





























































![Apple to Craft Key Foldable iPhone Components From Liquid Metal [Kuo]](https://www.iclarified.com/images/news/96784/96784/96784-640.jpg)

![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)









































































































_Federico_Caputo_Alamy.jpg?#)


































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)
















































































































![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)
































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





.png?#)













































Learn API Fundamentals and Architecture – A Beginner-Friendly Guide
Here are some questions for you: How do you log in to apps with your Google, Apple, or Microsoft account? How do online payments with Paystack or PayPal work? How do apps like Facebook and Instagram share information and notifications? The answer is:...

Here are some questions for you: How do you log in to apps with your Google, Apple, or Microsoft account? How do online payments with Paystack or PayPal work? How do apps like Facebook and Instagram share information and notifications?
The answer is: they use APIs. These are powerful tools that drive mobile and web development and a wide range of applications, including cloud services, IoT devices, desktop software, and more.
APIs enable communication between applications, facilitating data exchange and verification.
In this article, you’ll learn all about APIs: the different types, their architecture, and the tradeoffs between the different architectures.
Here’s what we’ll cover:
This article is well-suited for beginners in web and mobile development and developers seeking a concise understanding of APIs and how they function.
What is an API?
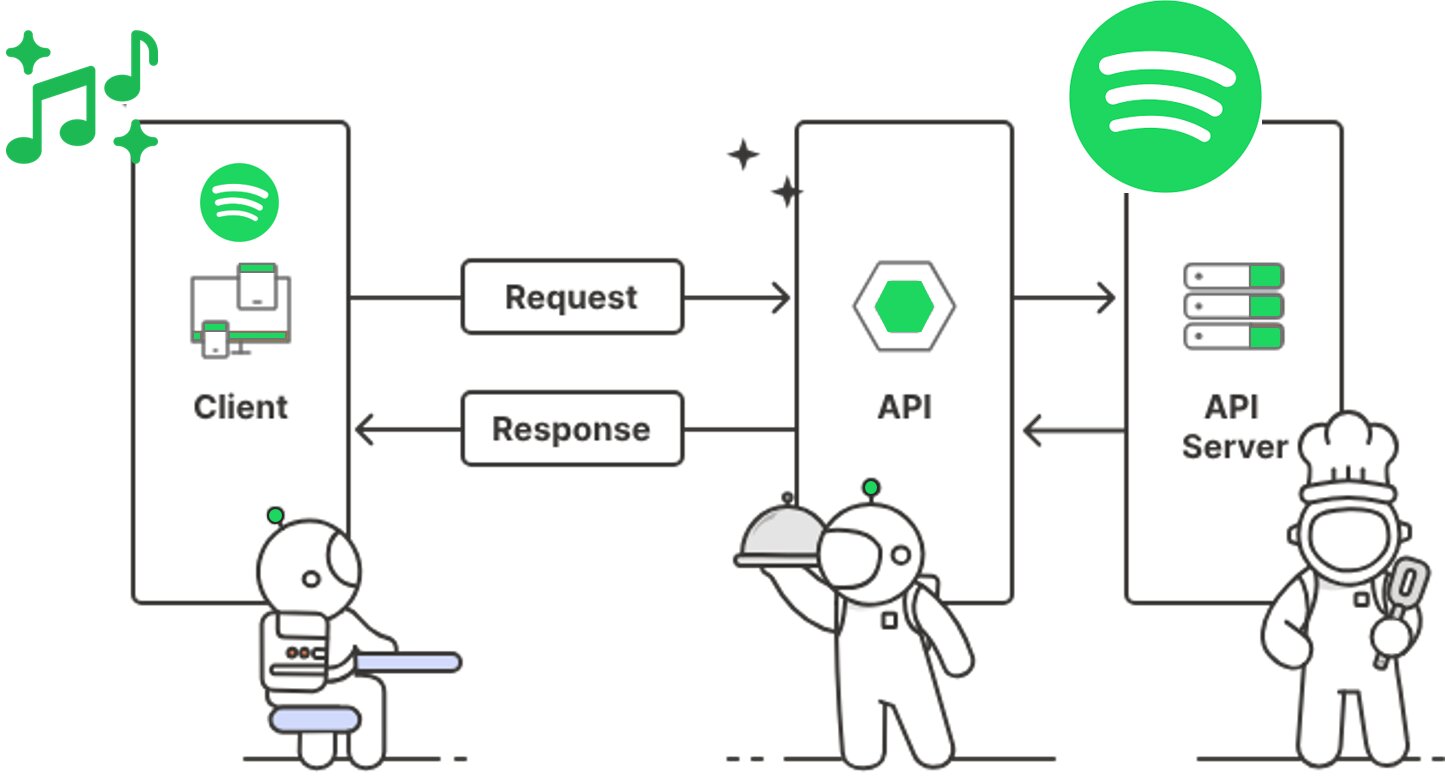
API stands for Application Programming Interface. It is a set of rules and protocols that lets different software systems communicate with each other. An API defines how applications request services and exchange data, acting as a clear contract between a client and a server.
APIs simplify complex code into simple commands, letting developers connect systems and use built-in features without needing to know all the internal workings.
How Do APIs Work?
Imagine a restaurant: the customer (client) orders food through the waiter (API), who then communicates the order to the kitchen (server). The kitchen prepares the meal and sends it back through the waiter to the customer. Just like the waiter, the API handles requests and responses, letting the customer enjoy the meal without needing to know the details of the kitchen's operations.
A more practical example is when you buy a subscription online, and your payment information is securely sent to Paystack through its payment API. The API is a middleman that takes your request, verifies and processes your payment details with the bank, and then returns a confirmation to the website without directly exposing sensitive data.
Technically, a client initiates a request aimed at a server, specifying either data retrieval or procedural execution. Upon receiving and authenticating this request, the API performs the required operations. Then the API sends a response to the client, including the request's outcome (success or failure) and any requested data elements.
Why Are APIs Important?
APIs are crucial in software development because they make connecting different applications and services easier. They let you integrate external functionalities without building everything from scratch, saving time and reducing complexity through standardised commands.
For users, APIs also enhance security and user experience. They serve as secure gateways that filter data exchange between apps and external services, protecting sensitive information while ensuring smooth, reliable interactions.
Types of APIs
API types are mainly categorised by their accessibility and usage. There are four types of APIs, namely:
Open (Public) APIs
Partner APIs
Internal (Private) APIs
Composite APIs
Open APIs
Open APIs are APIs made available to the general public. This encourages developers, organisations, and other people to use them to develop applications, integrate them into their services, and improve them. Open APIs provide standardised access to data or services over the Internet.
Some very useful Open APIs include:
TradeWatch – Real-time financial market data
SearchApi – Real-time Google SERP API
TwitterApi.io – Access real-time and historical data
Instagram Post Generator – Generate posts with templates from popular IG pages
Partner APIs
Partner APIs are shared with specific business partners and often require authentication and agreements. They perform essential functions for businesses and applications.
For example, a payment API like Paystack directly communicates with service providers and banking platforms to process payments for products and services.
Internal APIs
Internal APIs are used for internal communication within an organisation. They enable integration and streamline internal processes. Internal teams use the API to access and share data between their applications. The API is not exposed to the public, ensuring that sensitive business logic remains secure.
An example is a company’s internal API that connects its HR, payroll, and project management systems.
Composite APIs
Composite APIs combine multiple API calls into a single request. They are instrumental in microservices architectures, where a single operation may require data from several services. A single API call triggers requests to multiple underlying APIs, and the composite API then combines the responses and returns a unified result.
For example, an e-commerce platform might use a composite API to fetch product details, pricing, and inventory information in one go, reducing latency and simplifying the integration process.
Types of API Architecture
APIs are structured differently depending on use case, scalability, security, and accessibility. There are multiple ways to structure an API, but we will only focus on the most prevalent architectural styles used in Web development. They include:
REST
SOAP
GraphQL
gRPC
REST APIs
Representational State Transfer (REST) is an architectural style that uses HTTP methods (POST, GET, PUT, DELETE) to perform CRUD (Create, Read, Update, Delete) operations on resource-based URIs.
REST APIs are built with frameworks like Express.js (Node.js), Django/Flask (Python), and Spring Boot (Java).
Key Components
Resources and endpoints:
The entities exposed by the API can include anything: users, products, documents, and so on.
Each resource is identified by a unique URI (Uniform Resource Identifier).
HTTP methods:
GET: Retrieves a resource.
POST: Creates a new resource.
PUT: Updates an existing resource.
DELETE: Removes a resource.
PATCH: Partially updates an existing resource.
Data representation:
Resources can have multiple representations (for example, JSON, XML).
The API responds with the requested representation, allowing data to be structured and parsed easily.
HTTP headers and query parameters:
HTTP headers provide additional information about the request or response.
They can be used for authentication, content negotiation, and other purposes.
Statelessness:
Each request from a client to a server must contain all the information needed to understand and process the request.
The server does not store any client state between requests.
Other notable components are cacheability, HTTP Status, and HATEOAS. Together, these components define the structure and behaviour of RESTful systems, enabling seamless and efficient communication between clients and servers.
Operation Overview
REST APIs expose resources through unique URIs and let clients perform operations using HTTP methods such as GET, POST, PUT, DELETE, and PATCH. Clients can request data in various formats, such as JSON or XML, and include additional details through HTTP headers and query parameters.
Each request is stateless and contains all the information required for processing without relying on stored client data. The API also uses HTTP status codes, cacheability, and HATEOAS to manage responses and guide further interactions, ensuring a seamless and efficient communication framework between clients and servers.
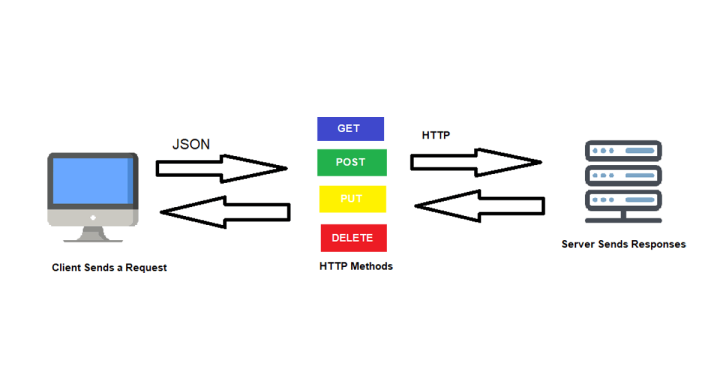
Practical Example and Real-world Use Cases
To illustrate how REST APIs work in practice, let’s consider a Book API that lets users manage a collection of books. Our example API has been created using the NodeJS and ExpressJS frameworks. I won’t explain how these frameworks actually work here, as that’s beyond the scope of this article. So if you don’t understand the syntax in the code below, don’t worry – just focus on the Requests and Responses logic.
This API follows REST principles by using standard HTTP methods to perform CRUD (Create, Read, Update, Delete) operations:
const express = require("express"); const bodyParser = require("body-parser");
const app = express(); app.use(bodyParser.json());
const app = express();
app.use(bodyParser.json());
// Dummy Database
let books = [
{ id: 1, title: "The Pragmatic Programmer", author: "Andy Hunt" },
{ id: 2, title: "Clean Code", author: "Robert C. Martin" },
];
// GET all books (Client requests, Server responds)
app.get("/books", (req, res) => res.json(books));
// GET a single book by ID
app.get("/books/:id", (req, res) => {
const book = books.find((b) => b.id === parseInt(req.params.id));
book ? res.json(book) : res.status(404).json({ message: "Not found" });
});
// POST a new book (Client sends data, Server updates database)
app.post("/books", (req, res) => {
const newBook = { id: books.length + 1, ...req.body };
books.push(newBook);
res.status(201).json(newBook);
});
// PUT (Update) a book
app.put("/books/:id", (req, res) => {
const book = books.find((b) => b.id === parseInt(req.params.id));
if (book) {
Object.assign(book, req.body);
res.json(book);
} else {
res.status(404).json({ message: "Not found" });
}
});
// DELETE a book
app.delete("/books/:id", (req, res) => {
const index = books.findIndex((b) => b.id === parseInt(req.params.id));
if (index !== -1) {
books.splice(index, 1);
res.json({ message: "Deleted" });
} else {
res.status(404).json({ message: "Not found" });
}
});
app.listen(3000, () => console.log("API running on port 3000"));
Here’s what’s going on in this code:
Client sends a request: A user (or frontend app) requests data using HTTP methods like GET, POST, PUT, or DELETE. Example: GET
/booksrequests all books or POST/booksposts a new book to the database.Server processes the request: The server receives the request, looks up the data (for example, from a database or in-memory array), and processes it.
Server sends a response: The server sends back a JSON response containing the requested data or a confirmation message. Here’s an example:
[
{ "id": 1, "title": "The Pragmatic Programmer", "author": "Andy Hunt" },
{ "id": 2, "title": "Clean Code", "author": "Robert C. Martin" }
]
- Client receives and uses the data: The frontend or another service consumes the API response and displays or processes it accordingly.
Teams utilize REST APIs for web services, mobile apps, and cloud integrations. Social media platforms fetch posts, while e-commerce sites retrieve product details. Payment gateways process transactions and weather apps access real-time forecasts. REST’s simplicity and scalability make it the preferred choice for public and internal APIs.
SOAP APIs
The Simple Object Access Protocol (SOAP) uses XML for messaging and includes built-in standards for security, transactions, and error handling. Its formal contract is defined by a WSDL (Web Services Description Language).
This architecture prioritises security and reliability through features like WS-Security and transaction management, making it suitable for complex enterprise applications that require rigid standards and robust error handling.
SOAP APIs are created using frameworks or tools such as Apache CXF, .NET WCF, and JAX-WS (Java).
Key Components
SOAP envelope:
This is the root element of a SOAP message and defines the overall structure of the XML document.
It contains the SOAP Header and SOAP Body.
SOAP body:
This section contains the actual data being exchanged between the client and server.
It includes the request or response messages, which are typically structured as XML elements.
WSDL (Web Services Description Language):
This is an XML document that describes the web service, including its operations, message formats, and data types.
It acts as a contract between the client and server, outlining how to interact with the API.
SOAP processor:
This is the software component that processes SOAP messages.
It parses the XML document, extracts the relevant data, and performs the requested operation.
There is also the SOAP Endpoint, which is the URL where the SOAP service can be accessed, and the XML Schema (XSD), which defines the structure and data types used in the SOAP message's XML.
Operation Overview
SOAP APIs operate by encapsulating data within an XML-based structure defined by a SOAP Envelope, which contains both a Header for metadata and a Body for the actual request or response information. The Body carries the exchange data, while a WSDL document serves as a contract detailing the service's operations, message formats, and data types.
A SOAP Processor then parses the XML, extracts relevant data, and executes the requested operations according to rules defined by an accompanying XML Schema (XSD). Communication with the service occurs through a specific SOAP Endpoint, ensuring a standardised, interoperable framework for web service interactions.
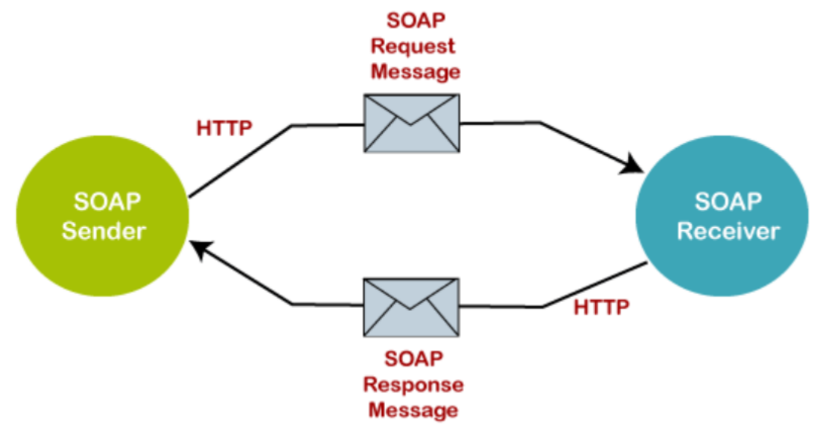
Practical Examples and Real-world Use Cases
To illustrate SOAP APIs and how they work practically, let’s consider a SOAP-based Banking Service API that provides secure operations for managing accounts and transactions. SOAP APIs use XML messaging to ensure secure and structured communication between systems. Creating a SOAP API and XML messaging is beyond the scope of this article, so here we’ll just focus on the Request and Response logic.
How it works:
- Retrieve account information: The client sends an XML request to fetch a user’s account details:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:bank="http://example.com/bank">
<soapenv:Header/>
<soapenv:Body>
<bank:GetAccountDetails>
<bank:AccountNumber>123456789bank:AccountNumber>
bank:GetAccountDetails>
soapenv:Body>
soapenv:Envelope>
The server responds with an XML message containing the account details:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Body>
<GetAccountDetailsResponse>
<AccountNumber>123456789AccountNumber>
<Balance>5000.00Balance>
<Currency>USDCurrency>
GetAccountDetailsResponse>
soapenv:Body>
soapenv:Envelope>
Process a money transfer: The client submits a transfer request with authentication details:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:bank="http://example.com/bank"> <soapenv:Header/> <soapenv:Body> <bank:TransferFunds> <bank:FromAccount>123456789bank:FromAccount> <bank:ToAccount>987654321bank:ToAccount> <bank:Amount>100.00bank:Amount> <bank:Currency>USDbank:Currency> bank:TransferFunds> soapenv:Body> soapenv:Envelope>If successful, the server returns a confirmation response:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"> <soapenv:Body> <TransferFundsResponse> <Status>SuccessStatus> <TransactionID>TXN987654TransactionID> TransferFundsResponse> soapenv:Body> soapenv:Envelope>
Banks, healthcare providers, and government agencies use SOAP for secure, reliable APIs. Financial institutions process transactions with strict authentication, while healthcare systems exchange patient data under compliance regulations. Airlines rely on SOAP for booking and ticketing, ensuring consistent data integrity across systems.
GraphQL APIs
GraphQL is a query language and runtime for APIs developed by Facebook. It allows clients to request exactly the data they need in a single request, reducing over-fetching and under-fetching.
Key Components
- Schema: This is the heart of a GraphQL API. It defines the structure of your data, including the types of objects, their fields, and their relationships. It acts as a contract between the client and server, specifying what data can be queried.
- Types: These define the structure of objects in your data. They specify the fields that each object has and the data types of those fields.
- Fields: These are the individual pieces of data that can be queried on an object.
- Queries: These are requests from the client to retrieve data. They specify the fields that the client wants to recover.
- Mutations: These are requests from the client to modify data (create, update, or delete).
- Resolvers: These are functions that fetch the data for each field in the schema. They connect the GraphQL schema to the underlying data sources.
- Subscriptions: These enable real-time updates. Clients can subscribe to specific events, and the server will push updates whenever they occur.
Operation Overview
GraphQL defines a schema that specifies available data types and their relationships. Clients then construct queries or mutations that precisely request the needed data fields. The GraphQL server processes these requests, using resolvers to fetch data from backend sources.
The server validates the request against the schema, executes the resolvers, and returns a JSON response containing only the requested data. Clients can establish subscriptions for real-time updates, enabling the server to push data changes as they occur. This approach minimises over-fetching and under-fetching, improving efficiency and flexibility in data retrieval.
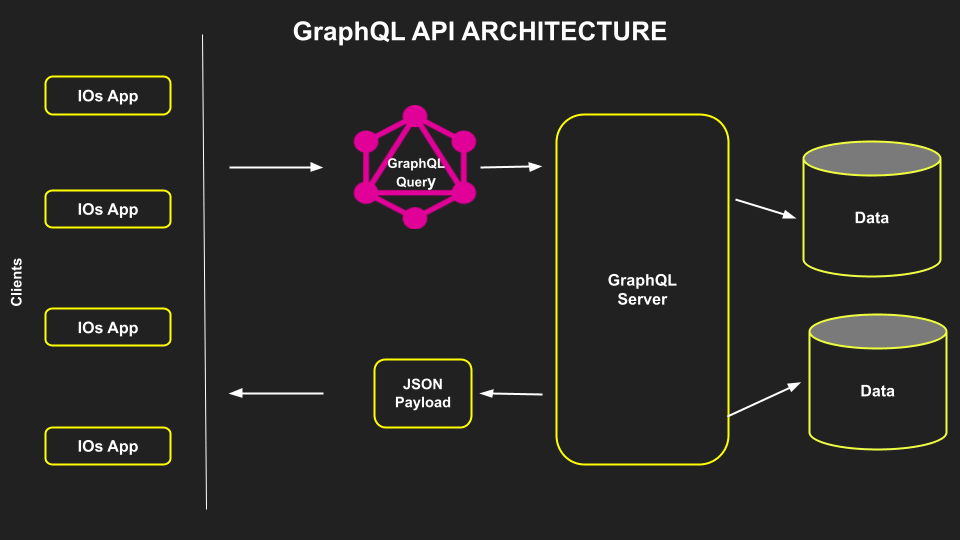
Practical Examples and Real-world Use Cases
Let’s explore how GraphQL APIs work practically by considering an E-commerce API powered by GraphQL. This API can efficiently fetch product details, reviews, and stock availability. The server is created using NodeJS and Apollo Server. Creating the server is beyond the scope of this article, so we will focus on the Schema (how a relational database is structured and visually represented) and the Request and Response logic.
- Schema:
# Schema (schema.graphql)
type Product {
id: ID!
name: String!
description: String
price: Float!
inventory: Int!
category: String!
}
type Query {
product(id: ID!): Product
products(category: String): [Product!]!
}
type Mutation {
createProduct(name: String!, description: String, price: Float!, inventory: Int!, category: String!): Product!
updateProductInventory(id: ID!, inventory: Int!): Product!
}
The Schema defines the data types (Product, Query, Mutation) and specifies the available queries (product, products), and mutations (createProduct, updateProductInventory). It uses the GraphQL type system (String, Int, Float, ID, [ ], !)
Requests and Response
Fetching product data - A client requests specific product fields (for example, name, price, and description):
query { product(id: "123") { name price description } }If it is successful, the server responds with only the requested data:
{ "data": { "product": { "name": "Wireless Headphones", "price": 99.99, "inStock": true } } }Create a new product:
mutation { createProduct(name: "Mouse", price: 30, inventory: 100, category: "Electronics") { id name price } }Update product information:
mutation { updateProduct(id: "123", price: 89.99) { name price } }If successful, the server returns the updated details:
{ "data": { "updateProduct": { "name": "Wireless Headphones", "price": 89.99 } } }
Companies like Facebook and Shopify use GraphQL for efficient, flexible APIs. E-commerce and social apps fetch only needed data, reducing over-fetching. Mobile apps optimize performance, while analytics tools aggregate complex data seamlessly.
gRPC APIs
Remote Procedure Call (gRPC) is a high-performance RPC framework that serialises structured data using HTTP/2 and Protocol Buffers. It supports synchronous and asynchronous communication and features like streaming.
HTTP/2 is the latest evolution of HTTP, designed with exciting features like binary framing, multiplexing, header compression, and server push to boost performance and reduce latency. gRPC takes full advantage of these capabilities, enabling quick, efficient, and simultaneous communication, which makes it a perfect fit for microservices and real-time applications.
Key Components
Service definition: This is defined in a .proto file. It specifies the services offered and the RPC methods available, acting as the contract between client and server.
Messages are data structures defined using Protocol Buffers, which efficiently serialise and deserialise data between systems.
Stubs: Auto-generated client and server code that lets the client call remote methods as if they were local and enables the server to implement the service logic.
Channels: These manage the connection between client and server, handling the underlying network communication.
RPC methods: gRPC supports different types of calls, including unary (single request-response), client streaming, server streaming, and bidirectional streaming, each suited for different use cases.
Interceptors and metadata: These provide mechanisms to add extra functionality, such as authentication, logging, and error handling, by attaching metadata to RPC calls.
Operation Overview
gRPC enables developers to define service contracts and message types in a .proto file with Protocol Buffers, serving as a blueprint for available RPC methods. The code generator produces client and server stubs, allowing remote procedures to be invoked like local functions, while channels manage HTTP/2-based network communication.
It supports unary, client streaming, server streaming, and bidirectional streaming for different data exchange patterns. Also, interceptors and metadata can be integrated for tasks like authentication and logging, keeping the system robust, secure, and efficient.
Practical Examples and Real-world Use Cases
Let’s consider a ride-sharing application that uses gRPC for fast communication between clients (mobile apps) and backend services. gRPC uses binary serialization via protocol buffers (Protobuf) instead of text-based formats like JSON or XML. This makes network communication significantly faster and more efficient.
- The .proto file defines the API structure:
syntax = "proto3";
service RideService {
rpc RequestRide(RideRequest) returns (RideResponse);
rpc StreamRideUpdates(RideUpdateRequest) returns (stream RideUpdate);
}
message RideRequest {
string user_id = 1;
string pickup_location = 2;
string destination = 3;
}
message RideResponse {
string ride_id = 1;
string driver_name = 2;
string car_model = 3;
}
message RideUpdate {
string ride_id = 1;
string status = 2;
string driver_location = 3;
}
message RideUpdateRequest {
string ride_id = 1;
}
When a client sends a RideRequest, it is serialized into a compact binary format using Protobuf. This reduces payload size, speeds up transmission, and improves efficiency. The server deserializes it back into a structured object before processing.
Request and Response:
Requesting a ride: The client sends a ride request with the click of a button that entails:
{ "user_id": "U123", "pickup_location": "Central Park", "destination": "Times Square" }The server responds with driver details:
{ "ride_id": "R456", "driver_name": "John Doe", "car_model": "Toyota Prius" }You must be wondering why the requests and responses are displayed in JSON since gRPC doesn’t use text-based formats like JSON and XML. The compressed binary stream used in gRPC is not human-readable like JSON. It’s a compact, efficient encoding format that requires Protobuf deserialization under the hood to be understood. In compressed binary stream format, the request or response will look like this:
08 D2 04 12 0D 43 65 6E 74 72 61 6C 20 50 61 72 6B 1A 0B 54 69 6D 65 73 20 53 71 75 61 72 65Streaming ride updates: Once a ride is assigned, the server streams real-time updates to the client:
{ "ride_id": "R456", "status": "Driver on the way", "driver_location": "5th Avenue" }
Companies use gRPC for high-performance, real-time applications requiring efficient service communication. Tech giants like Google, Netflix, and Dropbox utilize gRPC for scalable microservices. Ride-sharing apps stream live driver locations, while fintech platforms manage secure, low-latency transactions. IoT systems and AI applications depend on gRPC for real-time data exchange and efficient interactions.
How to Choose an API Architecture
Selecting an API architecture involves balancing various factors, including performance, scalability, ease of use, and security, according to your project's specific needs.
REST is known for its simplicity and stateless design, which aids scalability and ease of use, but its security depends mainly on external measures like HTTPS and proper authentication mechanisms.
SOAP, while more complex, provides robust built-in security standards (like WS-Security) and reliable transactional support, making it suitable for enterprise environments.
GraphQL offers efficient data fetching and high performance by allowing clients to request only the data they need. Still, it may require additional security measures such as query depth limiting and proper authentication on the server side.
gRPC delivers exceptional performance and is ideal for microservices with real-time data needs. It leverages HTTP/2 and TLS for secure, efficient communication, though it has a steeper learning curve.
The table below summarises the features and tradeoffs between these architectures:
| Feature | REST | SOAP | GraphQL | gRPC |
| Performance | Moderate (Potential over-fetching of data) | Low | High | High |
| Scalability | High | Moderate | High | Very high (Efficient for microservices and real-time data) |
| Ease of use | Simple and widely adopted | Complex | Intuitive for clients (Server-side complexity may grow) | Steep learning curve |
| Security | Relies on external mechanisms (HTTPS, OAuth, and so on) | Strong built-in security via WS-Security and formal contracts | Requires additional measures (query validation, rate limiting) | High security with built-in TLS support and robust authentication protocols |
Conclusion and Future Trends
APIs have become a mainstay in modern software development, facilitating seamless communication and data exchange between diverse applications. Their impact is undeniable, from public APIs that fuel innovation to private APIs that streamline internal processes.
Understanding the various API architectures, like REST, SOAP, GraphQL, and gRPC, empowers developers to select the optimal approach for their specific needs, balancing performance, scalability, and ease of use.
Looking ahead, the API landscape is set for exciting changes. With AI-driven APIs, decentralized architectures, and improved security measures, we’ll see new ways to build and interact with software. The continuous evolution of API standards and the growth of low-code/no-code platforms are making API development more accessible to everyone.


![Learn fewer skills but go deeper - the Caleb Curry interview [Podcast #163]](https://cdn.hashnode.com/res/hashnode/image/upload/v1741377315559/585b915d-2390-45a7-9f4a-171dc134af5d.png?#)




