

























































![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)

![Apple Reorganizes Executive Team to Rescue Siri [Report]](https://www.iclarified.com/images/news/96777/96777/96777-640.jpg)








































































































_Federico_Caputo_Alamy.jpg?#)


































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)
































































































































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


















.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)











![Release: Rendering Ranger: R² [Rewind]](https://images-3.gog-statics.com/48a9164e1467b7da3bb4ce148b93c2f92cac99bdaa9f96b00268427e797fc455.jpg)











































Data Modeling for Java Developers: Structuring With PostgreSQL and MongoDB
Application and system designs have always been considered the most essential step in application development. All the later steps and technologies to be used depend on how the system has been designed. If you are a Java developer, choosing the right approach can mean distinguishing between a rigid, complex schema and a nimble, scalable solution. If you are a Java developer who works with PostgreSQL or other relational databases, you understand the pain of representing the many-to-many relationships between the tables. This tutorial will ease your pain with these or other relationships defined in databases by making use of a document database, MongoDB. In this article, we’ll understand both approaches, contrasting PostgreSQL’s relational rigour with MongoDB’s document-oriented simplicity. You’ll learn how to weigh trade-offs like ACID compliance versus scalability and discover why MongoDB’s design might save you time. Relationships in databases Relationships in databases introduce the connection between the entities of two or more different collections or tables. These relationships help the applications to have the dependencies interlinked with each other. To understand this in brief, let’s look at an example of a library management system that has tables for authors, books, issue details, etc. inside the database. One-to-one relationship Each record in Table A is related to only one record in Table B. Example: A Library Member table and an Issue Details table can have a one-to-one relationship, where each member can have only one active book issued at a time. One-to-many relationship A single record in Table A can be related to multiple records in Table B. For instance, a Book can have many Reviews or a user can have many contact addresses. Many-to-many relationship In this type of relationship, multiple records in Table A can relate to various records in Table B, requiring a junction (or bridge) table. For example, a Book can be issued to multiple Members over time, and a Member can borrow numerous Books. Relational vs. document databases A relational database is based on rigid predefined schemas and emphasises relationships. These work well when the structure is strict and is not subjected to much change in the future. SQL or MySQL has been the backbone of relational databases for many years now. Whether you’re organizing customer contacts or powering complex financial systems, SQL’s straightforward yet powerful commands have made it a go-to tool for businesses worldwide—and it’s been that way for decades. Relational databases thrive on flexibility, adapting to everything from small-scale apps to enterprise-level solutions. That’s why industries of all kinds, from retail to healthcare, rely on them to store, manage, and make sense of their data. Think of SQL as the quiet workhorse behind the scenes, keeping everything running smoothly. A document database, on the other hand, is meant for a more flexible structure. They work well with modern applications where a variety of data is stored and processed from the applications. A document database represents data as documents, typically using formats like JSON (JavaScript object notation) or BSON (Binary JSON). A document database is often referred to as a NoSQL database. MongoDB is the most popular database used in modern application development. The flexible storage capability allows the application to scale horizontally and grow efficiently with the rapid changes. Postgres implementation with Java To understand how data in a Postgres database would be implemented with Java, let us consider an example ER diagram for a library management system consisting of Books, Authors, and Issue Details. The ER diagram below depicts the one-to-many relationship between Books and Issue Details and the many-to-many relationship between Author and Books using the Author_Books table created using join operations. Fig: ER diagram for the library management system using four different tables Now, let us try to understand how these entities will be represented using the Java Hibernate code and the relationship annotations. Let's first understand the Author representing the Author entity: @Entity public class Author { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long authorID; private String name; private String email; private String nationality; @ManyToMany(mappedBy = "authors", cascade = CascadeType.ALL) private Set books; } Similarly, the Books entity would be represented as: @Entity public class Book { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long bookID; private String title; private String isbn; private String genre; private int publishedYear; @ManyToMany(cascade = CascadeType.ALL) @JoinTable( name = "author_books", joinColumns = @JoinColu
Application and system designs have always been considered the most essential step in application development. All the later steps and technologies to be used depend on how the system has been designed. If you are a Java developer, choosing the right approach can mean distinguishing between a rigid, complex schema and a nimble, scalable solution. If you are a Java developer who works with PostgreSQL or other relational databases, you understand the pain of representing the many-to-many relationships between the tables.
This tutorial will ease your pain with these or other relationships defined in databases by making use of a document database, MongoDB.
In this article, we’ll understand both approaches, contrasting PostgreSQL’s relational rigour with MongoDB’s document-oriented simplicity. You’ll learn how to weigh trade-offs like ACID compliance versus scalability and discover why MongoDB’s design might save you time.
Relationships in databases
Relationships in databases introduce the connection between the entities of two or more different collections or tables. These relationships help the applications to have the dependencies interlinked with each other. To understand this in brief, let’s look at an example of a library management system that has tables for authors, books, issue details, etc. inside the database.
One-to-one relationship
Each record in Table A is related to only one record in Table B. Example: A Library Member table and an Issue Details table can have a one-to-one relationship, where each member can have only one active book issued at a time.
One-to-many relationship
A single record in Table A can be related to multiple records in Table B. For instance, a Book can have many Reviews or a user can have many contact addresses.
Many-to-many relationship
In this type of relationship, multiple records in Table A can relate to various records in Table B, requiring a junction (or bridge) table. For example, a Book can be issued to multiple Members over time, and a Member can borrow numerous Books.
Relational vs. document databases
A relational database is based on rigid predefined schemas and emphasises relationships. These work well when the structure is strict and is not subjected to much change in the future. SQL or MySQL has been the backbone of relational databases for many years now.
Whether you’re organizing customer contacts or powering complex financial systems, SQL’s straightforward yet powerful commands have made it a go-to tool for businesses worldwide—and it’s been that way for decades. Relational databases thrive on flexibility, adapting to everything from small-scale apps to enterprise-level solutions. That’s why industries of all kinds, from retail to healthcare, rely on them to store, manage, and make sense of their data. Think of SQL as the quiet workhorse behind the scenes, keeping everything running smoothly.
A document database, on the other hand, is meant for a more flexible structure. They work well with modern applications where a variety of data is stored and processed from the applications. A document database represents data as documents, typically using formats like JSON (JavaScript object notation) or BSON (Binary JSON). A document database is often referred to as a NoSQL database.
MongoDB is the most popular database used in modern application development. The flexible storage capability allows the application to scale horizontally and grow efficiently with the rapid changes.
Postgres implementation with Java
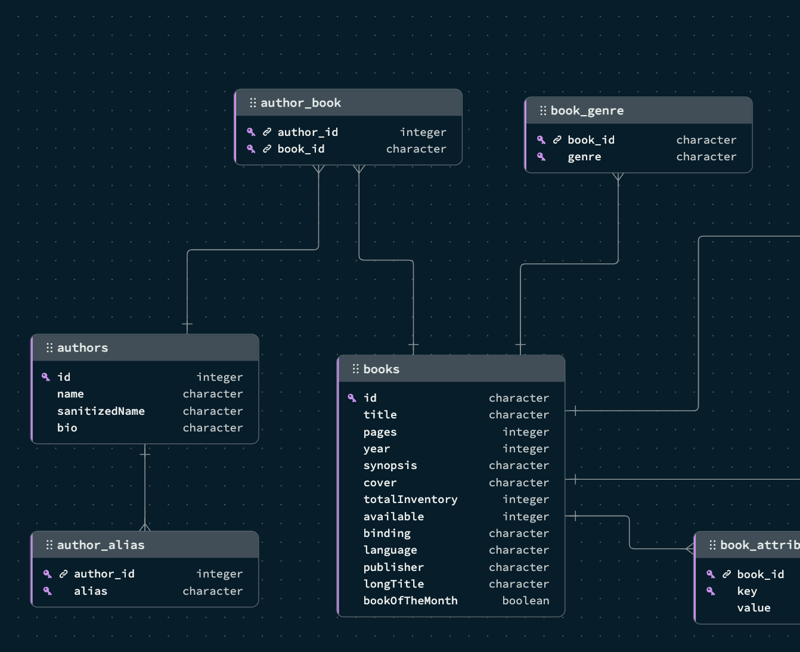
To understand how data in a Postgres database would be implemented with Java, let us consider an example ER diagram for a library management system consisting of Books, Authors, and Issue Details.
The ER diagram below depicts the one-to-many relationship between Books and Issue Details and the many-to-many relationship between Author and Books using the Author_Books table created using join operations.
Fig: ER diagram for the library management system using four different tables
Now, let us try to understand how these entities will be represented using the Java Hibernate code and the relationship annotations.
Let's first understand the Author representing the Author entity:
@Entity
public class Author {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long authorID;
private String name;
private String email;
private String nationality;
@ManyToMany(mappedBy = "authors", cascade = CascadeType.ALL)
private Set<Book> books;
}
Similarly, the Books entity would be represented as:
@Entity
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bookID;
private String title;
private String isbn;
private String genre;
private int publishedYear;
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(
name = "author_books",
joinColumns = @JoinColumn(name = "bookID"),
inverseJoinColumns = @JoinColumn(name = "authorID")
)
private Set<Author> authors;
@OneToMany(mappedBy = "book", cascade = CascadeType.ALL)
private Set<IssueDetails> issueDetails;
//Getters and Setters
}
Now, the Author_books table has been created using the join methods and hence, we do not need to define a separate entity class.
The relationship between the entities has been established using the relationship annotations like @ManytoMany.
Similarly, to represent the one-to-many relationship between Books and the Issue Details using the @OneToMany annotation, we can write the entity class as:
@Entity
public class IssueDetails {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long issueID;
@ManyToOne
@JoinColumn(name = "bookID", nullable = false)
private Book book;
private Long userID;
private Date issueDate;
private Date returnDate;
private String status;
// Getters and Setters
}
The relationships implemented in the above code snippet could be very simple. If you are wondering how, the answer to this is in the next section where we will understand how simple it can be to use MongoDB as the database.
MongoDB implementation with Java
Let us understand the representation in a simpler way using the MongoDB document model and its data modelling techniques.
For example, representing the many-to-many relationship between the authors and books can be done using embedding or referencing data modelling techniques.
It is also important to note that if authors and books are frequently queried together, embedding author references within books or vice versa might be efficient. However, since an author can write many books and a book can have multiple authors, embedding might lead to duplication. So maybe using references with arrays of author IDs in books and book IDs in authors would be better. But that could complicate updates if an author's information changes. Alternatively, just using an array of author IDs in the book documents and not maintaining the inverse in authors might suffice, depending on query needs.
Depending on the modelling technique chosen, the documents inside in the collection would change. For example:
{
_id: ObjectId("60d5ec9f4b1a8e2a1c8f7a1"),
name: "J.K. Rowling",
email: "jkrowling@example.com",
nationality: "British",
books: [
ObjectId("60d5ec9f4b1a8e2a1c8f7a2"),
ObjectId("60d5ec9f4b1a8e2a1c8f7a3")
]
}
The book collection would look like the below:
{
_id: ObjectId("60d5ec9f4b1a8e2a1c8f7a2"),
title: "Harry Potter and the Sorcerer's Stone",
isbn: "9780590353427",
genre: "Fantasy",
publishedYear: 1997,
authors: [
ObjectId("60d5ec9f4b1a8e2a1c8f7a1")
],
issues: [
{
userId: ObjectId("60d5ec9f4b1a8e2a1c8f7a4"),
issueDate: ISODate("2023-10-01"),
returnDate: ISODate("2023-10-15"),
status: "Returned"
}
]
}
As you can see from the above example, the document model of MongoDB is similar to the POJOs representation in Java. Therefore, the representation of the model class becomes simpler with Java.
For example, the author class in Java would be written as:
@Document(collection = "authors")
public class Author {
@Id
private ObjectId id;
private String name;
private String email;
private String nationality;
private List<Book> bookIds;
//Getters and Setters
}
The book class can be written as:
@Document(collection = "books")
public class Book {
@Id
private ObjectId id;
private String title;
private String isbn;
private String genre;
private int publishedYear;
private List<Author> authorIds;
// Getters and Setters
}
From the above code snippet, you can see cleaner and less complex code without any complicated annotations to represent the relationships.
Scalability and performance
After the demonstration of a few small code snippets from both databases, it is also important to understand the scalability and the performance considerations while creating a Java application.
We have all heard by now that Postgres is a powerful relational database that handles the structured query, but what does it do when an application needs to be scaled? Postgres scales vertically, which involves upgrading the hardware of a single server (e.g., adding more CPU, RAM, or storage). This approach is ideal for applications with predictable growth and moderate traffic. Still, it comes with limitations as hardware upgrades can become expensive, and there’s a physical ceiling to how much a single server can handle.
On the other hand, MongoDB is designed for scalability and high performance, especially regarding unstructured data and modern applications. MongoDB performs scalability using horizontal scaling, which means distributing data across multiple servers. This process in MongoDB is known as sharding, and the shards are created by selecting the right and appropriate shard key. Additionally, MongoDB optimizes read and write throughput through features like replica sets (for read scaling) and batch operations (for write scaling).
The performance of Java applications with MongoDB is optimised using demoralizations and indexing. Embedding and referencing the data reduces the need for expensive joins and enhances the query and application performance.
Migration considerations
When you migrate the data from Postgres to MongoDB, the process involves more than just moving the data. It specifically requires you to think about the structuring of the data and also how to manage the data. In the next section, we’ll talk about those briefly.
Rethinking schema design
In a relational database like Postgres, data is often normalised across multiple tables—in our case, between Authors, Books, and Issue Details. In MongoDB, we need to combine the related data into embedded documents. For example, instead of storing authors and books in separate tables, you can embed author information directly within a book document.
@Document(collection = "books")
public class Book {
private String title;
private List<Author> authors; // Embedded authors
private List<IssueDetails> issues; // Embedded issues
}
Replacing joins with aggregations
Postgres makes use of joins to retrieve the related data. On the other hand, MongoDB relies mostly on writing aggregation pipelines to retrieve the related information. For example, a Postgres query might be:
SELECT books.title, authors.name
FROM books
JOIN author_books ON books.book_id = author_books.book_id
JOIN authors ON author_books.author_id = authors.author_id;
This could simply be done using the Java code using the aggregation as:
Document lookupStage = new Document("$lookup", new Document("from", "authors") .append("localField", "authors") .append("foreignField", "_id") .append("as", "authorDetails") );
AggregateIterable<Document> result = booksCollection.aggregate(Arrays.asList(lookupStage));
Conclusion
Data modelling is a crucial step in application development and selecting the right database can significantly impact the scalability, performance, and maintainability of the system. For Java developers, identifying the strengths and weaknesses of the relational and non-relational databases is essential to correctly structure and manage the data.
From this tutorial, we have understood that PostgreSQL, with its relational model, excels in scenarios requiring complex queries, ACID compliance, and structured data. Its ability to handle relationships through joins and enforce constraints makes it ideal for applications like financial systems, ERP platforms, and reporting tools. However, its reliance on vertical scaling can become a limitation as applications grow.
On the other hand, MongoDB’s data document model offers greater flexibility, scalability, and higher performance, which makes it a great fit for modern applications. Its ability to handle unstructured data and scale horizontally allows developers to build nimble, scalable solutions without the rigidity of a predefined schema.
MongoDB’s document model becomes a natural fit for the unstructured data in modern applications, offering Java developers the ability to store, query, and manipulate complex data without rigid schemas. With powerful indexing, aggregation pipelines, and native support for JSON-like BSON documents, MongoDB simplifies data access, transformations, and manipulation easier. Whether handling product catalogues, customer interactions, or AI-driven insights, MongoDB empowers Java developers to build scalable, high-performance applications with minimal friction.







