![Apple Shares New Ad for iPhone 16: 'Trust Issues' [Video]](https://www.iclarified.com/images/news/97125/97125/97125-640.jpg)


![At Least Three iPhone 17 Models to Feature 12GB RAM [Kuo]](https://www.iclarified.com/images/news/97122/97122/97122-640.jpg)












![Hands-on: Motorola’s new trio of Razr phones are beautiful, if familiar vessels for AI [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/motorola-razr-2025-family-9.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![The big yearly Android upgrade doesn’t matter all that much now [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/04/Android-versions-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



![Apple appealing $570M EU fine, White House says it won’t be tolerated [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/Apple-says-570M-EU-fine-is-unfair-White-House-says-it-wont-be-tolerated.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)





















































































_NicoElNino_Alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)
_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)























































































































![API design for precomputation cache [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)























































.jpg?#)























































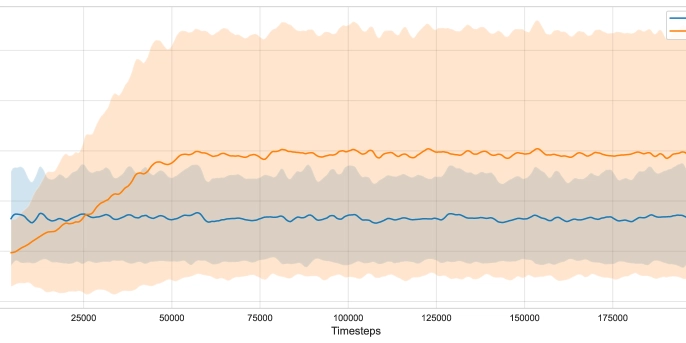
RL Beats Randomness: Dual-Critic PPO for Unpredictable Worlds
This is a Plain English Papers summary of a research paper called RL Beats Randomness: Dual-Critic PPO for Unpredictable Worlds. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview PD-PPO (Post-Decision Proximal Policy Optimization) is a new reinforcement learning method for environments with stochastic variables Uses dual critic networks to handle uncertainty better than standard methods Combines post-decision state formulation with PPO architecture Outperforms PPO and SAC in grid world and smart charging environments Particularly effective in environments with high randomness Plain English Explanation Imagine you're playing a video game where random events keep happening. Maybe you're driving a car and the weather keeps changing unpredictably, affecting how your car handles. Traditional reinforcement learning methods struggle in these situations because they don't handle ran... Click here to read the full summary of this paper
This is a Plain English Papers summary of a research paper called RL Beats Randomness: Dual-Critic PPO for Unpredictable Worlds. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- PD-PPO (Post-Decision Proximal Policy Optimization) is a new reinforcement learning method for environments with stochastic variables
- Uses dual critic networks to handle uncertainty better than standard methods
- Combines post-decision state formulation with PPO architecture
- Outperforms PPO and SAC in grid world and smart charging environments
- Particularly effective in environments with high randomness
Plain English Explanation
Imagine you're playing a video game where random events keep happening. Maybe you're driving a car and the weather keeps changing unpredictably, affecting how your car handles. Traditional reinforcement learning methods struggle in these situations because they don't handle ran...