


































![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)











































































































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)






























































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)


































































































Building a RAG System with Firebase Functions, OpenAI, and Pinecone
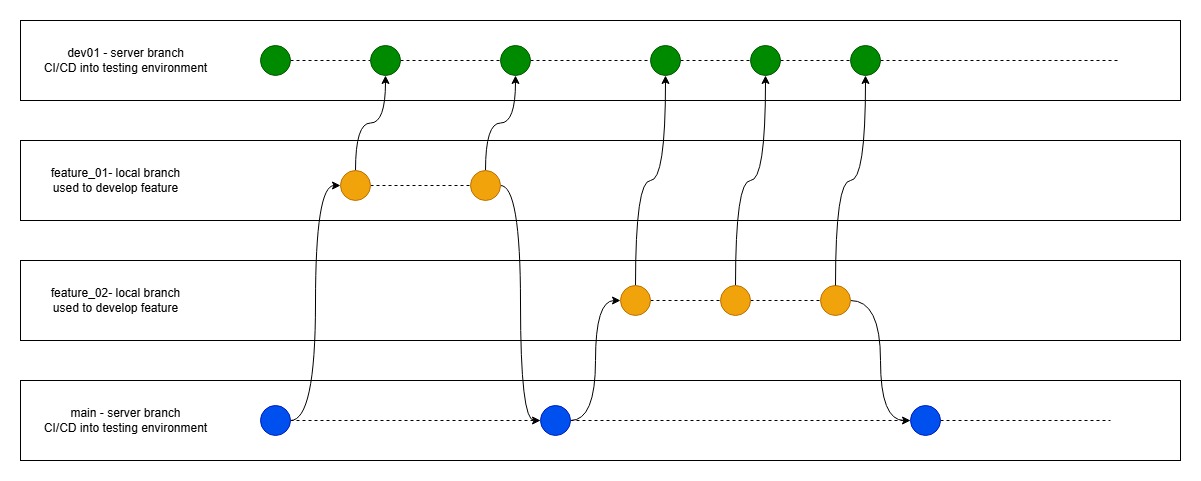
Few months back, I built the GenQL tool to generate SQL queries from natural text with the ability to provide context of database schema of my database to the AI. Here, I'm sharing the concepts of a basic RAG implementation that made it happen. Retrieval-Augmented Generation (RAG) is a powerful approach that combines large language models (LLMs) with external knowledge sources. In this project, I implemented a RAG system using Python, Firebase Functions, OpenAI for embeddings, and Pinecone as the vector database. The system exposes three main APIs: indexing data, searching, and deleting namespaces. Let’s break down the concepts behind each API. 1. Indexing Data: Turning Your Schema into Searchable Vectors Concept: Before you can search your data with natural language, you need to convert it into a format that a machine can understand and compare. This is done by transforming your data (like database schemas) into embeddings—numerical representations that capture the meaning of your text. These embeddings are then stored in a vector database. How it works: Describe your data: For each table in your schema, create a descriptive string that summarizes its name, columns, and descriptions. Generate embeddings: Use a model like OpenAI to turn these descriptions into vectors. Store in vector DB: Save these vectors in a vector database, organized by a namespace (like a project or user ID). Simplified code: # Pseudocode for indexing for each item in your_data: description = summarize(item) embedding = get_embedding(description) vector_db.upsert(id=item.id, vector=embedding, metadata=description, namespace=your_namespace) Why? This process makes your data searchable by meaning, not just by keywords. 2. Searching: Finding Relevant Data with Semantic Queries Concept: When a user asks a question, you want to find the most relevant pieces of your indexed data. This is done by converting the user’s query into an embedding and searching for the closest vectors in your database. How it works: Embed the query: Turn the user’s question into an embedding using the same model. Search the vector DB: Find the vectors (your indexed data) that are most similar to the query embedding. Return results: Fetch and return the metadata or original data associated with the closest vectors. Simplified code: # Pseudocode for searching query_embedding = get_embedding(user_query) results = vector_db.query(vector=query_embedding, top_k=5, namespace=your_namespace) return results Why? This allows users to ask questions in natural language and get relevant answers from your own data, even if the exact words don’t match. 3. Deleting a Namespace: Cleaning Up Concept: Since a particular namespace id is provided to your indexed schema in the database, you can remove all data associated with that id. This is done by deleting a namespace from your vector database. Simplified code: # Pseudocode for deleting a namespace vector_db.delete(namespace=your_namespace) Deployment: Firebase Functions in Python All these APIs are deployed as serverless functions using Firebase, making them easy to scale and integrate with other services. Conclusion By indexing your data as embeddings, searching with semantic queries, and managing namespaces, you can build a robust RAG system that brings the power of LLMs to your own datasets. This architecture is flexible and can be adapted to many use cases, from database documentation to knowledge management. GitHub repo: https://github.com/neetigyachahar/GenQL Happy hacking!

Few months back, I built the GenQL tool to generate SQL queries from natural text with the ability to provide context of database schema of my database to the AI. Here, I'm sharing the concepts of a basic RAG implementation that made it happen.
Retrieval-Augmented Generation (RAG) is a powerful approach that combines large language models (LLMs) with external knowledge sources. In this project, I implemented a RAG system using Python, Firebase Functions, OpenAI for embeddings, and Pinecone as the vector database. The system exposes three main APIs: indexing data, searching, and deleting namespaces. Let’s break down the concepts behind each API.
1. Indexing Data: Turning Your Schema into Searchable Vectors
Concept:
Before you can search your data with natural language, you need to convert it into a format that a machine can understand and compare. This is done by transforming your data (like database schemas) into embeddings—numerical representations that capture the meaning of your text. These embeddings are then stored in a vector database.
How it works:
- Describe your data: For each table in your schema, create a descriptive string that summarizes its name, columns, and descriptions.
- Generate embeddings: Use a model like OpenAI to turn these descriptions into vectors.
- Store in vector DB: Save these vectors in a vector database, organized by a namespace (like a project or user ID).
Simplified code:
# Pseudocode for indexing
for each item in your_data:
description = summarize(item)
embedding = get_embedding(description)
vector_db.upsert(id=item.id, vector=embedding, metadata=description, namespace=your_namespace)
Why?
This process makes your data searchable by meaning, not just by keywords.
2. Searching: Finding Relevant Data with Semantic Queries
Concept:
When a user asks a question, you want to find the most relevant pieces of your indexed data. This is done by converting the user’s query into an embedding and searching for the closest vectors in your database.
How it works:
- Embed the query: Turn the user’s question into an embedding using the same model.
- Search the vector DB: Find the vectors (your indexed data) that are most similar to the query embedding.
- Return results: Fetch and return the metadata or original data associated with the closest vectors.
Simplified code:
# Pseudocode for searching
query_embedding = get_embedding(user_query)
results = vector_db.query(vector=query_embedding, top_k=5, namespace=your_namespace)
return results
Why?
This allows users to ask questions in natural language and get relevant answers from your own data, even if the exact words don’t match.
3. Deleting a Namespace: Cleaning Up
Concept:
Since a particular namespace id is provided to your indexed schema in the database, you can remove all data associated with that id. This is done by deleting a namespace from your vector database.
Simplified code:
# Pseudocode for deleting a namespace
vector_db.delete(namespace=your_namespace)
Deployment: Firebase Functions in Python
All these APIs are deployed as serverless functions using Firebase, making them easy to scale and integrate with other services.
Conclusion
By indexing your data as embeddings, searching with semantic queries, and managing namespaces, you can build a robust RAG system that brings the power of LLMs to your own datasets. This architecture is flexible and can be adapted to many use cases, from database documentation to knowledge management.
GitHub repo: https://github.com/neetigyachahar/GenQL
Happy hacking!