















![Apple Debuts Official Trailer for 'Murderbot' [Video]](https://www.iclarified.com/images/news/96972/96972/96972-640.jpg)
![Alleged Case for Rumored iPhone 17 Pro Surfaces Online [Image]](https://www.iclarified.com/images/news/96969/96969/96969-640.jpg)

![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)















![Refresh your iPhone in style with the TORRAS Ostand Fitness case [15% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/TARROS.webp?resize=1200%2C628&quality=82&strip=all&ssl=1)


















































































_jvphoto_Alamy.jpg?#)
















































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)
























































































































![QA - Best methods for getting large amount of test data into event consuming applications generated from an API application [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)








































































































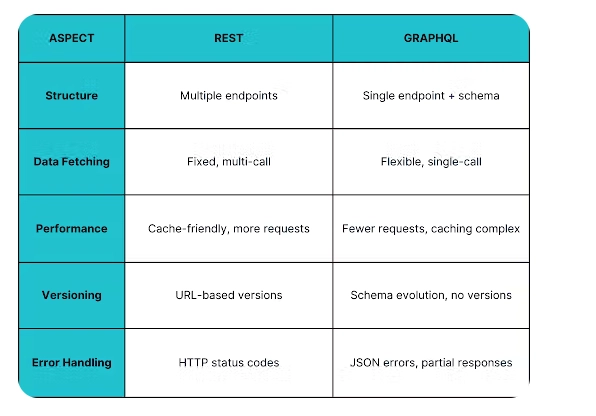
YOLOv12: The Next Evolution in Document Layout Analysis
Introduction Building upon the success of YOLOv11, which demonstrated significant improvements over YOLOv8 in document layout analysis, YOLOv12 introduces several architectural innovations and optimization techniques that further advance the field. I retrained the complete YOLOv12 series on the DocLayNet dataset. The project uses my codebase yolo-doclaynet. You can find all free models on huggingface, while the largest model is available here (trained using rented GPU resources). Key Improvements in YOLOv12 Area Attention Mechanism: This feature efficiently processes large receptive fields by dividing feature maps into equal-sized regions, typically 4. This approach maintains effectiveness while significantly reducing computational costs compared to standard self-attention. Residual Efficient Layer Aggregation Networks (R-ELAN): This improved feature aggregation module introduces block-level residual connections with scaling and a redesigned bottleneck-like structure for better optimization in large-scale attention models. Optimized Attention Architecture: This streamlined attention mechanism incorporates multiple efficiency improvements, including FlashAttention, removed positional encoding, and adjusted MLP ratios. It also uses a 7x7 separable convolution as a "position perceiver" and leverages strategic convolution operations. Experimental Results Using the DocLayNet dataset, we conducted comprehensive evaluations of all YOLOv12 variants compared to previous series such as YOLOv11 and YOLOv8. The results show that YOLOv12 significantly outperforms YOLOv8. Smaller YOLOv12 models (nano, small, and medium) also demonstrate substantial improvements over YOLOv11, though larger models (Large and Extra) show comparable performance. Performance Metrics The figure shows the comparative performance metrics (model size and mAP scores) across different YOLO versions, from YOLOv8 to YOLOv12, demonstrating the evolution and improvements in model efficiency. The table above compares model sizes (in millions of parameters) and mAP scores across different YOLO versions from v8 to v12. Size/Model YOLOv12 YOLOv11 YOLOv10 YOLOv9 YOLOv8 Nano 2.6M/0.756 2.6M/0.735 2.3M/0.730 2.0M/0.737 3.2M/0.718 Small 9.3M/0.782 9.4M/0.767 7.2M/0.762 7.2M/0.766 11.2M/0.752 Medium 20.2M/0.788 20.1M/0.781 15.4M/0.780 20.1M/0.775 25.9M/0.775 Large 26.4M/0.792 25.3M/0.793 24.4M/0.790 25.5M/0.782 43.7M/0.783 Extra 59.1M/0.794 56.9M/0.794 29.5M/0.793 - 68.2M/0.787 Key Findings Consistent Small Model Improvements: YOLOv12 shows notable performance gains in nano through medium variants, with mAP improvements of up to 0.021 points compared to YOLOv11. Efficient Area Attention: The new Area Attention Mechanism successfully reduces computational complexity while maintaining high accuracy, particularly evident in the nano and small models. Parameter Efficiency: YOLOv12 achieves superior or comparable performance with significantly fewer parameters than YOLOv8, with the large model using only 26.4M parameters compared to YOLOv8's 43.7M. Competitive Large Model Performance: Larger variants (Large and Extra) maintain performance parity with YOLOv11, demonstrating mAP scores of 0.792 and 0.794 respectively. Conclusion YOLOv12 represents a significant step forward in document layout analysis, offering improved accuracy and efficiency across all model sizes. The series demonstrates particular strength in handling complex document structures while maintaining real-time performance capabilities. The nano and small models show substantial improvements with minimal computational cost, making them ideal for mobile devices and other edge computing applications requiring document layout analysis.
Introduction
Building upon the success of YOLOv11, which demonstrated significant improvements over YOLOv8 in document layout analysis, YOLOv12 introduces several architectural innovations and optimization techniques that further advance the field. I retrained the complete YOLOv12 series on the DocLayNet dataset.
The project uses my codebase yolo-doclaynet. You can find all free models on huggingface, while the largest model is available here (trained using rented GPU resources).
Key Improvements in YOLOv12
- Area Attention Mechanism: This feature efficiently processes large receptive fields by dividing feature maps into equal-sized regions, typically 4. This approach maintains effectiveness while significantly reducing computational costs compared to standard self-attention.
- Residual Efficient Layer Aggregation Networks (R-ELAN): This improved feature aggregation module introduces block-level residual connections with scaling and a redesigned bottleneck-like structure for better optimization in large-scale attention models.
- Optimized Attention Architecture: This streamlined attention mechanism incorporates multiple efficiency improvements, including FlashAttention, removed positional encoding, and adjusted MLP ratios. It also uses a 7x7 separable convolution as a "position perceiver" and leverages strategic convolution operations.
Experimental Results
Using the DocLayNet dataset, we conducted comprehensive evaluations of all YOLOv12 variants compared to previous series such as YOLOv11 and YOLOv8. The results show that YOLOv12 significantly outperforms YOLOv8. Smaller YOLOv12 models (nano, small, and medium) also demonstrate substantial improvements over YOLOv11, though larger models (Large and Extra) show comparable performance.
Performance Metrics
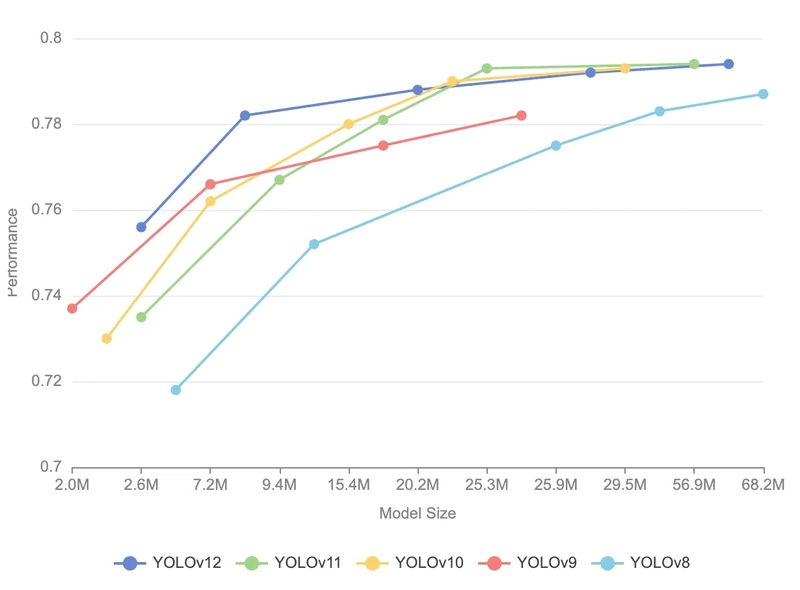
The figure shows the comparative performance metrics (model size and mAP scores) across different YOLO versions, from YOLOv8 to YOLOv12, demonstrating the evolution and improvements in model efficiency.
The table above compares model sizes (in millions of parameters) and mAP scores across different YOLO versions from v8 to v12.
| Size/Model | YOLOv12 | YOLOv11 | YOLOv10 | YOLOv9 | YOLOv8 |
|---|---|---|---|---|---|
| Nano | 2.6M/0.756 | 2.6M/0.735 | 2.3M/0.730 | 2.0M/0.737 | 3.2M/0.718 |
| Small | 9.3M/0.782 | 9.4M/0.767 | 7.2M/0.762 | 7.2M/0.766 | 11.2M/0.752 |
| Medium | 20.2M/0.788 | 20.1M/0.781 | 15.4M/0.780 | 20.1M/0.775 | 25.9M/0.775 |
| Large | 26.4M/0.792 | 25.3M/0.793 | 24.4M/0.790 | 25.5M/0.782 | 43.7M/0.783 |
| Extra | 59.1M/0.794 | 56.9M/0.794 | 29.5M/0.793 | - | 68.2M/0.787 |
Key Findings
- Consistent Small Model Improvements: YOLOv12 shows notable performance gains in nano through medium variants, with mAP improvements of up to 0.021 points compared to YOLOv11.
- Efficient Area Attention: The new Area Attention Mechanism successfully reduces computational complexity while maintaining high accuracy, particularly evident in the nano and small models.
- Parameter Efficiency: YOLOv12 achieves superior or comparable performance with significantly fewer parameters than YOLOv8, with the large model using only 26.4M parameters compared to YOLOv8's 43.7M.
- Competitive Large Model Performance: Larger variants (Large and Extra) maintain performance parity with YOLOv11, demonstrating mAP scores of 0.792 and 0.794 respectively.
Conclusion
YOLOv12 represents a significant step forward in document layout analysis, offering improved accuracy and efficiency across all model sizes. The series demonstrates particular strength in handling complex document structures while maintaining real-time performance capabilities.
The nano and small models show substantial improvements with minimal computational cost, making them ideal for mobile devices and other edge computing applications requiring document layout analysis.