



































































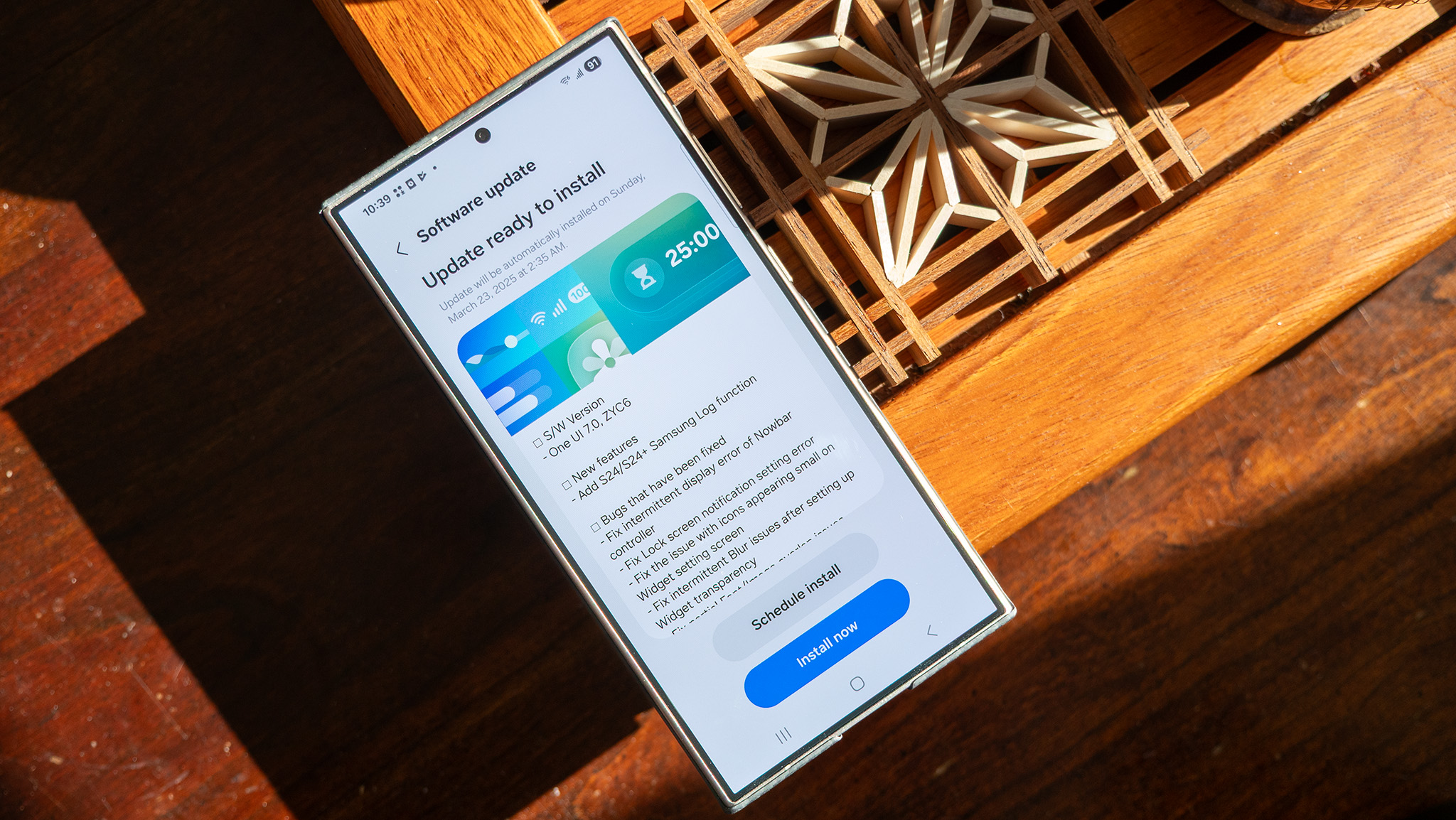
![Redesigned Plastic Apple Watch SE in 'Serious Jeopardy' [Gurman]](https://www.iclarified.com/images/news/96789/96789/96789-640.jpg)
![Apple Watch to Gain Cameras in Future Models [Gurman]](https://www.iclarified.com/images/news/96790/96790/96790-640.jpg)
![Apple M4 Mac Mini on Sale for $499 [Lowest Price Ever]](https://www.iclarified.com/images/news/96788/96788/96788-640.jpg)
![Apple Shares First Look and Premiere Date for 'The Buccaneers' Season Two [Video]](https://www.iclarified.com/images/news/96786/96786/96786-640.jpg)














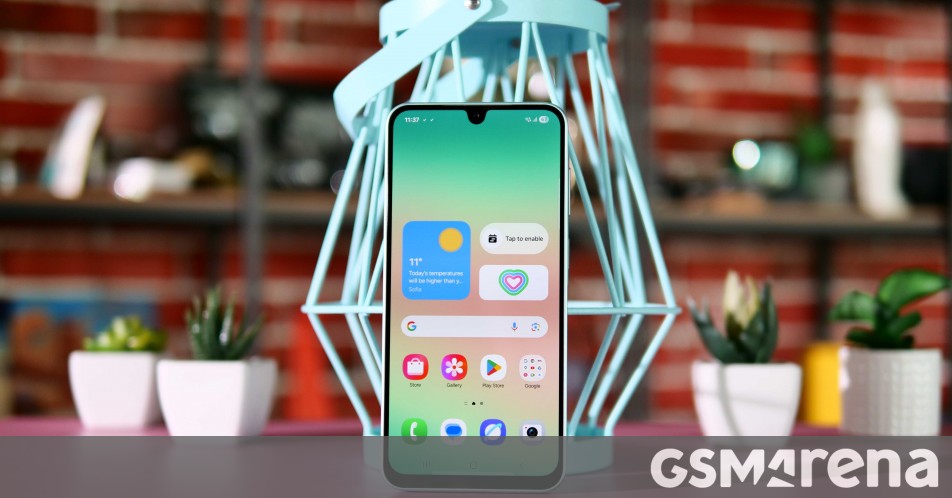
![Google updates Circle to Search with transparent navigation bar [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/galaxy-s25-circle-to-search-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)






















































































_robertharding_Alamy.jpg?#)





































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)






















































































































![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)






































.png?#)














































Meta AI Researchers Introduced SWEET-RL and CollaborativeAgentBench: A Step-Wise Reinforcement Learning Framework to Train Multi-Turn Language Agents for Realistic Human-AI Collaboration Tasks
Large language models (LLMs) are rapidly transforming into autonomous agents capable of performing complex tasks that require reasoning, decision-making, and adaptability. These agents are deployed in web navigation, personal assistance, and software development. To act effectively in real-world settings, these agents must handle multi-turn interactions that span several steps or decision points. This introduces the […] The post Meta AI Researchers Introduced SWEET-RL and CollaborativeAgentBench: A Step-Wise Reinforcement Learning Framework to Train Multi-Turn Language Agents for Realistic Human-AI Collaboration Tasks appeared first on MarkTechPost.

Large language models (LLMs) are rapidly transforming into autonomous agents capable of performing complex tasks that require reasoning, decision-making, and adaptability. These agents are deployed in web navigation, personal assistance, and software development. To act effectively in real-world settings, these agents must handle multi-turn interactions that span several steps or decision points. This introduces the need for training methods beyond simple response generation and instead focuses on optimizing the entire trajectory of interactions. Reinforcement learning (RL) has emerged as a compelling approach to train such agents by refining their decision-making based on long-term rewards.
Despite their potential, LLM-based agents struggle with multi-turn decision-making. A major challenge lies in assigning proper credit to actions taken at earlier stages of interaction, which influence later outcomes. Traditional training methods rely on next-token prediction or imitate high-probability actions, which do not account for long-term dependencies or cumulative goals. As a result, these methods fail to address the high variance and inefficiency of long-horizon tasks, particularly in collaborative scenarios where understanding human intent and reasoning across multiple steps is critical.
Various reinforcement learning techniques have been adapted to fine-tune LLMs, especially from single-turn human feedback scenarios. Tools like PPO, RAFT, and DPO have been explored but exhibit significant limitations when applied to sequential interactions. These methods often fail at effective credit assignment across turns, making them less effective for multi-turn decision-making tasks. Benchmarks used to evaluate such tools lack the diversity and complexity required to assess performance in collaborative, real-world settings robustly. Value-based learning approaches are another alternative, but their need for custom heads and large amounts of task-specific fine-tuning data limit their generalization capabilities.
FAIR at Meta and UC Berkeley researchers proposed a new reinforcement learning method called SWEET-RL (Step-WisE Evaluation from Training-time Information). They also introduced a benchmark known as CollaborativeAgentBench or ColBench. This benchmark is central to the study, providing over 10,000 training tasks and over 1,000 test cases across two domains: backend programming and frontend design. ColBench simulates real collaboration between an AI agent and a human partner, where agents must ask questions, refine their understanding, and provide iterative solutions. For programming, agents are required to write functions in Python by asking for clarifications to refine missing specifications. In front-end tasks, agents must generate HTML code that matches a visual target through feedback-based corrections. Each task is designed to stretch the reasoning ability of the agent and mimic real-world constraints like limited interactions, capped at 10 turns per session.

SWEET-RL is built around an asymmetric actor-critic structure. The critic has access to additional information during training, such as the correct solution, which is not visible to the actor. This information allows the critic to evaluate each decision made by the agent with a much finer resolution. Instead of training a value function that estimates overall reward, SWEET-RL directly models an advantage function at each turn, using the Bradley-Terry optimization objective. The advantage function determines how much better or worse a particular action is compared to alternatives, helping the agent learn precise behaviors. For example, if an action aligns better with the human partner’s expectation, it receives a higher advantage score. This method simplifies credit assignment and aligns better with the pre-training architecture of LLMs, which rely on token-level prediction.

SWEET-RL achieved a 6% absolute improvement over other multi-turn reinforcement learning methods across both programming and design tasks. On backend programming tasks, it passed 48.0% of tests and achieved a success rate of 34.4%, compared to 28.2% for Multi-Turn DPO and 22.4% for zero-shot performance. On frontend design tasks, it reached a cosine similarity score of 76.9% and a win rate of 40.4%, improving from 38.6% with DPO and 33.8% with fine-tuning. Even when evaluated against top proprietary models like GPT-4o and O1-Mini, SWEET-RL closed the performance gap significantly, enabling the open-source Llama-3.1-8B model to match or exceed GPT-4o’s frontend win rate of 40.4%.

This research demonstrates that effective training of interactive agents hinges on precise, turn-by-turn feedback rather than generalized value estimations or broad supervision. SWEET-RL significantly improves credit assignment by leveraging training-time information and an architecture-aligned optimization approach. It enhances generalization, reduces training variance, and shows strong scalability, achieving better results with increased data. The algorithm also remains effective when applied to off-policy datasets, underlining its practicality in real-world scenarios with imperfect data. The research team created a meaningful evaluation framework by introducing ColBench as a benchmark tailored for realistic, multi-turn tasks. This combination with SWEET-RL provides a strong foundation for developing agents that can reason, adapt, and collaborate effectively over extended interactions.

Several key takeaways from this research include:
- SWEET-RL improved backend programming success rates from 28.2% (DPO) to 34.4% and frontend win rates from 38.6% to 40.4%.
- It allowed Llama-3.1-8B to match the performance of GPT-4o, reducing dependency on proprietary models.
- The critic uses training-time information (e.g., correct solutions) that is invisible to the actor, creating an asymmetric training setup.
- Tasks in ColBench are capped at 10 rounds per session and include over 10,000 procedurally generated training examples.
- ColBench measures outcomes using unit test pass rates (for code) and cosine similarity (for web design), providing reliable evaluation.
- SWEET-RL directly learns a turn-wise advantage function, improving credit assignment without needing an intermediate value function.
- The model scales effectively with more data and performs well even on off-policy datasets from weaker models.
- Compared to traditional fine-tuning methods, SWEET-RL delivers higher performance with less overfitting and greater generalization.
Check out the Paper, GitHub Page and Dataset. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post Meta AI Researchers Introduced SWEET-RL and CollaborativeAgentBench: A Step-Wise Reinforcement Learning Framework to Train Multi-Turn Language Agents for Realistic Human-AI Collaboration Tasks appeared first on MarkTechPost.







