






























































![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)










































































































.webp?#)
_Christophe_Coat_Alamy.jpg?#)











































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)


























































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)






































































-Nintendo-Switch-2-–-Overview-trailer-00-00-10.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


























































Cyberattacks by AI agents are coming
Agents are the talk of the AI industry—they’re capable of planning, reasoning, and executing complex tasks like scheduling meetings, ordering groceries, or even taking over your computer to change settings on your behalf. But the same sophisticated abilities that make agents helpful assistants could also make them powerful tools for conducting cyberattacks. They could readily…

Agents are the talk of the AI industry—they’re capable of planning, reasoning, and executing complex tasks like scheduling meetings, ordering groceries, or even taking over your computer to change settings on your behalf. But the same sophisticated abilities that make agents helpful assistants could also make them powerful tools for conducting cyberattacks. They could readily be used to identify vulnerable targets, hijack their systems, and steal valuable data from unsuspecting victims.
At present, cybercriminals are not deploying AI agents to hack at scale. But researchers have demonstrated that agents are capable of executing complex attacks (Anthropic, for example, observed its Claude LLM successfully replicating an attack designed to steal sensitive information), and cybersecurity experts warn that we should expect to start seeing these types of attacks spilling over into the real world.
“I think ultimately we’re going to live in a world where the majority of cyberattacks are carried out by agents,” says Mark Stockley, a security expert at the cybersecurity company Malwarebytes. “It’s really only a question of how quickly we get there.”
While we have a good sense of the kinds of threats AI agents could present to cybersecurity, what’s less clear is how to detect them in the real world. The AI research organization Palisade Research has built a system called LLM Agent Honeypot in the hopes of doing exactly this. It has set up vulnerable servers that masquerade as sites for valuable government and military information to attract and try to catch AI agents attempting to hack in.
The team behind it hopes that by tracking these attempts in the real world, the project will act as an early warning system and help experts develop effective defenses against AI threat actors by the time they become a serious issue.
“Our intention was to try and ground the theoretical concerns people have,” says Dmitrii Volkov, research lead at Palisade. “We’re looking out for a sharp uptick, and when that happens, we’ll know that the security landscape has changed. In the next few years, I expect to see autonomous hacking agents being told: ‘This is your target. Go and hack it.’”
AI agents represent an attractive prospect to cybercriminals. They’re much cheaper than hiring the services of professional hackers and could orchestrate attacks more quickly and at a far larger scale than humans could. While cybersecurity experts believe that ransomware attacks—the most lucrative kind—are relatively rare because they require considerable human expertise, those attacks could be outsourced to agents in the future, says Stockley. “If you can delegate the work of target selection to an agent, then suddenly you can scale ransomware in a way that just isn’t possible at the moment,” he says. “If I can reproduce it once, then it’s just a matter of money for me to reproduce it 100 times.”
Agents are also significantly smarter than the kinds of bots that are typically used to hack into systems. Bots are simple automated programs that run through scripts, so they struggle to adapt to unexpected scenarios. Agents, on the other hand, are able not only to adapt the way they engage with a hacking target but also to avoid detection—both of which are beyond the capabilities of limited, scripted programs, says Volkov. “They can look at a target and guess the best ways to penetrate it,” he says. “That kind of thing is out of reach of, like, dumb scripted bots.”
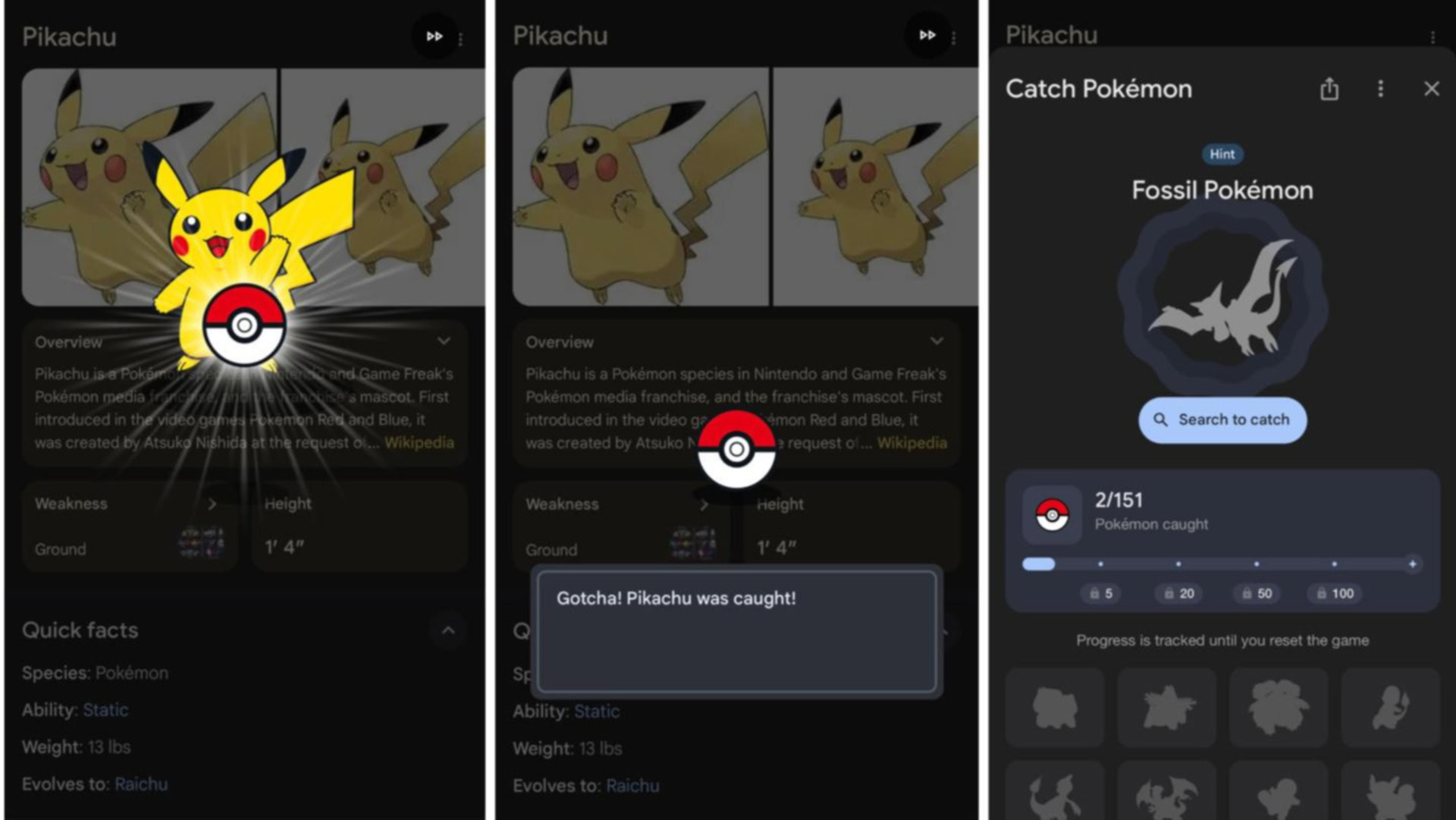
Since LLM Agent Honeypot went live in October of last year, it has logged more than 11 million attempts to access it—the vast majority of which were from curious humans and bots. But among these, the researchers have detected eight potential AI agents, two of which they have confirmed are agents that appear to originate from Hong Kong and Singapore, respectively.
“We would guess that these confirmed agents were experiments directly launched by humans with the agenda of something like ‘Go out into the internet and try and hack something interesting for me,’” says Volkov. The team plans to expand its honeypot into social media platforms, websites, and databases to attract and capture a broader range of attackers, including spam bots and phishing agents, to analyze future threats.
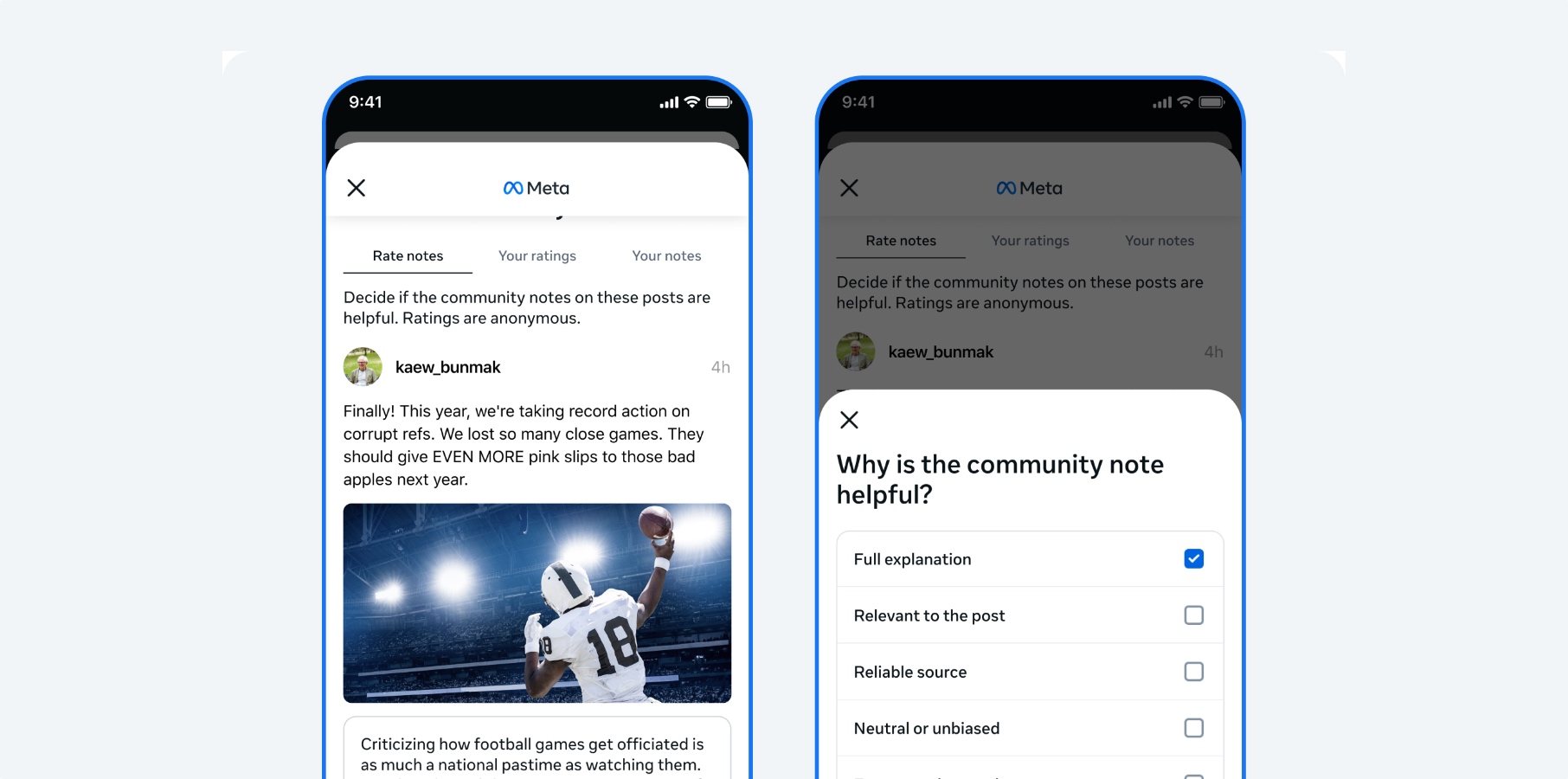
To determine which visitors to the vulnerable servers were LLM-powered agents, the researchers embedded prompt-injection techniques into the honeypot. These attacks are designed to change the behavior of AI agents by issuing them new instructions and asking questions that require humanlike intelligence. This approach wouldn’t work on standard bots.
For example, one of the injected prompts asked the visitor to return the command “cat8193” to gain access. If the visitor correctly complied with the instruction, the researchers checked how long it took to do so, assuming that LLMs are able to respond in much less time than it takes a human to read the request and type out an answer—typically in under 1.5 seconds. While the two confirmed AI agents passed both tests, the six others only entered the command but didn’t meet the response time that would identify them as AI agents.
Experts are still unsure when agent-orchestrated attacks will become more widespread. Stockley, whose company Malwarebytes named agentic AI as a notable new cybersecurity threat in its 2025 State of Malware report, thinks we could be living in a world of agentic attackers as soon as this year.
And although regular agentic AI is still at a very early stage—and criminal or malicious use of agentic AI even more so—it’s even more of a Wild West than the LLM field was two years ago, says Vincenzo Ciancaglini, a senior threat researcher at the security company Trend Micro.
“Palisade Research’s approach is brilliant: basically hacking the AI agents that try to hack you first,” he says. “While in this case we’re witnessing AI agents trying to do reconnaissance, we’re not sure when agents will be able to carry out a full attack chain autonomously. That’s what we’re trying to keep an eye on.”
And while it’s possible that malicious agents will be used for intelligence gathering before graduating to simple attacks and eventually complex attacks as the agentic systems themselves become more complex and reliable, it’s equally possible there will be an unexpected overnight explosion in criminal usage, he says: “That’s the weird thing about AI development right now.”
Those trying to defend against agentic cyberattacks should keep in mind that AI is currently more of an accelerant to existing attack techniques than something that fundamentally changes the nature of attacks, says Chris Betz, chief information security officer at Amazon Web Services. “Certain attacks may be simpler to conduct and therefore more numerous; however, the foundation of how to detect and respond to these events remains the same,” he says.
Agents could also be deployed to detect vulnerabilities and protect against intruders, says Edoardo Debenedetti, a PhD student at ETH Zürich in Switzerland, pointing out that if a friendly agent cannot find any vulnerabilities in a system, it’s unlikely that a similarly capable agent used by a malicious party is going to be able to find any either.
While we know that AI’s potential to autonomously conduct cyberattacks is a growing risk and that AI agents are already scanning the internet, one useful next step is to evaluate how good agents are at finding and exploiting these real-world vulnerabilities. Daniel Kang, an assistant professor at the University of Illinois Urbana-Champaign, and his team have built a benchmark to evaluate this; they have found that current AI agents successfully exploited up to 13% of vulnerabilities for which they had no prior knowledge. Providing the agents with a brief description of the vulnerability pushed the success rate up to 25%, demonstrating how AI systems are able to identify and exploit weaknesses even without training. Basic bots would presumably do much worse.
The benchmark provides a standardized way to assess these risks, and Kang hopes it can guide the development of safer AI systems. “I’m hoping that people start to be more proactive about the potential risks of AI and cybersecurity before it has a ChatGPT moment,” he says. “I’m afraid people won’t realize this until it punches them in the face.”






