




























































![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)
![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)

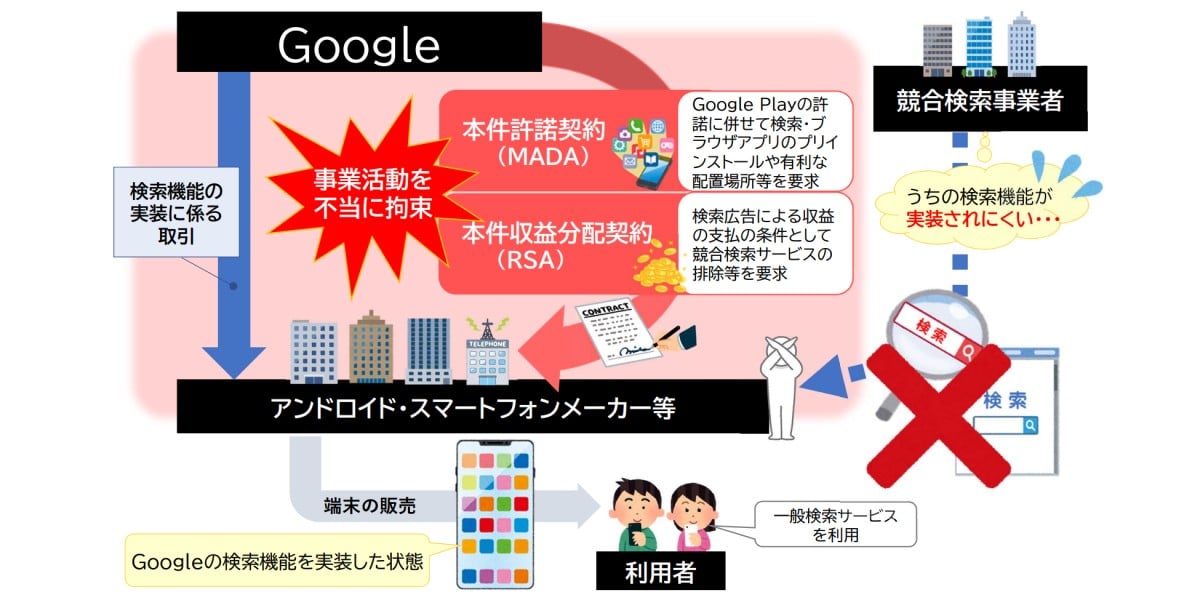


























































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






























































































































































































































Time Series Forecasting Made Simple (Part 1): Decomposition and Baseline Models
Learn the intuition behind time series decomposition, additive vs. multiplicative models and build your first forecasting baseline model using Python The post Time Series Forecasting Made Simple (Part 1): Decomposition and Baseline Models appeared first on Towards Data Science.

I
But here’s what I’ve learned: any complex topic becomes manageable when we start from the basics and focus on understanding the intuition behind it. That’s exactly what this blog series is about : making time series feel less like a maze and more like a conversation with your data over time.
We understand complex topics much more easily when they’re explained through real-world examples. That’s exactly how I’ll approach this series.
In each post, we’ll work with a simple dataset and explore what’s needed from a time series perspective. We’ll build intuition around each concept, understand why it matters, and implement it step by step on the data.
Time Series Analysis is the process of understanding, modeling and Forecasting data that is observed over time. It involves identifying patterns such as trends, seasonality and noise using past observations to make informed predictions about future values.
Let’s start by considering a dataset named Daily Minimum Temperatures in Melbourne (
Date: The calendar day (from 1981-01-01 to 1990-12-31)
Temp: The minimum temperature recorded on that day
You’ve probably heard of models like ARIMA, SARIMA or Exponential Smoothing. But before we go there, it’s a good idea to try out some simple baseline models first, to see how well a basic approach performs on our data.
While there are many types of baseline models used in time series forecasting, here we’ll focus on the three most essential ones, which are simple, effective, and widely applicable across industries.
Naive Forecast: Assumes the next value will be the same as the last observed one.
Seasonal Naive Forecast: Assumes the value will repeat from the same point last season (e.g., last week or last month).
Moving Average: Takes the average of the last n points.
You might be wondering, why use baseline models at all? Why not just go straight to the well-known forecasting methods like ARIMA or SARIMA?
Let’s consider a shop owner who wants to forecast next month’s sales. By applying a moving average baseline model, they can estimate next month’s sales as the average of previous months. This simple approach might already deliver around 80% accuracy — good enough for planning and inventory decisions.
Now, if we switch to a more advanced model like ARIMA or SARIMA, we might increase accuracy to around 85%. But the key question is: is that extra 5% worth the additional time, effort and resources? In this case, the baseline model does the job.
In fact, in most everyday business scenarios, baseline models are sufficient. We typically turn to classical models like ARIMA or SARIMA in high-impact industries such as finance or energy, where even a small improvement in accuracy can have a significant financial or operational impact. Even then, a baseline model is usually applied first — not only to provide quick insights but also to act as a benchmark that more complex models must outperform.
Okay, now that we’re ready to implement some baseline models, there’s one key thing we need to understand first:
Every time series is made up of three main components — trend, seasonality and residuals.
Time series decomposition separates data into trend, seasonality and residuals (noise), helping us uncover the true patterns beneath the surface. This understanding guides the choice of forecasting models and improves accuracy. It’s also a vital first step before building both simple and advanced forecasting solutions.
Trend
This is the overall direction your data is moving in over time — going up, down or staying flat.
Example: Steady decrease in monthly cigarette sales.
Seasonality
These are the patterns that repeat at regular intervals — daily, weekly, monthly or yearly.
Example: Cool drinks sales in summer.
Residuals (Noise)
This is the random “leftover” part of the data, the unpredictable ups and downs that can’t be explained by trend or seasonality.
Example: A one-time car purchase showing up in your monthly expense pattern.
Now that we understand the key components of a time series, let’s put that into practice using a real dataset: Daily Minimum Temperatures in Melbourne, Australia.
We’ll use Python to decompose the time series into its trend, seasonality, and residual components so we can better understand its structure and choose an appropriate baseline model.
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
# Load the dataset
df = pd.read_csv("minimum daily temperatures data.csv")
# Convert 'Date' to datetime and set as index
df['Date'] = pd.to_datetime(df['Date'], dayfirst=True)
df.set_index('Date', inplace=True)
# Set a regular daily frequency and fill missing values using forward fill
df = df.asfreq('D')
df['Temp'].fillna(method='ffill', inplace=True)
# Decompose the daily series (365-day seasonality for yearly patterns)
decomposition = seasonal_decompose(df['Temp'], model='additive', period=365)
# Plot the decomposed components
decomposition.plot()
plt.suptitle('Decomposition of Daily Minimum Temperatures (Daily)', fontsize=14)
plt.tight_layout()
plt.show()
Output:

The decomposition plot clearly shows a strong seasonal pattern that repeats each year, along with a mild trend that shifts over time. The residual component captures the random noise that isn’t explained by trend or seasonality.
In the code earlier, you might have noticed that I used an additive model for decomposing the Time Series. But what exactly does that mean — and why is it the right choice for this dataset?
Let’s break it down.
In an additive model, we assume Trend, Seasonality and Residuals (Noise) combine linearly, like this:
Y = T + S + R
Where:
Y is the actual value at time t
T is the trend
S is the seasonal component
R is the residual (random noise)
This means we’re treating the observed value as the sum of the parts, each component contributes independently to the final output.
I chose the additive model because when I looked at the pattern in daily minimum temperatures, I noticed something important:

The line plot above shows the daily minimum temperatures from 1981 to 1990. We can clearly see a strong seasonal cycle that repeats each year, colder temperatures in winter, warmer in summer.
Importantly, the amplitude of these seasonal swings stays relatively consistent over the years. For example, the temperature difference between summer and winter doesn’t appear to grow or shrink over time. This stability in seasonal variation is a key sign that the additive model is appropriate for decomposition, since the seasonal component appears to be independent of any trend.
We use an additive model when the trend is relatively stable and does not amplify or distort the seasonal pattern, and when the seasonality stays within a consistent range over time, even if there are minor fluctuations.
Now that we understand how the additive model works, let’s explore the multiplicative model — which is often used when the seasonal effect scales with the trend which will also help us understand the additive model more clearly.
Consider a household’s electricity consumption. Suppose the household uses 20% more electricity in summer compared to winter. That means the seasonal effect isn’t a fixed number — it’s a proportion of their baseline usage.
Let’s see how this looks with real numbers:
In 2021, the household used 300 kWh in winter and 360 kWh in summer (20% more than winter).
In 2022, their winter consumption increased to 330 kWh, and summer usage rose to 396 kWh (still 20% more than winter).
In both years, the seasonal difference grows with the trend from +60 kWh in 2021 to +66 kWh in 2022 even though the percentage increase stays the same. This is exactly the kind of behavior that a multiplicative model captures well.
In mathematical terms:
Y = T ×S ×R
Where:
Y: Observed value
T: Trend component
S: Seasonal component
R: Residual (noise)
By looking at the decomposition plot, we can figure out whether an additive or multiplicative model fits our data better.
There are also other powerful decomposition tools available, which I’ll be covering in one of my upcoming blog posts.Now that we have a clear understanding of additive and multiplicative models, let’s shift our focus to applying a baseline model that fits this dataset.
Based on the decomposition plot, we can see a strong seasonal pattern in the data, which suggests that a Seasonal Naive model might be a good fit for this time series.
This model assumes that the value at a given time will be the same as it was in the same period of the previous season — making it a simple yet effective choice when seasonality is dominant and consistent. For example, if temperatures typically follow the same yearly cycle, then the forecast for July 1st, 1990, would simply be the temperature recorded on July 1st, 1989.
Code:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# Load the dataset
df = pd.read_csv("minimum daily temperatures data.csv")
# Convert 'Date' column to datetime and set as index
df['Date'] = pd.to_datetime(df['Date'], dayfirst=True)
df.set_index('Date', inplace=True)
# Ensure regular daily frequency and fill missing values
df = df.asfreq('D')
df['Temp'].fillna(method='ffill', inplace=True)
# Step 1: Create the Seasonal Naive Forecast
seasonal_period = 365 # Assuming yearly seasonality for daily data
# Create the Seasonal Naive forecast by shifting the temperature values by 365 days
df['Seasonal_Naive'] = df['Temp'].shift(seasonal_period)
# Step 2: Plot the actual vs forecasted values
# Plot the last 2 years (730 days) of data to compare
plt.figure(figsize=(12, 5))
plt.plot(df['Temp'][-730:], label='Actual')
plt.plot(df['Seasonal_Naive'][-730:], label='Seasonal Naive Forecast', linestyle='--')
plt.title('Seasonal Naive Forecast vs Actual Temperatures')
plt.xlabel('Date')
plt.ylabel('Temperature (°C)')
plt.legend()
plt.tight_layout()
plt.show()
# Step 3: Evaluate using MAPE (Mean Absolute Percentage Error)
# Use the last 365 days for testing
test = df[['Temp', 'Seasonal_Naive']].iloc[-365:].copy()
test.dropna(inplace=True)
# MAPE Calculation
mape = np.mean(np.abs((test['Temp'] - test['Seasonal_Naive']) / test['Temp'])) * 100
print(f"MAPE (Seasonal Naive Forecast): {mape:.2f}%")Output:

To keep the visualization clear and focused, we’ve plotted the last two years of the dataset (1989–1990) instead of all 10 years.
This plot compares the actual daily minimum temperatures in Melbourne with the values predicted by the Seasonal Naive model, which simply assumes that each day’s temperature will be the same as it was on the same day one year ago.
As seen in the plot, the Seasonal Naive forecast captures the broad shape of the seasonal cycles quite well — it mirrors the rise and fall of temperatures throughout the year. However, it doesn’t capture day-to-day variations, nor does it respond to slight shifts in seasonal timing. This is expected, as the model is designed to repeat the previous year’s pattern exactly, without adjusting for trend or noise.
To evaluate how well this model performs, we calculate the Mean Absolute Percentage Error (MAPE) over the final 365 days of the dataset (i.e., 1990). We only use this period because the Seasonal Naive forecast needs a full year of historical data before it can begin making predictions.
Mean Absolute Percentage Error (MAPE) is a commonly used metric to evaluate the accuracy of forecasting models. It measures the average absolute difference between the actual and predicted values, expressed as a percentage of the actual values.
In time series forecasting, we typically evaluate model performance on the most recent or target time period — not on the middle years. This reflects how forecasts are used in the real world: we build models on historical data to predict what’s coming next.
That’s why we calculate MAPE only on the final 365 days of the dataset — this simulates forecasting for a future and gives us a realistic measure of how well the model would perform in practice.
A MAPE of 28.23%, which gives us a baseline level of forecasting error. Any model we build next — whether it’s customized or more advanced, should aim to outperform this benchmark.
A MAPE of 28.23% means that, on average, the model’s predictions were 28.23% off from the actual daily temperature values over the last year.
In other words, if the true temperature on a given day was 10°C, the Seasonal Naïve forecast might have been around 7.2°C or 12.8°C, reflecting a 28% deviation.
I’ll dive deeper into evaluation metrics in a future post.
In this post, we laid the foundation for time series forecasting by understanding how real-world data can be broken down into trend, seasonality, and residuals through decomposition. We explored the difference between additive and multiplicative models, implemented the Seasonal Naive baseline forecast and evaluated its performance using MAPE.
While the Seasonal Naive model is simple and intuitive, it comes with limitations especially for this dataset. It assumes that the temperature on any given day is identical to the same day last year. But as the plot and MAPE of 28.23% showed, this assumption doesn’t hold perfectly. The data displays slight shifts in seasonal patterns and long-term variations that the model fails to capture.
In the next part of this series, we’ll go further. We’ll explore how to customize a baseline model, compare it to the Seasonal Naive approach and evaluate which one performs better using error metrics like MAPE, MAE and RMSE.
We’ll also begin building the foundation needed to understand more advanced models like ARIMA including key concepts such as:
- Stationarity
- Autocorrelation and Partial Autocorrelation
- Differencing
- Lag-based modeling (AR and MA terms)
Part 2 will dive into these topics in more detail, starting with custom baselines and ending with the foundations of ARIMA.
Thanks for reading. I hope you found this post helpful and insightful.
The post Time Series Forecasting Made Simple (Part 1): Decomposition and Baseline Models appeared first on Towards Data Science.





