
















































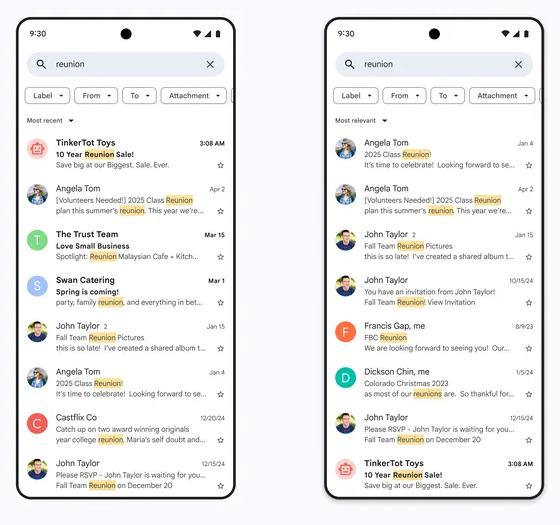

















![Redesigned Plastic Apple Watch SE in 'Serious Jeopardy' [Gurman]](https://www.iclarified.com/images/news/96789/96789/96789-640.jpg)
![Apple Watch to Gain Cameras in Future Models [Gurman]](https://www.iclarified.com/images/news/96790/96790/96790-640.jpg)
![Apple M4 Mac Mini on Sale for $499 [Lowest Price Ever]](https://www.iclarified.com/images/news/96788/96788/96788-640.jpg)
![Apple Shares First Look and Premiere Date for 'The Buccaneers' Season Two [Video]](https://www.iclarified.com/images/news/96786/96786/96786-640.jpg)






































































































_Federico_Caputo_Alamy.jpg?#)

































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)























































































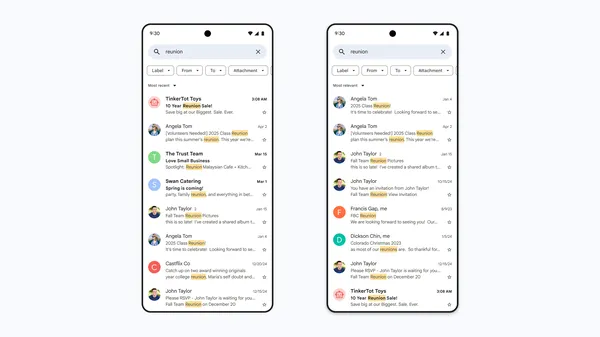




























![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)


































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






.png?#)












































OpenAI Introduced Advanced Audio Models ‘gpt-4o-mini-tts’, ‘gpt-4o-transcribe’, and ‘gpt-4o-mini-transcribe’: Enhancing Real-Time Speech Synthesis and Transcription Capabilities for Developers
The accelerating growth of voice interactions in the digital space has created increasingly high user expectations for effortless, natural-sounding audio experiences. Conventional speech synthesis and transcription technologies are usually beset by latency, unnaturalness, and insufficient real-time processing, making them unsuitable for realistic, user-centric applications. In response to these essential shortcomings, OpenAI has launched a collection […] The post OpenAI Introduced Advanced Audio Models ‘gpt-4o-mini-tts’, ‘gpt-4o-transcribe’, and ‘gpt-4o-mini-transcribe’: Enhancing Real-Time Speech Synthesis and Transcription Capabilities for Developers appeared first on MarkTechPost.

The accelerating growth of voice interactions in the digital space has created increasingly high user expectations for effortless, natural-sounding audio experiences. Conventional speech synthesis and transcription technologies are usually beset by latency, unnaturalness, and insufficient real-time processing, making them unsuitable for realistic, user-centric applications. In response to these essential shortcomings, OpenAI has launched a collection of audio models that aim to redefine the scope of real-time audio interactions.
OpenAI announced the release of three advanced audio models through its API, a significant advance in developers’ real-time audio processing abilities. Two models, which are aimed at speech-to-text use and one for text-to-speech, allow developers to build AI-powered agents that can create more natural, responsive, and personalized voice interactions.
The new suite comprises:
- ‘gpt-4o-mini-tts’
- ‘gpt-4o-transcribe’
- ‘gpt-4o-mini-transcribe’
Each model is engineered to address specific needs within audio interaction, reflecting OpenAI’s ongoing commitment to enhancing user experience across digital interfaces. The primary focus behind these innovations is incremental improvements and transformative shifts in how audio-based interactions are managed and integrated into applications.

The ‘gpt-4o-mini-tts’ model reflects OpenAI’s vision of equipping developers with tools to produce realistic speech from text inputs. In contrast to previous text-to-speech technology, the model provides much lower latency with high naturalism in voice responses. Based on OpenAI, ‘gpt-4o-mini-tts’ produces outstanding clarity of voice and natural speech patterns, perfect for dynamic conversation agents and interactive applications. This development’s impact is significant, enabling products like virtual assistants, audiobooks, and real-time translation devices to provide experiences that closely resemble authentic human speech.
Simultaneously, two speech-to-text transcription models optimized for performance are ‘gpt-4o-transcribe’ and its less computationally intensive variant, ‘gpt-4o-mini-transcribe’. Both models are optimized for real-time transcription tasks, each tailored to different use cases. ‘gpt-4o-transcribe’ is designed for situations requiring higher accuracy and is best suited for applications with noisy or complicated dialogues or backgrounds. It has better accuracy than its predecessor models and provides high-quality transcription under adverse acoustic conditions. On the other hand, ‘gpt-4o-mini-transcribe’ supports quick, low-latency transcription. It is best used when speed and reduced latency are critical, such as voice-enabled IoT devices or real-time interaction systems.

By offering ‘mini’ versions of their state-of-the-art models, OpenAI allows developers operating in more limited environments, like mobile devices or edge devices, still to utilize advanced audio processing functionality without high resource overhead. This new development extends OpenAI’s current capabilities, especially after the huge success of earlier models like GPT-4 and Whisper. Whisper had already established new standards of transcription accuracy before, and GPT-4 transformed conversational AI capabilities. The current audio models extend these capabilities to the audio space, adding advanced voice processing capabilities alongside text-based AI functions.
In conclusion, applications utilizing ‘gpt-4o-mini-tts’, ‘gpt-4o-transcribe’, and ‘gpt-4o-mini-transcribe’ are poised to see gains in user interaction and functionality overall. Real-time audio processing with better accuracy and less lag puts these tools potentially ahead of the game for many use cases requiring responsiveness and transparency in audio messaging.
Check out the Technical details. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
The post OpenAI Introduced Advanced Audio Models ‘gpt-4o-mini-tts’, ‘gpt-4o-transcribe’, and ‘gpt-4o-mini-transcribe’: Enhancing Real-Time Speech Synthesis and Transcription Capabilities for Developers appeared first on MarkTechPost.






