































































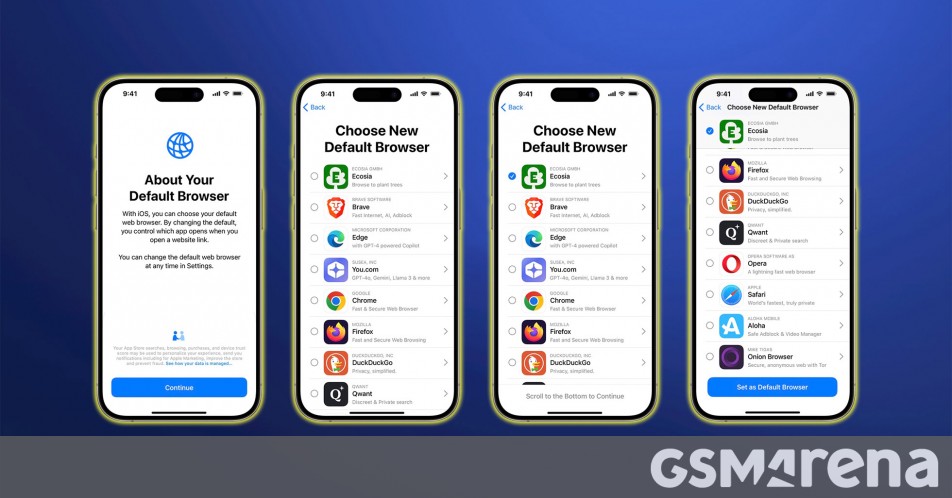
![Apple to Avoid EU Fine Over Browser Choice Screen [Report]](https://www.iclarified.com/images/news/96813/96813/96813-640.jpg)



















![iOS 18.4 Release Candidate comes bundled with over 50 new changes and features [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/03/iOS-18.4-Release-Candidate-Visual-Intelligence-Action-Button-iPhone-16e.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)






-xl-xl.jpg)














































































_alon_harel_Alamy.jpg?#)


































































![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)

























































































































































.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)
.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)

























































This AI Paper from UC Berkeley Introduces TULIP: A Unified Contrastive Learning Model for High-Fidelity Vision and Language Understanding
Recent advancements in artificial intelligence have significantly improved how machines learn to associate visual content with language. Contrastive learning models have been pivotal in this transformation, particularly those aligning images and text through a shared embedding space. These models are central to zero-shot classification, image-text retrieval, and multimodal reasoning. However, while these tools have pushed […] The post This AI Paper from UC Berkeley Introduces TULIP: A Unified Contrastive Learning Model for High-Fidelity Vision and Language Understanding appeared first on MarkTechPost.

Recent advancements in artificial intelligence have significantly improved how machines learn to associate visual content with language. Contrastive learning models have been pivotal in this transformation, particularly those aligning images and text through a shared embedding space. These models are central to zero-shot classification, image-text retrieval, and multimodal reasoning. However, while these tools have pushed boundaries in aligning high-level concepts between modalities, they still face challenges in processing more nuanced, spatially precise, and detailed visual information.
One of the major unresolved challenges lies in balancing semantic understanding with high-resolution visual recognition. Most existing contrastive models prioritize broad semantic alignment over spatial fidelity, causing them to underperform in tasks that require an understanding of object count, depth, fine-grained textures, or precise object locations. These limitations arise from how models are trained—often on large-scale, loosely labeled datasets—and optimization strategies that favor global feature matching over detailed visual analysis. The absence of spatially-aware representations hampers performance in more granular vision tasks.

Available models such as CLIP, ALIGN, and SigLIP have achieved strong performance on many classification and retrieval benchmarks. These models leverage large datasets to match image-text pairs in a contrastive manner, bringing semantically similar examples closer together in the embedding space. However, this focus often overlooks detailed representations crucial for specialized tasks. For instance, models trained with only image-text pairs may successfully describe what is present but struggle in tasks like counting distinct objects or distinguishing subtle variations between similar items. Vision-centric models like DINO or MAE offer strong feature extraction but lack language interpretability, making them less suitable for multimodal applications.
Researchers from the University of California, Berkeley, introduced a new model called TULIP (Towards Unified Language-Image Pretraining) to address these limitations. Designed as an open-source, plug-in replacement for existing CLIP-like models, TULIP enhances the integration of semantic alignment with high-fidelity visual representation. The innovation combines several contrastive learning techniques with generative data augmentation and reconstruction-based regularization. It is designed to preserve high-level understanding and fine-grained details, bridging the gap between language comprehension and detailed visual analysis.

TULIP’s methodology integrates three contrastive learning strategies: image-image, image-text, and text-text contrastive learning. This unified framework is powered by a module called GeCo (Generative Contrastive view augmentation), which uses large generative models to create challenging augmentations of images and text. These include semantically identical or subtly altered variations, generating positive and negative contrastive pairs. The image encoder leverages a vision transformer architecture with a masked autoencoder reconstruction loss, while the text encoder utilizes language models to paraphrase the content. Regularization objectives encourage the model to retain essential details like texture, layout, and color alongside semantics.
Performance benchmarks demonstrate that TULIP achieves notable improvements across various tasks. On ImageNet-1K zero-shot classification, TULIP reaches up to 89.6% accuracy, outperforming SigLIP by 2-3 percentage points across several datasets. In few-shot classification, it nearly doubles performance over SigLIP on RxRx1, increasing accuracy from 4.6% to 9.8%. On MMVP, a vision-language benchmark, TULIP improves performance over SigLIP by more than 3×. It also outperforms competing models on the Winoground benchmark, becoming the first CIT model to achieve better-than-random results on group-based reasoning tasks. BLINK evaluations lead to tasks like spatial reasoning and object localization, rivaling or surpassing some GPT-4-based systems.

This research provides a compelling solution to a fundamental multimodal learning tradeoff: achieving visual detail and semantic coherence. The research team has shown that introducing generative augmentations and multi-view contrastive techniques into pretraining significantly boosts the model’s capacity for complex visual and linguistic reasoning. TULIP sets a new direction for future vision-language systems that handle broad and fine-grained understanding in a unified model.
Check out the Paper, Project Page and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post This AI Paper from UC Berkeley Introduces TULIP: A Unified Contrastive Learning Model for High-Fidelity Vision and Language Understanding appeared first on MarkTechPost.







