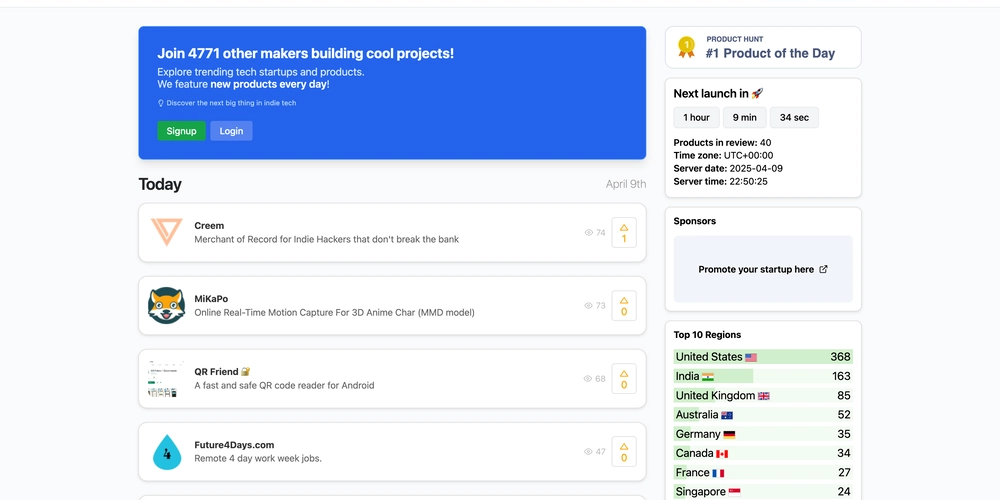
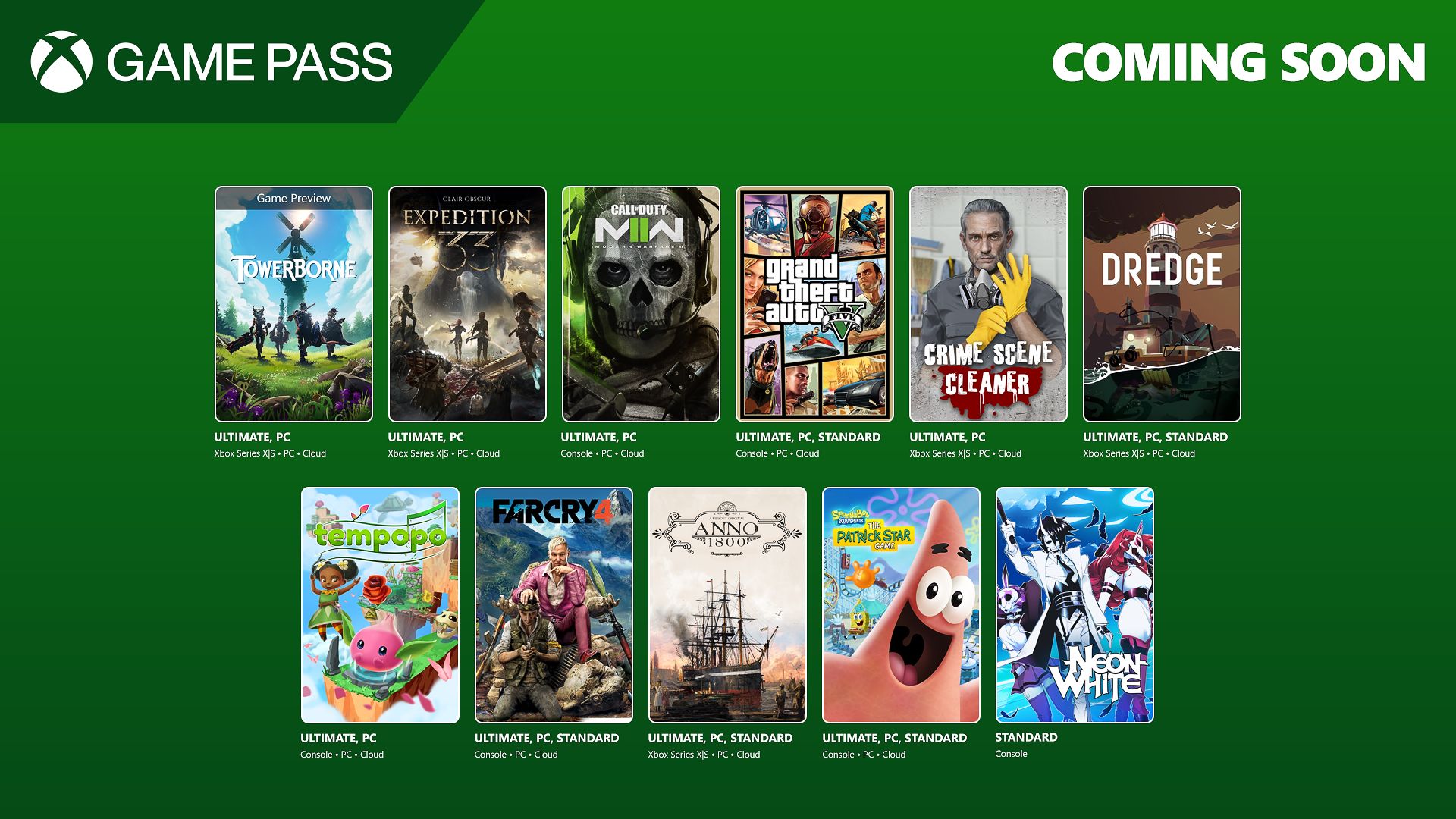
![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)
![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)


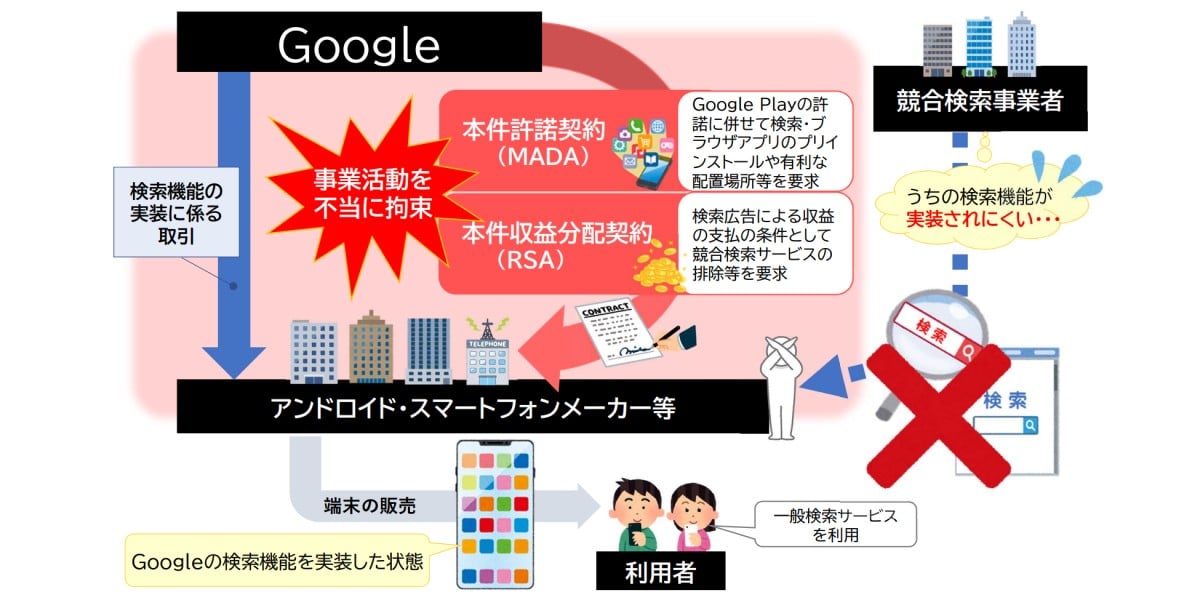

























































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
































































































































































































































Inside the Tech That Powers Neuro Swarm: A Closer Look Before Launch
With only three days to go until the official launch of Neuro Swarm, we're giving you a behind-the-scenes look at the powerful technology driving our platform. At its core, Neuro Swarm is built on a Web GPU foundation, tapping into the raw, unused computing power of devices across the globe. Whether you're on a high-end PC or a mobile device, our system adapts through automatic WebGL fallback, ensuring consistent and reliable performance across hardware types. But this is just the beginning. Our smart task batching engine combines with a dynamic load balancer to distribute tasks across the network in real time. A priority-based scheduler ensures that devices process tasks they're most suited for - based on both network latency and hardware strength. This makes every cycle count. ** Key highlights of our architecture include:** - 128MB persistent storage buffer to reduce overhead and speed up task handling. - Shader-f32 precision to maintain high-performance computing for GPU-accelerated tasks. - Real-time performance monitoring that allows us to constantly optimize processes and network health. We're redefining how distributed GPU computing is accessed and monetized. And we're just getting started. Follow along as we launch Neuro Swarm and turn idle computing into real revenue. https://x.com/neurolov https://app.neurolov.ai/ https://www.neurolov.ai/

With only three days to go until the official launch of Neuro Swarm, we're giving you a behind-the-scenes look at the powerful technology driving our platform.
At its core, Neuro Swarm is built on a Web GPU foundation, tapping into the raw, unused computing power of devices across the globe. Whether you're on a high-end PC or a mobile device, our system adapts through automatic WebGL fallback, ensuring consistent and reliable performance across hardware types.
But this is just the beginning.
Our smart task batching engine combines with a dynamic load balancer to distribute tasks across the network in real time. A priority-based scheduler ensures that devices process tasks they're most suited for - based on both network latency and hardware strength. This makes every cycle count.
**
Key highlights of our architecture include:**
- 128MB persistent storage buffer to reduce overhead and speed up task handling.
- Shader-f32 precision to maintain high-performance computing for GPU-accelerated tasks.
- Real-time performance monitoring that allows us to constantly optimize processes and network health.
We're redefining how distributed GPU computing is accessed and monetized. And we're just getting started.
Follow along as we launch Neuro Swarm and turn idle computing into real revenue.
https://x.com/neurolov
https://app.neurolov.ai/
https://www.neurolov.ai/