the same language or in different languages, and they don’t talk to each other because each dictionary has its own set of meanings for each word. As you go multilingual it’s even more complex because there’s not necessarily a one-to-one relationship between a meaning in one language and a meaning in another language. The difficulty is that you have several dictionaries in a given language and in multiple languages you have even more dictionaries, and what I wanted to do was to interconnect all these dictionaries and create a unified one. I aimed to do it computationally so that it could be used as a multilingual meaning inventory for a computer system. Multilingual meaning that a concept would be independent of the language. The idea was to create a network of concepts, like a semantic network, or what we call today a knowledge graph. Each concept is associated with all the words that in the various languages are used to express the concept. Then the concept is connected to other concepts through relations.
The other side of BabelNet is the encyclopaedic part. It’s not only dictionaries, it’s also encyclopaedic content, for example content about well-known people, locations, organizations, albums, whatever, something that today you would find in Wikipedia.
We brought together meanings from different dictionaries (and they needed to be open dictionaries because we want an open resource). We started from WordNet, which is the most popular computational lexicon of English, and is already organised in graph form, and then we considered Wikipedia as the encyclopaedic counterpart. Luckily, Wikipedia also contains entries that are included in dictionaries, which helps make the connection between the two if one develops – as we did – an effective algorithm that accurately merges those entries from the two resources that represent the same meanings. A merged entry contains both a reference to the Wikipedia page and a reference to WordNet and all the other resources that we integrated (such as Wiktionary and Wikidata). And as a result of this, you have a unified graph that contains millions of concepts and named entities that are interconnected to each other. And this is done in hundreds of languages. We started in 2010 and now, after 15 years, we have 600 languages, 23 million concepts and entities, and a huge amount of translations, relations, etc. It’s a vast resource of knowledge that acts as a multilingual meaning reference in tasks where grounding text to meaning is important, like Word Sense Disambiguation, Entity Linking and semantic indexing.
Something I’ve always been deeply very interested in is disambiguating the meaning of words. When thinking about using machines to translate, you need to understand the meaning of each word because otherwise you cannot choose the right translation into the target language. With BabelNet, my idea was to create a language-independent inventory, which means a concept doesn’t depend on the language. When I associate this concept with a word in context, that concept doesn’t depend on the form and the language with which that concept was expressed.
So, with BabelNet my team and I worked on disambiguating the meaning of words across languages. Next, I wanted to create a language-independent representation for a whole sentence. Luckily, my second grant proposal to the ERC was accepted. With this next project we had the idea of representing each sentence as a little graph of the BabelNet concepts and entities that the sentence interconnects. This was much more challenging, and we are still working on it. It’s something that has been one of the dreams of AI for many, many years, and it’s certainly still a hard challenge. Working on structured representations of meanings of entire sentences is different: For example, if I have five sentences in five different languages that express the very same meaning, the very same concept, just a translation of each other, we want to produce a single representation that is independent of the language for those five sentences. That’s the idea.
At the time of the BabelNet, my ideas and the achievements of my team were very significant because not many researchers were investigating multilinguality at scale. Today, it’s taken for granted that a large language model will support multiple languages, but in 2010, this was far from obvious. Having a resource that offered a language-independent inventory of meanings was, therefore, a major breakthrough. We actually received a lot of interest in BabelNet from many companies and public bodies, including the EU Intellectual Property Office (EUIPO) and Adobe. That’s when our spin-off company Babelscape started.

So did the advent of LLMs lead you to new developments, like the Minerva project? What is the goal of this research?
With the advent of ChatGPT, we realised that we needed to fill a gap in Italy (and also in other countries), where academic knowledge about how these systems worked existed but lacked practical implementation. In the context of a big project called the Future Artificial Intelligence Research (FAIR), funded by the Next-Generation EU programme, we could start the Minerva LLM project with more than one goal in mind.
Our first goal was to create the know-how, focusing on the engineering exercise. The second goal was to create a model that is pre-trained from scratch, not only in English but also in Italian. Many models, when we started the project, and we are talking about 2023, were initially trained in English, but not in Italian, and only subsequently adapted to Italian. Instead, we wanted to see the impact of training on Italian as a first initial language. The third goal was to make the project fully open source, so that the model would play the role of a “living project” people could contribute to, as well as a more transparent approach compared to mainstream open-access models. The project gave us all the first-hand knowledge needed to go to the next level: How can we go beyond the current frontier in NLP? And that’s what we are starting to do now, considering that it took us a year to create a mid-sized model. Given our budget, we could not go as big as GPT-4 or DeepSeek, of course. But I don’t think that’s a problem, because a key research direction that we are tackling is how to reduce the size of these models. Current large language models are just too big; the ones that we use every day require such big amounts of power and water that are not sustainable: We absolutely need to explore ways to develop smaller models and possibly adopt new, more efficient approaches, not to mention their limits in commonsense and reasoning.
Minerva has also given us further visibility and recognition at the national level. It’s ironic because before Minerva I have had a lot of visibility abroad, but much less in Italy. Through this project, we’ve not only gained recognition in Italy but also caught the attention of both institutions and the general public. Now I even meet people on the street who recognize me as the project lead of Minerva!
What is the connection between the work you did before Minerva and the Minerva project?
The work I did before was focused on semantics: what are the meanings of a word or a sentence, and how can we make such meanings explicit with a computer? Now, we have large language models that don’t care about making this meaning explicit because they produce a so-called latent representation. In a sense this is a bit scary because you always want a machine to be more accountable and explainable than a human, and so not fully understanding what a system comprehends and why it produces certain output is a significant challenge. That’s where I think that our research on semantics (both lexical semantics, i.e. the meaning of words, and sentence-level semantics) is actually very useful and can empower these models to become more interpretable and more explainable in the future. And that’s what we are working on now. For instance, we recently discovered that, although very fluent, LLMs do not fully understand the meaning of words, especially when used in less frequent meanings.
Looking forward, is there one particular problem or project you’re particularly excited about working on in the next year or two?
I’m envisioning an ambitious program that tackles both semantics and large language models, aiming to push NLP technology to the next level. It’s a major undertaking, and while I don’t yet have all the pieces to say we’re fully on track, I have strong indications of where I want to go next. That makes me incredibly excited! In fact, I might be more excited than many other researchers because I see the potential in combining past work with what we’re currently developing—and how, together, they can drive a real breakthrough. It’s like the thrill artists feel when bringing a new creation to life!
Do you have any advice for PhD students or early career researchers?
I always tell them to follow their passion. Passion is what drove me along a complex, challenging path without feeling burdened. Of course, effort is always required when you work hard, but when you truly love what you do and don’t chase things like money alone you find fulfillment in work. Having a job that feels like a hobby—one you’re lucky enough to be paid for—is a privilege. And if you dedicate yourself fully and do it right, success will follow—and perhaps, eventually, even financial rewards.
Have you got any hobbies or interests outside of your research you’d like to mention?
My main hobby outside of research is reading books. It’s my best way to disconnect from the Internet, and from the computer science world in general (which is why I read on paper). I especially enjoy thrillers and spy novels—stories that grip your attention so completely that you forget about everything else. That said, I read all kinds of books. I started quite early, thanks to two people who guided me down this path: a teacher and a friend. Many people never realize they enjoy reading simply because they don’t make a habit of it, and I might have been one of them if not for these two dear individuals. I began with just a few books, and now I have around 10,000 in my apartment. Whether I’ll ever manage to read them all—who knows?
About Roberto

|
Roberto Navigli is Professor of Natural Language Processing at the Sapienza University of Rome, where he leads the Sapienza NLP Group. He has received two ERC grants on lexical and sentence-level multilingual semantics, highlighted among the 15 projects through which the ERC transformed science. He received several prizes, including two Artificial Intelligence Journal prominent paper awards and several outstanding/best paper awards from ACL. He is the co-founder of Babelscape, a successful deep-tech multilingual NLP company. He served as Associate Editor of the AI Journal and Program Co-Chair of ACL-IJCNLP 2021. He is a Fellow of AAAI, ACL, ELLIS and EurAI and serves as General Chair of ACL 2025. |






