


























































![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)

![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)











![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














-xl-xl.jpg)


















































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)
















































































































![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)



























-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















































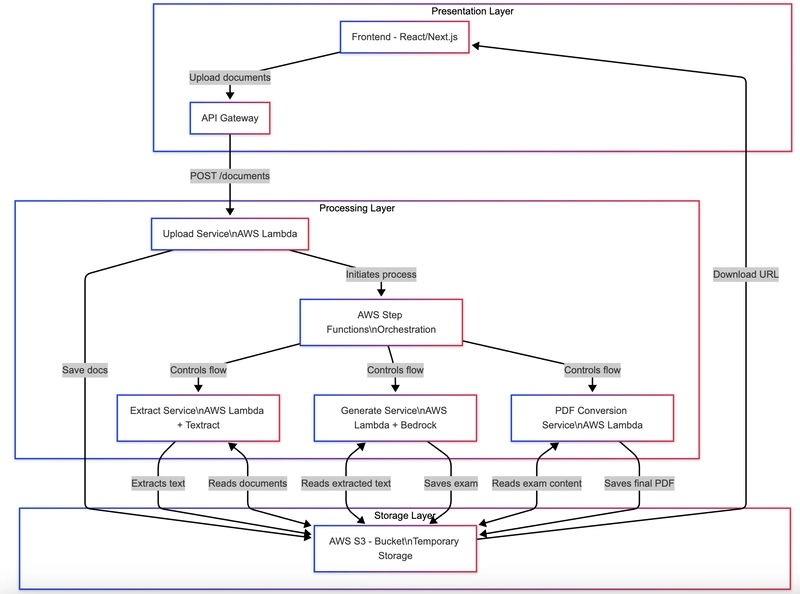
Building an Automated Notes Publishing Pipeline at Zero Cost
Disclaimer: it is an English translation of my Chinese post using Gemini, I really don't have time to write two versions of the same topic! At first, note two things: "Zero-cost" means "hard costs" excluding your time and effort. Cheers! "Note" is equivalent to "Summary". Have you ever found yourself overwhelmed by the sheer number of links while browsing online? I certainly have. These links can be anything that piques your interest, whether from someone's tweet, search results, or links within an article or video you're reading. I suspect this need is not uncommon, as "read it later" plugins or applications are ubiquitous. I tried a couple of them myself, but after the initial novelty wore off, I never used them again. This is because they (note: several years ago) were essentially just bookmark management tools, some with superfluous features like article recommendations. Given my already broad range of interests, leading to an overwhelming backlog of links, recommending even more articles seemed nonsense! An Impromptu Demand Years later, in this era of democratized AI (while I was engrossed in developing a personal TSW plugin), a thought suddenly struck me: why not use AI to process these links? After some initial brainstorming, I outlined the following requirements: Automatically generate a summary based on the currently open article. The summary format should include: keywords, overview, section summaries, in-text tool links, references, and the original article link. Export the summary. These requirements were purely based on my personal needs, as I wanted to: Quickly grasp the article's content to decide whether to continue reading. Have tool or reference links for easy access to related resources. Have the original article link for reference. Export the summary for convenient storage. However, being averse to repetitive tasks, I soon added new requirements after manually saving summaries for a while: Directly export the summary to my GitHub repository, rather than downloading it locally, manually committing it to the repository, and then syncing it to the remote repository. Create a summary site to share these summaries, facilitating my own reading and that of others (primarily my team members). Minimize costs, ideally incurring no expenses on these infrastructures. Zero-Cost Technical Solutions The above requirements can be broadly divided into three parts: Summary Generation Summary Export Summary Site Let's explore how to implement these three parts at zero cost. Summary Generation LLMs have significantly lowered the barrier to solving NLP problems. Today, you can easily generate summaries from text using any mature LLM provider's API. However, the devil is in the details, and to maximize the LLM's capabilities, you need to consider several factors. Link vs. Content My initial approach was to use links directly, prioritizing convenience. While it seemed acceptable at first, a closer look at the generated summaries revealed unsatisfactory results, often with fabricated information, ie hallucination. Thus, I reverted to the traditional method of parsing the link, extracting the content, and then feeding it into the LLM. LLM Selection To minimize or eliminate costs, the selection here involves two aspects: free tier and the context window size. Considering the "big three" at the time—OpenAI, Claude, and Gemini—let's temporarily ignore other vendors like Mistral. In terms of free tier: Gemini is the most generous. In terms of scenario: For processing general text, there's no significant difference among the three. In terms of the context window size: Gemini offers the largest capacity, simplifying development as the input is a single page's text, unlikely to exceed Gemini's limit even for lengthy articles, thus eliminating the need for chunking. However, this doesn't mean you can directly feed the webpage's HTML to Gemini. Considerations include: Webpages often contain noise like ads, navigation, and comments. For the main content, code snippets and images are generally irrelevant for summarization. Markdown (MD) format is the optimal input for LLMs. Therefore, the HTML underwent simple cleaning: Filtering irrelevant tags Using and tags Filtering irrelevant tags like Converting HTML to MD Using the turndown library This also offers the added benefit of reducing input length, allowing more summaries within the same quota. Note: Code, https://github.com/foxgem/tsw/blob/main/src/ai/utils.ts Summary Format This involves prompt engineering, which is straightforward. See the code directly: https://github.com/foxgem/tsw/blob/main/src/ai/ai.ts#L261 Overall infrastructure cost for these three steps: 0. Summary Export The requirement here is clear: use GitHub's free API with the octokit library. A GitHub Personal Access Token (PAT) is required, created via: settings -> devel

Disclaimer: it is an English translation of my Chinese post using Gemini, I really don't have time to write two versions of the same topic!
At first, note two things:
- "Zero-cost" means "hard costs" excluding your time and effort. Cheers!
- "Note" is equivalent to "Summary".
Have you ever found yourself overwhelmed by the sheer number of links while browsing online? I certainly have. These links can be anything that piques your interest, whether from someone's tweet, search results, or links within an article or video you're reading.
I suspect this need is not uncommon, as "read it later" plugins or applications are ubiquitous.
I tried a couple of them myself, but after the initial novelty wore off, I never used them again. This is because they (note: several years ago) were essentially just bookmark management tools, some with superfluous features like article recommendations. Given my already broad range of interests, leading to an overwhelming backlog of links, recommending even more articles seemed nonsense!
An Impromptu Demand
Years later, in this era of democratized AI (while I was engrossed in developing a personal TSW plugin), a thought suddenly struck me: why not use AI to process these links? After some initial brainstorming, I outlined the following requirements:
- Automatically generate a summary based on the currently open article.
- The summary format should include: keywords, overview, section summaries, in-text tool links, references, and the original article link.
- Export the summary.
These requirements were purely based on my personal needs, as I wanted to:
- Quickly grasp the article's content to decide whether to continue reading.
- Have tool or reference links for easy access to related resources.
- Have the original article link for reference.
- Export the summary for convenient storage.
However, being averse to repetitive tasks, I soon added new requirements after manually saving summaries for a while:
- Directly export the summary to my GitHub repository, rather than downloading it locally, manually committing it to the repository, and then syncing it to the remote repository.
- Create a summary site to share these summaries, facilitating my own reading and that of others (primarily my team members).
- Minimize costs, ideally incurring no expenses on these infrastructures.
Zero-Cost Technical Solutions
The above requirements can be broadly divided into three parts:
- Summary Generation
- Summary Export
- Summary Site
Let's explore how to implement these three parts at zero cost.
Summary Generation
LLMs have significantly lowered the barrier to solving NLP problems. Today, you can easily generate summaries from text using any mature LLM provider's API.
However, the devil is in the details, and to maximize the LLM's capabilities, you need to consider several factors.
Link vs. Content
My initial approach was to use links directly, prioritizing convenience.
While it seemed acceptable at first, a closer look at the generated summaries revealed unsatisfactory results, often with fabricated information, ie hallucination.
Thus, I reverted to the traditional method of parsing the link, extracting the content, and then feeding it into the LLM.
LLM Selection
To minimize or eliminate costs, the selection here involves two aspects: free tier and the context window size.
Considering the "big three" at the time—OpenAI, Claude, and Gemini—let's temporarily ignore other vendors like Mistral.
- In terms of free tier: Gemini is the most generous.
- In terms of scenario: For processing general text, there's no significant difference among the three.
- In terms of the context window size: Gemini offers the largest capacity, simplifying development as the input is a single page's text, unlikely to exceed Gemini's limit even for lengthy articles, thus eliminating the need for chunking.
However, this doesn't mean you can directly feed the webpage's HTML to Gemini. Considerations include:
- Webpages often contain noise like ads, navigation, and comments.
- For the main content, code snippets and images are generally irrelevant for summarization.
- Markdown (MD) format is the optimal input for LLMs.
Therefore, the HTML underwent simple cleaning:
- Filtering irrelevant tags
- Using
andtags - Filtering irrelevant tags like
- Using




