

































































![Apple Developing AI 'Vibe-Coding' Assistant for Xcode With Anthropic [Report]](https://www.iclarified.com/images/news/97200/97200/97200-640.jpg)
![Apple's New Ads Spotlight Apple Watch for Kids [Video]](https://www.iclarified.com/images/news/97197/97197/97197-640.jpg)







































































































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)






























































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)




































































































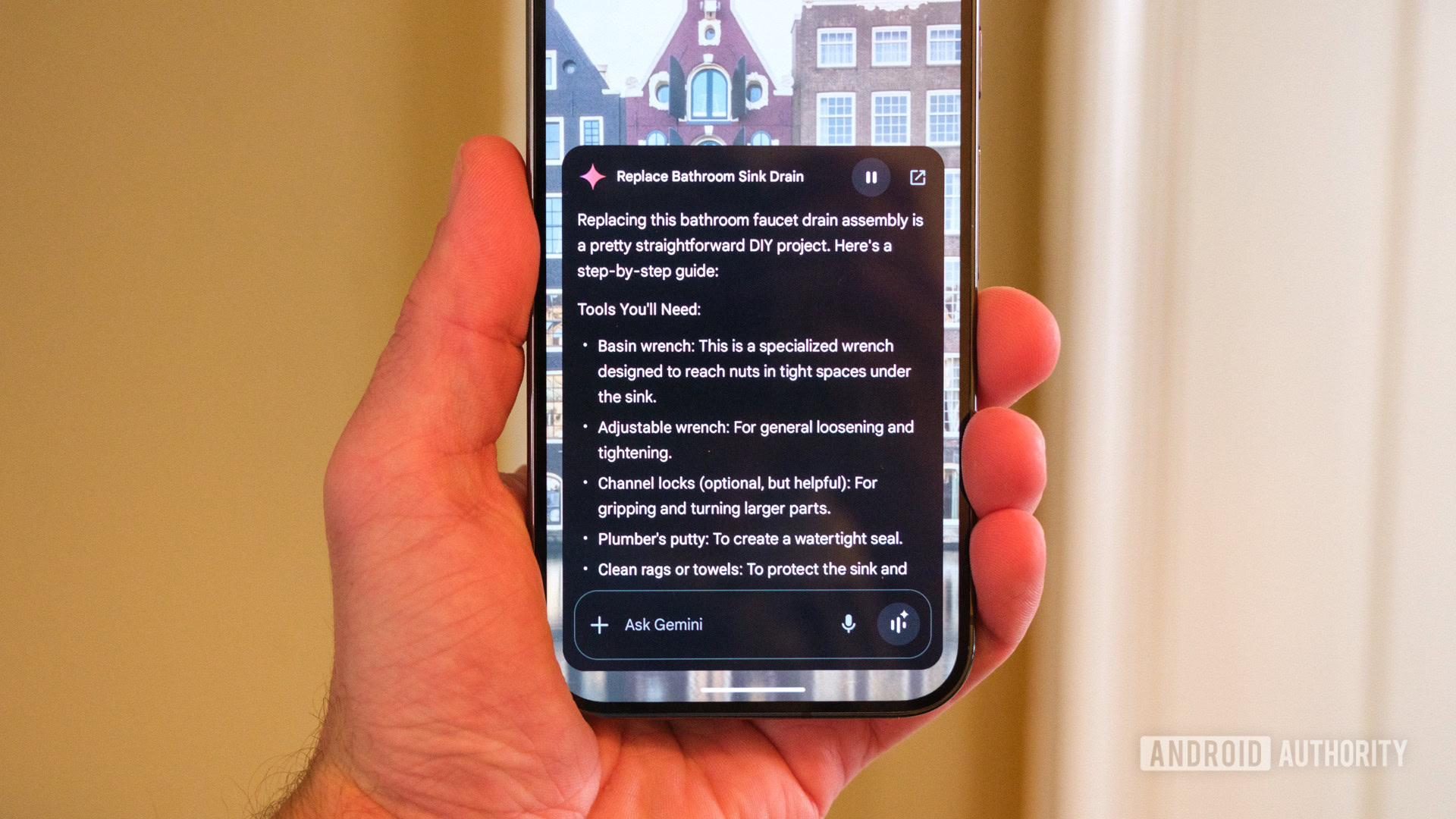
The Difference between Duplicate and Reference in Power Query
In Power Query, we can duplicate or reference existing tables. But what are the differences between them? Let's dive into it to find out. The post The Difference between Duplicate and Reference in Power Query appeared first on Towards Data Science.

Introduction
I may need to load the same data twice into Power Query and subsequently into Power BI.
This can happen when I must split the data columns or perform other transformations on the data, or when I need to extract data from a table in two different ways.
Power Query offers us two features to accomplish this:
- Duplicate:
This duplicates the M-Code for the table and creates a new table. - Reference:
This takes the output of a table and creates a new table. All changes made to the source table are also visible in the referencing table.
You might argue that when I use Reference, the data is read once from the source, as I take the output of one table and reuse it for a different output.
This is what this article is about: Is this true or false?
Preparing the Tools
I use SQL Server as the data source and SQL Profiler to analyze what happens in the database.
SQL Profiler is a Tool that can intercept all the traffic on a SQL Server instance.
Fortunately, SQL Profiler is part of SQL Server Management Studio (SSMS) and is free to use.
You can read this piece on Medium for a more detailed description of SQL Server Profiler: Mastering SQL Server Profiler: A Step-by-Step Guide to Unlocking Database Insights
Another way to analyze the behavior of these two Features is Power Query Diagnostics.
I wrote this piece on Medium about Power Query Diagnostics: Analyzing Power Query with Load Traces
I invite you to read it to find out more about this tool.
But let’s return to SQL Server Profiler and how to start it and prepare it for our specific scenario.
I can start SQL profile from the Start Menu or directly from SSMS:

After starting it, I must select the connection to my local SQL Server Instance:

Next, I set up the Trace.
- I give it a Name and select the TSQL template to track the queries coming from Power Query.
- I activate the “Save to File” option and select the folder for the Trace file.
I can later open this trace file in Profiler and look into it in more detail if I wish. - I switch to the second page, “Event Selection”
- I activate the two options “Show all events”.
- In the list of all Events, I select SQL:StmtStarting and SQL:StmtCompleted to get the SQL code from the queries.
- I deselect all events, except the three below SQL.
- I deselect most columns except those to track the Query Text, Start and End Time, Duration, and other statistics.
This is how it looks after the setup (With the option “Show all events” deactivated):

Lastly, I set up a filter on my source database to trace only the traffic on that database:

Without this filter, I will get the traffic on all databases. This will be overwhelming for a production instance as there will be a lot of traffic from other applications and users. I might even add a filter to restrict the trace to watch only for traffic from my NTUserName (My Windows User ID) to exclude all other traffic on the database.
Now I click on Run to start the Trace.
Importing the Data into Power Query
I use a View in the database named FactOnlineSales_withCustomer as my source.
I import this View into Power Query without any other transformation steps. This will cause Power Query to get the data with a simple SQL Query from the database.
I can find this query without difficulty in the Trace Log.
Create a Duplicate and check what happens.
After importing the data into Power Query, I create a Duplicate of the imported table and load the data into Power BI:

As expected, I see the same Query executed twice in SQL Profiler:

You can see that the data has been retrieved twice with the same number of rows (The last two lines in the trace.
I expected this to happen, as Duplicate copies the M-Code to create a new table.
Another key column is SPID. This is the internal session ID on the SQL Server instance. Two different SPIDs indicate that Power Query started to separate connections to get the data twice.
This column will be important when analyzing the traffic from a Referencing table.
Create a Reference and check what happens.
Now, I try the Reference feature.
I first delete the table “FactOnlineSales_WithCustomer_Duplicate” and create a Reference from the original “FactOnlineSales_WithCustomer” table:

In SQL Profiler, I can clear the view to see only new entries by clicking on the eraser button to clear the trace (This will not delete any data from the saved Trace file):

After refreshing the Data from Power BI, I get this result in SQL Profiler:

Astonishingly, the data was read twice in the database.
I can see that there are definitely two connections, as the column SPID (Session ID) has two different numbers for the two SQL:StmtCompleted entries.
This means that, from the load traffic perspective, there is no difference between duplicating and referencing a table.
But when both cause the same traffic on the source, why should I use Duplicate over Reference in Power Query?
When using Reference and when Duplicate
Some time ago, I wrote an article about converting a flat table to a Star Schema with Power Query: Converting a Flat Table to a Good Data Model in Power Query
In this article, I described that some operations are not possible when creating a new table by referencing an existing table.
For example, Power Query does not allow merging a referencing table with the original table because of a circular reference.
In such a case, I must duplicate the original table.
This is because a referencing table is always based on the last step of the referenced table.
This is the key difference between “Duplicate” and “Reference” in Power Query:
- Duplicate is an entirely new load without dependency on the original table. Changes to the original table do not affect the duplicated table.
- A Referencing table is based on the outcome of the referenced table. Consequently, changes applied to the referenced table are automatically applied to the referencing table.
To be precise, the changes are not applied, but the input table changes because of the change in the referenced table.
But when you need to extract a subset from the original table without changing the original table, Reference is the way to go, especially when it’s vital to always get the output from the referencing table.
If you want a table from the same source but don’t want changes to the original table applied to the new table, then you must duplicate the original table.
Be aware that Duplicate means a duplication of the Load logic. This means that when you apply a change to the original table, you might need to copy the logic to the duplicated table as well.
Potential for Conflicts during load
Another potential issue is that load conflicts can occur when loading data from some sources. Excel is one of these sources that can cause problems.
The source of the problem is that Power Query tries to load the data in parallel. Some sources are not able to handle parallel connections.
In such a case, you must change a parameter to avoid parallel loading:

The default value is four.
If problems occur, you might need to set either a lower Custom value or set it to “One (disable parallel loading)” to avoid any issues altogether.
Conclusion
In Power Query, there is no difference between “Duplicate” and “Reference” regarding load performance or network traffic.
Both load the data independently from the source with a separate connection.
Therefore, I debunked the myth that “Reference” can increase load performance.
However, knowing these two features’ differences is essential, as they offer distinct possibilities when loading and transforming data.
Anyway, when loading data from a relational database, I would create two queries or two views for the two tables, instead of offloading any transformation to Power Query.
According to Roche’s maxim of Data Transformation:
Data should be transformed as far upstream as possible, and as far downstream as necessary.
But when loading text, Excel files, or other sources to which I cannot send a query to get the data in the way I need it, I must use either “Duplicate” or “Reference” according to the required outcome.
References
Like in my previous articles, I use the Contoso sample dataset. You can download the ContosoRetailDW Dataset for free from Microsoft here.
The Contoso Data can be freely used under the MIT License, as described in this document.
I changed the dataset to shift the data to contemporary dates.
The post The Difference between Duplicate and Reference in Power Query appeared first on Towards Data Science.



