_Wavebreakmedia_Ltd_IFE-240611_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




































































![Netflix Unveils Redesigned TV Interface With Smarter Recommendations [Video]](https://www.iclarified.com/images/news/97249/97249/97249-640.jpg)

![Apple Seeds watchOS 11.5 RC to Developers [Download]](https://www.iclarified.com/images/news/97235/97235/97235-640.jpg)











































































































_Alexey_Kotelnikov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brian_Jackson_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)


































































































































































































.jpg?#)

























































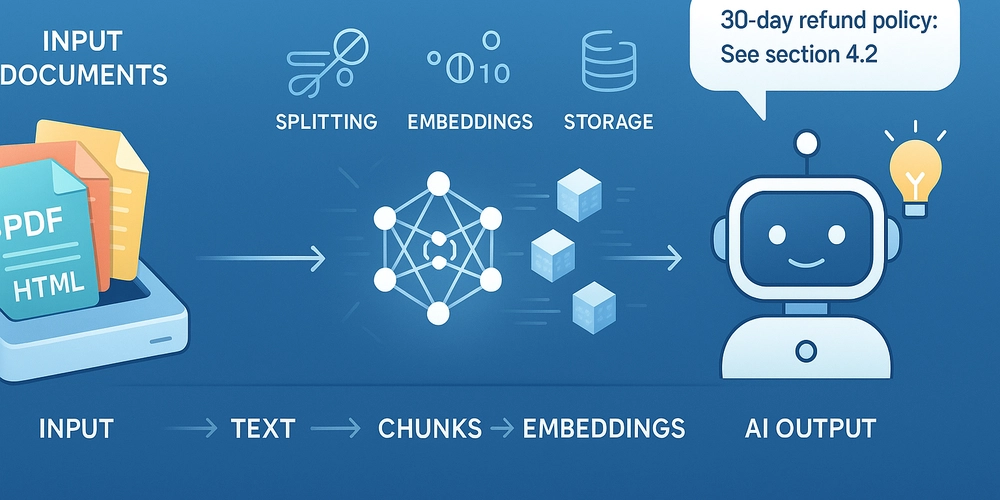
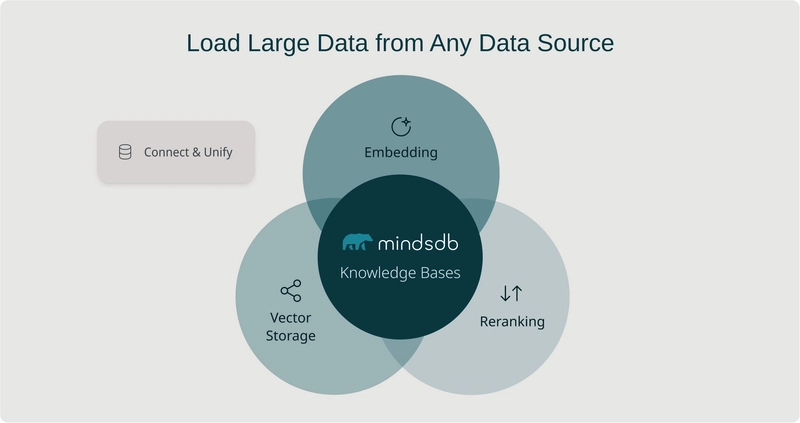
Enterprise Grade AI/ML Deployment on AWS 2025
AWS AI/ML deployment requires integrated infrastructure, deployment patterns, and optimization techniques Implementing production-scale AI/ML workloads on AWS in 2025 demands a comprehensive approach integrating sophisticated hardware selection, distributed training architectures, and custom security controls with advanced monitoring systems. This guide presents a complete financial fraud detection implementation showcasing AWS's latest ML services, infrastructure patterns, and optimization techniques that reduce cost by 40-70% while maintaining sub-100ms latency at scale. The most successful implementations use purpose-built accelerators (Trainium2/Inferentia2), infrastructure-as-code deployment, and multi-faceted security to create resilient, performant AI systems. 1. The modern AWS AI/ML ecosystem and service landscape The AI/ML landscape in 2025 has evolved dramatically from previous generations of tools and technologies. What was once a collection of disparate services has transformed into a cohesive ecosystem designed to address every stage of the machine learning lifecycle. This evolution reflects AWS's strategic response to the growing complexity of AI workloads and the increasing need for specialized infrastructure to support them. Organizations implementing AI/ML solutions today face fundamentally different challenges than even a few years ago. Models have grown exponentially in size and complexity, data volumes have exploded, and the expectations for real-time, scalable inference have increased. Understanding AWS's current AI/ML portfolio is essential for navigating these challenges effectively. Core service stack and technical capabilities AWS now offers three primary service categories for AI/ML workloads, each serving distinct use cases and technical requirements: SageMaker AI Platform has consolidated into a unified experience with several integrated components: SageMaker Unified Studio - Integrated environment for accessing all data and AI tools SageMaker HyperPod - Purpose-built infrastructure reducing foundation model training time by 40% SageMaker Inference - Optimized deployment reducing costs by 50% and latency by 20% SageMaker Clarify - Enhanced capabilities for evaluating foundation models SageMaker's evolution represents AWS's push toward streamlining the end-to-end ML development process. The platform has transformed from a collection of related tools into a cohesive system that handles the entire ML lifecycle. This consolidation addresses a key challenge in enterprise ML: the fragmentation of tooling and processes across different phases of development. The Unified Studio experience now serves as a central interface for data scientists and ML engineers, integrating previously separate tools for data preparation, model development, training, and deployment. HyperPod's specialized infrastructure particularly shines when working with large foundation models, where training efficiency gains translate directly to reduced time-to-market and lower costs. Bedrock has matured into a comprehensive generative AI platform with: Foundation Model Access - Over 100 foundation models from industry leaders Bedrock Data Automation - Extracting insights from unstructured multimodal content Agents for Bedrock - Automated planning and execution of multistep tasks Knowledge Bases for Bedrock - Managed RAG capability with GraphRAG support Bedrock represents AWS's response to the explosion of foundation models and generative AI. The service has evolved from simply providing access to foundation models to offering a complete platform for building generative AI applications. The addition of Agents for Bedrock is particularly significant, as it enables more complex AI applications that can autonomously plan and execute multi-step workflows—a capability that was largely theoretical just a few years ago. Knowledge Bases for Bedrock has also evolved significantly, now incorporating Graph-based Retrieval Augmented Generation (GraphRAG), which enhances the ability to retrieve contextual information by understanding relationships between data entities. This is crucial for applications that require nuanced understanding of complex domains. AWS continues offering specialized AI services for specific use cases: Amazon Fraud Detector - ML-based fraud identification Amazon Comprehend - Natural language processing Amazon Textract - Document processing Amazon Rekognition - Computer vision These specialized services provide pre-built ML capabilities for common use cases, allowing organizations to leverage sophisticated AI without deep ML expertise. Each service has been optimized for its specific domain, incorporating best practices and model architectures proven effective for these tasks. For example, Fraud Detector now incorporates temporal behavioral analysis and network effect detection, capabilities that would be extremely complex to build from scratch.

AWS AI/ML deployment requires integrated infrastructure, deployment patterns, and optimization techniques
Implementing production-scale AI/ML workloads on AWS in 2025 demands a comprehensive approach integrating sophisticated hardware selection, distributed training architectures, and custom security controls with advanced monitoring systems. This guide presents a complete financial fraud detection implementation showcasing AWS's latest ML services, infrastructure patterns, and optimization techniques that reduce cost by 40-70% while maintaining sub-100ms latency at scale. The most successful implementations use purpose-built accelerators (Trainium2/Inferentia2), infrastructure-as-code deployment, and multi-faceted security to create resilient, performant AI systems.
1. The modern AWS AI/ML ecosystem and service landscape
The AI/ML landscape in 2025 has evolved dramatically from previous generations of tools and technologies. What was once a collection of disparate services has transformed into a cohesive ecosystem designed to address every stage of the machine learning lifecycle. This evolution reflects AWS's strategic response to the growing complexity of AI workloads and the increasing need for specialized infrastructure to support them.
Organizations implementing AI/ML solutions today face fundamentally different challenges than even a few years ago. Models have grown exponentially in size and complexity, data volumes have exploded, and the expectations for real-time, scalable inference have increased. Understanding AWS's current AI/ML portfolio is essential for navigating these challenges effectively.
Core service stack and technical capabilities
AWS now offers three primary service categories for AI/ML workloads, each serving distinct use cases and technical requirements:
SageMaker AI Platform has consolidated into a unified experience with several integrated components:
- SageMaker Unified Studio - Integrated environment for accessing all data and AI tools
- SageMaker HyperPod - Purpose-built infrastructure reducing foundation model training time by 40%
- SageMaker Inference - Optimized deployment reducing costs by 50% and latency by 20%
- SageMaker Clarify - Enhanced capabilities for evaluating foundation models
SageMaker's evolution represents AWS's push toward streamlining the end-to-end ML development process. The platform has transformed from a collection of related tools into a cohesive system that handles the entire ML lifecycle. This consolidation addresses a key challenge in enterprise ML: the fragmentation of tooling and processes across different phases of development.
The Unified Studio experience now serves as a central interface for data scientists and ML engineers, integrating previously separate tools for data preparation, model development, training, and deployment. HyperPod's specialized infrastructure particularly shines when working with large foundation models, where training efficiency gains translate directly to reduced time-to-market and lower costs.
Bedrock has matured into a comprehensive generative AI platform with:
- Foundation Model Access - Over 100 foundation models from industry leaders
- Bedrock Data Automation - Extracting insights from unstructured multimodal content
- Agents for Bedrock - Automated planning and execution of multistep tasks
- Knowledge Bases for Bedrock - Managed RAG capability with GraphRAG support
Bedrock represents AWS's response to the explosion of foundation models and generative AI. The service has evolved from simply providing access to foundation models to offering a complete platform for building generative AI applications. The addition of Agents for Bedrock is particularly significant, as it enables more complex AI applications that can autonomously plan and execute multi-step workflows—a capability that was largely theoretical just a few years ago.
Knowledge Bases for Bedrock has also evolved significantly, now incorporating Graph-based Retrieval Augmented Generation (GraphRAG), which enhances the ability to retrieve contextual information by understanding relationships between data entities. This is crucial for applications that require nuanced understanding of complex domains.
AWS continues offering specialized AI services for specific use cases:
- Amazon Fraud Detector - ML-based fraud identification
- Amazon Comprehend - Natural language processing
- Amazon Textract - Document processing
- Amazon Rekognition - Computer vision
These specialized services provide pre-built ML capabilities for common use cases, allowing organizations to leverage sophisticated AI without deep ML expertise. Each service has been optimized for its specific domain, incorporating best practices and model architectures proven effective for these tasks. For example, Fraud Detector now incorporates temporal behavioral analysis and network effect detection, capabilities that would be extremely complex to build from scratch.
The infrastructure layer now features purpose-built AI acceleration:
- AWS Trainium2 - 4x performance over first-generation, optimized for training
- AWS Inferentia2 - 4x higher throughput and 10x lower latency than first-generation
- EC2 P5/P5e Instances - NVIDIA H100-based instances with petabit-scale networking
- AWS UltraClusters - Massively scalable infrastructure for distributed ML training
The evolution of AWS's AI infrastructure layer is perhaps the most significant advancement in the ecosystem. The transition from general-purpose computing to purpose-built accelerators represents a fundamental shift in how AI workloads are executed. Trainium2 and Inferentia2 reflect AWS's investment in custom silicon optimized specifically for ML workloads, providing significant performance and cost advantages over general-purpose GPUs for certain use cases.
The UltraClusters technology addresses one of the most challenging aspects of large-scale AI training: efficient communication between compute nodes. By providing petabit-scale networking and optimized topologies, UltraClusters enable near-linear scaling for distributed training, dramatically reducing the time required to train large models.
2. Real-world implementation: Financial fraud detection system
Building enterprise-scale AI applications requires moving beyond theoretical architecture to practical implementation. Financial fraud detection represents an ideal case study because it encompasses many of the challenges faced by production AI systems: real-time requirements, complex data relationships, high stakes outcomes, regulatory constraints, and the need for continuous adaptation.
The following implementation demonstrates how AWS's AI/ML ecosystem can be applied to create a sophisticated fraud detection system that meets stringent business and technical requirements.
Business requirements and technical constraints
Financial fraud detection presents unique challenges that require a sophisticated technical approach. The business requirements and technical constraints listed below represent real-world considerations that shape architectural decisions and implementation strategies.
GlobalFinance Inc., a multinational financial services corporation processing approximately 1 billion transactions daily (~$100B volume), faces sophisticated attack vectors including deepfake identity verification bypass and coordinated account takeover attempts. Their fraud detection system must:
- Process transactions in real-time (<100ms decision time)
- Scale to handle peak volumes (50,000 TPS)
- Maintain false positive rate <0.1% and false negative rate <0.05%
- Adapt to evolving fraud patterns without manual retraining
- Analyze heterogeneous data from multiple sources (transaction details, historical customer behavior, device information, biometric verification, threat intelligence)
- Comply with stringent regulatory requirements (PCI-DSS, GDPR, AML)
These requirements present significant technical challenges. The sub-100ms latency requirement is particularly demanding, as it must include the complete round trip: receiving the transaction, extracting features, running inference across multiple models, combining results, applying business rules, and returning a decision. This tight timeframe eliminates many traditional approaches to machine learning inference that introduce too much latency.
The scale requirement of 50,000 transactions per second (TPS) demands a highly distributed architecture that can horizontally scale to handle peak loads, which typically occur during holiday seasons or major shopping events. This throughput requirement drives decisions around data partitioning, load balancing, and infrastructure provisioning.
The false positive/negative constraints highlight the business impact of model accuracy. False positives (legitimate transactions incorrectly flagged as fraudulent) directly impact customer experience and revenue, while false negatives (fraudulent transactions incorrectly approved) result in financial losses and potential regulatory issues. Meeting these constraints requires sophisticated model architectures and ensemble approaches.
The need to analyze heterogeneous data from multiple sources introduces complexity in data ingestion, feature engineering, and model design. Some data sources (like transaction details) are structured, while others (like biometric verification) may contain unstructured elements. Integrating these diverse data types requires careful consideration of data pipelines and feature representation.
Modular, event-driven architecture
To address the business requirements and technical constraints, the implementation adopts a modular, event-driven architecture. This approach provides several advantages: components can be developed, deployed, and scaled independently; the system can evolve over time without complete redesign; and the event-driven nature enables real-time processing and rapid response to changing conditions.
The solution implements a multi-layered approach with these components:
- Real-time Transaction Scoring - ML models calculating fraud risk scores
- Behavioral Biometrics Analysis - Monitoring user behavior patterns
- Graph Network Analysis - Identifying suspicious relationships between accounts
- Adaptive Model Layer - Using reinforcement learning to improve detection
- Explainable Rules Engine - Providing human-understandable justifications
- Continuous Learning System - Automatically incorporating new fraud patterns
This architecture separates concerns and allows each component to utilize the most appropriate technologies for its specific function. For example, the Graph Network Analysis component employs specialized graph neural networks optimized for detecting complex relationships, while the Real-time Transaction Scoring component uses gradient-boosted trees for their efficiency and accuracy with tabular data.
The Explainable Rules Engine addresses an often-overlooked aspect of fraud detection: the need to provide clear explanations for why a transaction was flagged. This is crucial for regulatory compliance and for helping fraud analysts make informed decisions when reviewing flagged transactions.
The event-driven nature of the architecture leverages AWS services like Amazon Kinesis for real-time data streaming and AWS Lambda for serverless compute, enabling the system to scale automatically in response to transaction volume and to process events as they occur without batch delays.
Data ingestion and feature engineering implementation
Data ingestion and feature engineering form the foundation of any ML system. For fraud detection, these components must handle high-volume streaming data, extract meaningful features in real-time, and make those features available to multiple ML models with minimal latency.
The data ingestion layer uses multiple AWS services:
// Kinesis Stream Configuration for transaction ingest
{
"StreamName": "global-finance-transaction-stream",
"ShardCount": 100,
"RetentionPeriodHours": 48,
"StreamEncryption": {
"EncryptionType": "KMS",
"KeyId": "alias/fraud-detection-key"
}
}
This Kinesis configuration demonstrates several important considerations for high-volume data ingestion. The shard count of 100 is chosen to handle the peak load of 50,000 TPS, providing sufficient throughput capacity with headroom for unexpected traffic spikes. Each Kinesis shard can handle up to 1,000 records per second for writes, so 100 shards supports the required throughput while allowing for uneven distribution of traffic across shards.
The retention period of 48 hours enables replay of recent transactions if needed, which is valuable for debugging, model retraining, and recovery from downstream processing failures. Encryption using AWS KMS ensures that sensitive financial data is protected while in transit and at rest, addressing both security best practices and regulatory requirements like PCI-DSS.
Kinesis was chosen over other streaming options like Kafka or MSK because it provides seamless integration with other AWS services, managed scaling, and built-in encryption, reducing operational overhead while meeting the stringent requirements of financial data processing.
Feature engineering leverages SageMaker Feature Store for real-time feature management:
# Feature Store Configuration
import boto3
from sagemaker.feature_store.feature_group import FeatureGroup
feature_group_name = "transaction_features"
sagemaker_client = boto3.client('sagemaker')
feature_group = FeatureGroup(
name=feature_group_name,
sagemaker_session=sagemaker_session
)
feature_definitions = [
{"FeatureName": "transaction_id", "FeatureType": "String"},
{"FeatureName": "customer_id", "FeatureType": "String"},
{"FeatureName": "amount", "FeatureType": "Fractional"},
{"FeatureName": "merchant_id", "FeatureType": "String"},
{"FeatureName": "merchant_category", "FeatureType": "String"},
{"FeatureName": "transaction_time", "FeatureType": "String"},
{"FeatureName": "device_id", "FeatureType": "String"},
{"FeatureName": "ip_address", "FeatureType": "String"},
{"FeatureName": "location_lat", "FeatureType": "Fractional"},
{"FeatureName": "location_long", "FeatureType": "Fractional"},
{"FeatureName": "transaction_velocity_1h", "FeatureType": "Integral"},
{"FeatureName": "amount_velocity_24h", "FeatureType": "Fractional"}
]
feature_group.load_feature_definitions(feature_definitions)
feature_group.create(
s3_uri="s3://globalfinance-feature-store/transaction-features",
record_identifier_name="transaction_id",
event_time_feature_name="transaction_time",
role_arn="arn:aws:iam::123456789012:role/SageMakerFeatureStoreRole",
enable_online_store=True
)
This Feature Store configuration highlights the critical role of feature engineering in fraud detection. The feature definitions encompass various data types that contribute to fraud prediction:
- Identity features (transaction_id, customer_id, merchant_id) serve as keys for joining related data
- Transaction characteristics (amount, merchant_category) provide basic information about the transaction
- Contextual features (device_id, ip_address, location coordinates) help identify suspicious contexts
- Behavioral features (transaction_velocity_1h, amount_velocity_24h) capture patterns that might indicate fraud
The enable_online_store=True parameter is crucial for meeting the sub-100ms latency requirement. The online store provides low-latency, high-throughput access to the latest feature values, enabling real-time scoring of transactions. Meanwhile, the S3 URI configuration specifies the offline store location, which maintains historical feature values for training and analysis.
SageMaker Feature Store addresses several key challenges in ML feature engineering:
- Feature consistency: It ensures that the same feature definitions and transformations are used in both training and inference, preventing training-serving skew
- Feature reuse: Different models can access the same features, eliminating redundant computation
- Point-in-time correctness: It maintains feature history, allowing models to be trained on features as they existed at specific points in time
- Low-latency access: The online store provides sub-millisecond access to feature values, critical for real-time fraud detection
The transaction velocity and amount velocity features exemplify the importance of temporal patterns in fraud detection. These features capture how frequently a customer is transacting and the total transaction amount over different time windows, which can reveal unusual behavior patterns that might indicate fraud. Calculating these features requires maintaining state and processing streaming data, capabilities that Feature Store facilitates through its integration with Kinesis and its incremental feature calculation capabilities.
Model hierarchy and training pipeline implementation
Financial fraud detection benefits from a multi-model approach that captures different aspects of potentially fraudulent behavior. No single model can effectively identify all fraud patterns, so this implementation employs a hierarchical structure of specialized models, each focusing on different signals or patterns.
The solution employs multiple model types in a hierarchical structure:
- Primary Scoring Model: XGBoost ensemble trained on labeled transaction data
# XGBoost Primary Model Configuration
import sagemaker
from sagemaker.xgboost.estimator import XGBoost
hyperparameters = {
"max_depth": 6,
"eta": 0.2,
"gamma": 4,
"min_child_weight": 6,
"subsample": 0.8,
"objective": "binary:logistic",
"num_round": 100,
"verbosity": 1
}
xgb_estimator = XGBoost(
entry_point="fraud_detection_training.py",
hyperparameters=hyperparameters,
role=role,
instance_count=4,
instance_type="ml.c5.4xlarge",
framework_version="2.0-1",
output_path=f"s3://{bucket}/{prefix}/output"
)
xgb_estimator.fit({
"train": training_data_uri,
"validation": validation_data_uri
})
The primary scoring model uses XGBoost, a gradient boosting framework that has proven highly effective for fraud detection. XGBoost offers several advantages for this use case:
- It handles the class imbalance inherent in fraud data (where legitimate transactions far outnumber fraudulent ones)
- It natively handles mixed data types and missing values, common in transaction data
- It provides good interpretability through feature importance rankings
- It delivers high accuracy with relatively small model size, enabling fast inference
The hyperparameters chosen reflect best practices for fraud detection:
-
max_depth: 6prevents overfitting while capturing complex interactions between features -
eta: 0.2(learning rate) balances training speed and model quality -
gamma: 4controls the minimum loss reduction required for a split, reducing overfitting -
min_child_weight: 6helps manage class imbalance by requiring substantial weight in leaf nodes -
subsample: 0.8introduces randomness to prevent overfitting -
objective: binary:logisticoutputs probabilities suitable for fraud scoring
The configuration uses 4 instances for distributed training, reflecting the size of the training dataset (typically billions of rows for a large financial institution). The ml.c5.4xlarge instance type is chosen for its balance of CPU power and memory, which are more important than GPU acceleration for tree-based models like XGBoost.
-
Specialized Models:
- Graph Neural Network (GNN): Heterogeneous graph model using DGL
- Behavioral Biometrics Model: LSTM network analyzing interaction patterns
- NLP Model: Claude 3.5 fine-tuned for transaction descriptions
- Anomaly Detection: Deep autoencoder for unusual patterns
- Device Fingerprinting: CNN for device profile analysis
These specialized models address different aspects of fraud detection:
The Graph Neural Network analyzes relationships between entities (customers, merchants, devices, IP addresses) to identify suspicious patterns that aren't visible when examining transactions in isolation. For example, it can detect when multiple accounts are controlled by the same fraudster based on shared connections or behaviors. The use of the Deep Graph Library (DGL) enables efficient processing of heterogeneous graphs where nodes and edges have different types and attributes.
The Behavioral Biometrics Model examines patterns in how users interact with their devices and applications. For example, it can analyze typing rhythm, mouse movements, or touch gestures to distinguish between legitimate users and impostors. The Long Short-Term Memory (LSTM) architecture is particularly well-suited for this task because it can capture temporal patterns in sequential data.
The NLP Model leverages Claude 3.5, a large language model, to analyze transaction descriptions and other text data. This model can identify unusual or suspicious language patterns that might indicate fraud, such as inconsistencies between the description and the transaction amount or merchant category. Fine-tuning Claude 3.5 for this specific task ensures that it focuses on relevant patterns rather than general language understanding.
The Anomaly Detection model uses a deep autoencoder to identify transactions that deviate significantly from normal patterns. By learning to compress and reconstruct "normal" transactions, the autoencoder can identify anomalies as transactions that have high reconstruction error. This approach is particularly valuable for detecting novel fraud patterns that haven't been seen before.
The Device Fingerprinting model uses a Convolutional Neural Network (CNN) to analyze device profiles, identifying suspicious devices or potential device spoofing. This model can detect when a device's characteristics don't match expected patterns or when a fraudster is attempting to mimic a legitimate user's device.
- Meta-Model Ensemble: Combines outputs using a stacking approach
The meta-model ensemble integrates outputs from all models to make a final fraud determination. The stacking approach treats each model's output as a feature, then trains a higher-level model to optimally combine these features based on historical performance. This approach allows the system to leverage the strengths of each model while mitigating their individual weaknesses.
For example, the XGBoost model might excel at identifying fraud based on transaction characteristics, while the GNN might be better at detecting fraud rings, and the Behavioral Biometrics model might excel at identifying account takeovers. The meta-model learns which models are most reliable in different contexts and weights their outputs accordingly.
Real-time inference pipeline implementation
Converting ML models into a production system requires careful orchestration of data flow, model invocation, and decision logic. The inference pipeline must handle high throughput while maintaining low latency, ensuring that fraud decisions are both accurate and timely.
The inference workflow uses AWS Step Functions for orchestration:
// Step Functions State Machine Definition
{
"Comment": "Fraud Detection Workflow",
"StartAt": "ExtractTransactionData",
"States": {
"ExtractTransactionData": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:ExtractTransactionDataFunction",
"Next": "GetFeatures"
},
"GetFeatures": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:GetFeaturesFunction",
"Next": "ParallelModelInference"
},
"ParallelModelInference": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "PrimaryModelInference",
"States": {
"PrimaryModelInference": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:InvokePrimaryModelFunction",
"End": true
}
}
},
{
"StartAt": "GNNModelInference",
"States": {
"GNNModelInference": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:InvokeGNNModelFunction",
"End": true
}
}
},
{
"StartAt": "BehavioralModelInference",
"States": {
"BehavioralModelInference": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:InvokeBehavioralModelFunction",
"End": true
}
}
}
],
"Next": "EnsembleResults"
},
"EnsembleResults": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:EnsembleResultsFunction",
"Next": "ApplyRules"
},
"ApplyRules": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:ApplyRulesFunction",
"Next": "DetermineAction"
},
"DetermineAction": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.fraudScore",
"NumericGreaterThan": 0.8,
"Next": "RejectTransaction"
},
{
"Variable": "$.fraudScore",
"NumericGreaterThan": 0.5,
"Next": "FlagForReview"
}
],
"Default": "ApproveTransaction"
},
"RejectTransaction": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:RejectTransactionFunction",
"Next": "PublishResult"
},
"FlagForReview": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:FlagForReviewFunction",
"Next": "PublishResult"
},
"ApproveTransaction": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:ApproveTransactionFunction",
"Next": "PublishResult"
},
"PublishResult": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account:function:PublishResultFunction",
"End": true
}
}
}
This AWS Step Functions state machine orchestrates the entire fraud detection workflow, from receiving a transaction to making and communicating a decision. The workflow design reflects several key architectural considerations:
Modular Design: Each step is implemented as a separate Lambda function, allowing independent development, testing, and scaling. This modular approach also enables gradual evolution of the system, as individual components can be updated without affecting the overall workflow.
Parallel Processing: The
ParallelModelInferencestate executes multiple model inference tasks simultaneously, reducing the overall latency compared to sequential execution. This parallelism is crucial for meeting the sub-100ms latency requirement while still leveraging multiple specialized models.Workflow Visibility: Using Step Functions provides clear visibility into the workflow execution, facilitating monitoring, debugging, and compliance auditing. Each execution is tracked with its own execution ID, making it possible to trace the decision-making process for any transaction.
Error Handling: While not explicitly shown in this excerpt, Step Functions supports sophisticated error handling, including retries with exponential backoff and catch states that can implement fallback logic. This robustness is essential for a mission-critical system like fraud detection.
Decision Logic: The
DetermineActionstate implements a simple decision tree based on the fraud score, with different thresholds triggering different actions. This separation of decision logic from model inference allows business rules to be adjusted without changing the underlying models.
The workflow processes a transaction through these key stages:
Data Extraction: The
ExtractTransactionDatastep parses the incoming transaction data, normalizing formats and validating inputs.Feature Retrieval: The
GetFeaturesstep retrieves current and historical features from the Feature Store, including both transaction-specific features and entity-level features (customer, merchant, device).-
Model Inference: Multiple models run in parallel to assess different aspects of fraud risk:
- The primary XGBoost model evaluates transaction characteristics
- The GNN model analyzes entity relationships
- The behavioral model examines user interaction patterns
Result Combination: The
EnsembleResultsstep combines the outputs from individual models using the meta-model, generating a unified fraud score and confidence level.Rule Application: The
ApplyRulesstep applies business rules and regulatory constraints that might override or adjust the model-based decision. For example, certain high-risk merchant categories might require additional scrutiny regardless of model scores.Decision and Action: Based on the final fraud score, the workflow branches to either approve the transaction, flag it for review, or reject it outright. The thresholds (0.5 and 0.8 in this example) are calibrated based on the desired balance between fraud prevention and false positives.
Result Publication: Finally, the decision is published to downstream systems, including the transaction processing system, customer notification services, and fraud analytics platforms.
For high-volume transaction processing, this Step Functions workflow is typically initiated by a Lambda function that processes events from the Kinesis data stream. The Lambda function can batch transactions for efficiency while ensuring that high-risk transactions are prioritized.
Continuous learning implementation
Fraud patterns evolve rapidly as fraudsters adapt to detection methods. A static fraud detection system would quickly become ineffective, making continuous learning capabilities essential for maintaining detection accuracy over time.
The solution ensures models remain effective against evolving fraud patterns:
# SageMaker Pipeline for Continuous Model Retraining
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import ProcessingStep, TrainingStep, CreateModelStep
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
# Step 1: Data preprocessing
preprocessing_step = ProcessingStep(
name="PreprocessTrainingData",
processor=sklearn_processor,
inputs=[
ProcessingInput(
source=input_data_uri,
destination="/opt/ml/processing/input"
)
],
outputs=[
ProcessingOutput(output_name="train", source="/opt/ml/processing/train"),
ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"),
ProcessingOutput(output_name="test", source="/opt/ml/processing/test")
],
code="preprocess.py"
)
# Step 2: Model training
training_step = TrainingStep(
name="TrainFraudDetectionModel",
estimator=xgb_estimator,
inputs={
"train": preprocessing_step.properties.ProcessingOutputConfig.Outputs["train"].S3Output.S3Uri,
"validation": preprocessing_step.properties.ProcessingOutputConfig.Outputs["validation"].S3Output.S3Uri
}
)
# Step 3: Model evaluation
evaluation_step = ProcessingStep(
name="EvaluateModel",
processor=sklearn_processor,
inputs=[
ProcessingInput(
source=training_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model"
),
ProcessingInput(
source=preprocessing_step.properties.ProcessingOutputConfig.Outputs["test"].S3Output.S3Uri,
destination="/opt/ml/processing/test"
)
],
outputs=[
ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code="evaluate.py"
)
# Step 4: Register model only if accuracy meets threshold
evaluation_report = PropertyFile(
name="EvaluationReport",
output_name="evaluation",
path="evaluation.json"
)
register_step = ConditionStep(
name="RegisterNewModel",
conditions=[ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.accuracy.value"
),
right=0.8
)],
if_steps=[
CreateModelStep(
name="CreateModel",
model=model,
inputs=model_inputs
),
# Model registration step
RegisterModel(
name="RegisterModel",
estimator=xgb_estimator,
model_data=training_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["application/json"],
response_types=["application/json"],
inference_instances=["ml.c5.xlarge", "ml.m5.xlarge"],
transform_instances=["ml.m5.xlarge"],
model_package_group_name="FraudDetectionModels"
)
],
else_steps=[]
)
# Create and run pipeline
pipeline = Pipeline(
name="FraudDetectionContinuousLearningPipeline",
steps=[preprocessing_step, training_step, evaluation_step, register_step],
sagemaker_session=sagemaker_session
)
This SageMaker Pipeline implementation demonstrates a systematic approach to continuous model improvement, addressing several key challenges in maintaining effective fraud detection over time:
Automated Retraining: The pipeline automates the entire process from data preprocessing to model deployment, enabling frequent retraining without manual intervention. This automation is crucial for keeping pace with evolving fraud patterns, which can change on a daily or even hourly basis.
Data Quality Control: The preprocessing step not only prepares data for training but can also implement quality checks to ensure that the training data is valid and representative. This might include checks for class imbalance, feature distribution shifts, or data integrity issues.
Performance Validation: The pipeline includes a rigorous evaluation step that assesses the new model's performance against a held-out test set. This validation ensures that model updates actually improve detection capabilities rather than degrading them.
Conditional Deployment: The condition step ensures that only models that meet or exceed a performance threshold (80% accuracy in this example) are registered for deployment. This safeguard prevents the deployment of underperforming models that could increase false positives or miss fraudulent transactions.
Model Registry Integration: The
RegisterModelstep integrates with the SageMaker Model Registry, maintaining a versioned history of models along with their metadata and performance metrics. This registry facilitates model governance, auditing, and rollback if needed.
In practice, this pipeline would be triggered based on multiple conditions:
- Scheduled Retraining: Regular retraining cycles (e.g., daily or weekly) to incorporate recent data
- Performance Degradation: Automated triggers when the current model's performance falls below thresholds
- Data Drift Detection: Triggers when significant shifts in feature distributions are detected
- Manual Initiation: For emergency updates in response to new fraud patterns
The continuous learning system also incorporates techniques beyond basic retraining:
- Active Learning: Prioritizing ambiguous or borderline cases for expert review, rapidly improving the model in areas of uncertainty
- Online Learning: Incremental model updates based on streaming data, particularly for adapting to sudden changes in fraud patterns
- Champion-Challenger Testing: Running multiple model variants simultaneously and gradually shifting traffic based on performance
These continuous learning capabilities ensure that the fraud detection system remains effective even as fraudsters adapt their tactics, new types of fraud emerge, and legitimate transaction patterns evolve over time.
3. Advanced hardware acceleration and optimization techniques
The performance and cost-effectiveness of ML workloads depend significantly on the underlying hardware infrastructure. AWS offers a range of specialized hardware accelerators optimized for different ML tasks, enabling organizations to balance performance, cost, and energy efficiency based on their specific requirements.
Selecting the appropriate hardware for each component of an ML workflow is crucial for meeting latency requirements while controlling costs. Different phases of the ML lifecycle—training, fine-tuning, and inference—have different computational characteristics and can benefit from different types of accelerators.
Hardware acceleration selection and configuration
AWS offers multiple acceleration options for different ML workload phases:
Inferentia2 (Inference Optimization)
- Performance Metrics: 4x higher throughput and 10x lower latency compared to first-generation
- Technical Specifications: Each chip supports up to 190 TFLOPS of FP16 with 32GB HBM memory
- Optimal Instance Configuration: Inf2.48xlarge with 12 Inferentia2 accelerators delivers 2.3 petaflops
- Unique Feature: NeuronLink for faster distributed inference with direct data flow between accelerators
Inferentia2 represents a significant advancement in inference acceleration, designed specifically to address the demands of modern deep learning models. The architecture features specialized circuits for common neural network operations, dramatically reducing the computational overhead compared to general-purpose processors.
The NeuronLink technology is particularly valuable for large model inference, where model parallelism is necessary. By enabling direct chip-to-chip communication without going through host memory, NeuronLink reduces latency and increases throughput for models that exceed the memory capacity of a single accelerator—a common situation with modern foundation models.
For fraud detection applications, Inferentia2 is ideal for deploying computationally intensive components like the graph neural networks and behavioral biometrics models, where low-latency inference is critical to meeting the overall sub-100ms response time requirement.
Trainium2 (Training Optimization)
- Performance Metrics: 4x the performance of first-generation Trainium
- Technical Specifications: Trn2 instances feature 16 Trainium2 chips with NeuronLink, delivering 20.8 petaflops
- Advanced Features: Hardware optimizations for 4x sparsity (16:4), micro-scaling, stochastic rounding
- Cost Advantage: 30-40% better price performance compared to GPU-based EC2 P5 instances
Trainium2 is optimized specifically for training deep learning models, with architectural features that accelerate common training operations like backpropagation. The support for 4x sparsity (where only 4 out of every 16 weights are non-zero) is particularly beneficial for large language models and other neural networks that can leverage sparse representations without significant accuracy loss.
The micro-scaling feature enables fine-grained control over the precision used for different parts of the model, reducing memory requirements and computational overhead. Stochastic rounding improves training stability for low-precision arithmetic, enabling the use of lower precision formats (like FP8) without compromising model convergence.
For fraud detection, Trainium2 is well-suited for training the specialized neural network models, particularly when working with large datasets that benefit from distributed training.
| Workload Type | Recommended Instance | Key Specifications | Optimal Usage Pattern |
|---|---|---|---|
| Large-scale LLM Training | P5e/P5en | NVIDIA H100 GPUs, petabit-scale networking | Distributed training of foundation models |
| Mid-sized Training | G5 | NVIDIA A10G GPUs | More flexible sizing for varied workloads |
| Cost-Optimized Training | Trn1/Trn2 | AWS Trainium chips | Up to 50% cost-to-train savings |
| High-Performance Inference | Inf2 | AWS Inferentia2 chips | Lowest inference cost with high throughput |
| Flexible Inference | G4dn | NVIDIA T4 GPUs | General-purpose ML inference |
This table provides a framework for selecting the appropriate instance type based on workload characteristics. The choice between NVIDIA-based instances (P5e, G5, G4dn) and AWS custom silicon (Trn1/Trn2, Inf2) depends on several factors:
- Model Compatibility: Some models or frameworks may have optimizations specific to certain hardware platforms
- Development Stage: Early experimentation often benefits from the broader ecosystem support of NVIDIA GPUs
- Operational Requirements: Custom silicon typically requires specialized tooling (AWS Neuron SDK)
- Cost Sensitivity: Custom silicon generally offers better price-performance for compatible workloads
For fraud detection systems, a hybrid approach often works best: using NVIDIA-based instances for initial development and experimentation, then migrating production workloads to Inferentia2 for inference and Trainium2 for regular retraining once the models are stable.
Distributed training architectures
As model sizes grow and training datasets expand, distributed training becomes essential for maintaining reasonable training times. Modern distributed training goes beyond simple data parallelism to encompass sophisticated techniques for splitting models across multiple devices while maintaining training efficiency.
For large-scale model training, implement these advanced techniques:
Tensor Parallelism Implementation
# Configuration for tensor parallelism with AWS Neuron SDK
import torch_neuron as neuron
neuron_config = {
"tensor_parallel_degree": 8,
"pipeline_parallel_degree": 1,
"microbatch_count": 4,
"optimize_memory_usage": True
}
# Apply configuration to model training
with neuron.parallel_config(**neuron_config):
model_parallel = neuron.parallelize(model)
Tensor parallelism splits individual tensors (model weights, activations, gradients) across multiple devices, enabling training of models that are too large to fit on a single accelerator. This approach is particularly valuable for large language models and other architectures with massive parameter counts.
The configuration shown above implements tensor parallelism across 8 devices (likely Trainium2 accelerators within a Trn2 instance), with a microbatch count of 4 to optimize throughput. The optimize_memory_usage parameter enables memory-saving techniques like activation checkpointing, which trades computation for memory by recomputing certain activations during the backward pass rather than storing them.
Tensor parallelism complements other distributed training strategies:
Fully Sharded Data Parallel (FSDP)
- Shards model parameters, gradients, and optimizer states across workers
- Reduces memory footprint by up to 4x compared to standard distributed data parallel
- Implementation best practice: use activation checkpointing with FSDP
FSDP extends traditional data parallelism (where each worker has a complete copy of the model) by sharding model components across workers. During the forward and backward passes, parameters are communicated just-in-time, reducing memory requirements at the cost of additional communication overhead.
This technique is crucial for training very large models, as it allows the aggregate memory of multiple devices to be used effectively. In the context of fraud detection, FSDP is valuable when training complex models like graph neural networks on large transaction graphs, where memory consumption can become a bottleneck.
AWS-Optimized Infrastructure
- EC2 UltraCluster Architecture with petabit-scale non-blocking networking
- SageMaker HyperPod with automated fault detection, diagnosis, and recovery
- EFA network interfaces for up to 400 Gbps bandwidth and sub-microsecond latency
The network infrastructure connecting compute nodes is as important as the accelerators themselves for distributed training performance. AWS's UltraCluster architecture provides non-blocking, full-bisection bandwidth between nodes, minimizing communication bottlenecks during distributed training. This is essential for scaling to hundreds or thousands of accelerators.
SageMaker HyperPod simplifies the operation of large-scale training clusters, providing automated fault handling and cluster management. This operational efficiency is particularly valuable for long-running training jobs, where hardware failures become increasingly probable as the scale increases.
Elastic Fabric Adapter (EFA) provides high-throughput, low-latency networking optimized for ML workloads. The sub-microsecond latency is crucial for reducing the communication overhead in distributed training, particularly for techniques like tensor parallelism and FSDP that require frequent parameter synchronization.
Hyperparameter optimization techniques
Hyperparameter optimization (HPO) is crucial for achieving optimal model performance, but can be computationally expensive and time-consuming. Advanced HPO techniques reduce the resources required while improving the quality of the resulting models.
# Multi-objective HPO configuration
hyperparameter_tuner = HyperparameterTuner(
estimator=estimator,
objective_type='Maximize',
objective_metric_name='validation:accuracy',
metric_definitions=[
{'Name': 'inference_latency', 'Regex': 'Inference latency: ([0-9.]+)'},
{'Name': 'memory_usage', 'Regex': 'Memory usage: ([0-9.]+)'}
],
strategy='Bayesian',
early_stopping_type='Auto',
max_jobs=50,
max_parallel_jobs=5,
warm_start_type='TransferLearning',
warm_start_config=WarmStartConfig(
warm_start_type='TransferLearning',
parents=['parent-tuning-job-name']
)
)
This HPO configuration demonstrates several advanced techniques:
Multi-objective Optimization: Rather than optimizing for a single metric (accuracy), this configuration also tracks inference latency and memory usage. This multi-objective approach is crucial for production ML systems, where performance constraints are as important as model quality. The tuner will seek hyperparameter combinations that balance these competing objectives.
Bayesian Optimization: Unlike grid search or random search, Bayesian optimization uses a probabilistic model of the objective function to intelligently select the next hyperparameter combinations to evaluate. This approach converges much faster than exhaustive methods, particularly for high-dimensional hyperparameter spaces.
Early Stopping: The
early_stopping_type='Auto'parameter enables automatic termination of underperforming training jobs based on intermediate evaluation metrics. This prevents wasting computational resources on hyperparameter combinations that are unlikely to yield good results.Transfer Learning: The
warm_start_type='TransferLearning'configuration leverages knowledge from previous hyperparameter tuning jobs to accelerate the current tuning process. This is particularly valuable when making incremental changes to models or adapting models to similar domains.Parallel Execution: The configuration allows up to 5 training jobs to run in parallel (
max_parallel_jobs=5), balancing resource utilization with the need for sequential information in Bayesian optimization.
Key HPO strategies include:
- Adaptive Early Stopping via Hyperband - Dynamically allocates resources to promising configurations
- Bayesian Optimization with Transfer Learning - Leverages knowledge from previous similar models
- Multi-Objective Optimization - Simultaneously optimizes for multiple metrics like accuracy, latency, memory usage
For fraud detection models, HPO needs to consider domain-specific considerations:
- Balancing precision and recall based on business cost models (false positives vs. false negatives)
- Optimizing for performance at specific decision thresholds rather than overall accuracy
- Ensuring model stability across different data segments (e.g., transaction types, customer segments)
- Maintaining acceptable latency under peak load conditions
By leveraging these advanced HPO techniques, the fraud detection system can continuously refine its models to improve detection rates while maintaining operational efficiency.
Model compression and quantization
As ML models grow in size and complexity, deploying them efficiently for real-time inference becomes increasingly challenging. Model compression and quantization techniques address this challenge by reducing model size and computational requirements without significantly sacrificing accuracy.
Apply these techniques to reduce model size and improve inference performance:
Activation-Aware Weight Quantization (AWQ)
- Reduces model size by 4x while preserving accuracy
- Identifies critical weights based on activation patterns
- Selectively preserves precision for sensitive weights (top 1%)
AWQ represents a significant advancement over traditional quantization methods. Rather than applying uniform quantization across all weights, it identifies which weights are most critical to model accuracy based on their activation patterns. By preserving higher precision for these critical weights while aggressively quantizing others, AWQ achieves better accuracy with the same overall model size.
# Deploying quantized models on AWS Inferentia2
import torch
import torch_neuronx
# Load pre-trained model
model = torch.load('model.pt')
# Define example input
example_input = torch.zeros([1, 3, 224, 224])
# Compile with INT8 quantization
compiler_args = ['--target=trn1', '--auto-cast=fp16', '--enable-quantization']
model_neuron = torch_neuronx.trace(model, example_input, compiler_args=compiler_args)
# Save compiled model
torch.jit.save(model_neuron, 'model_neuron_quantized.pt')
This code demonstrates how to deploy a quantized model on AWS Inferentia2 using the Neuron SDK. The --enable-quantization flag activates the built-in quantization capabilities of the compiler, which includes techniques like AWQ.
The process works in several steps:
- The model is traced with a representative input tensor, allowing the compiler to analyze the computational graph
- The
--auto-cast=fp16flag converts appropriate operations to half-precision (FP16) arithmetic - The quantization process converts weights from floating-point to integer representation (typically INT8)
- The compiler optimizes the quantized model for the Inferentia2 hardware architecture
- The resulting compiled model is saved for deployment
For fraud detection models, quantization must be applied carefully to avoid compromising detection accuracy. Critical components like the primary scoring model and behavioral biometrics models benefit from selective quantization, where only stable and robust parts of the model are quantized while maintaining higher precision for sensitive operations.
Other optimization techniques include:
- Outlier-Aware Quantization (OAQ) - Reshapes weight distributions to enhance quantization accuracy
- Knowledge Distillation - Teacher-student frameworks with intermediate feature matching
- Sparse Tensor Train Decomposition - Represents high-dimensional tensors as a series of low-rank cores
Knowledge distillation is particularly valuable for complex ensemble models like those used in fraud detection. A large, accurate "teacher" ensemble can be distilled into a smaller, faster "student" model that captures most of the ensemble's predictive power while being much more efficient to deploy. This technique maintains the accuracy benefits of ensemble methods while addressing their latency and resource challenges.
Sparse Tensor Train Decomposition addresses the computational challenges of models with high-dimensional parameter tensors, common in multi-modal fraud detection systems. By decomposing these tensors into products of much smaller core tensors, this technique dramatically reduces parameter counts while preserving most of the model's representational capacity.
4. Infrastructure as code for AI/ML workloads
Machine learning systems present unique infrastructure challenges due to their complex lifecycles, specialized resource requirements, and the need for reproducibility. Infrastructure as Code (IaC) addresses these challenges by providing declarative, version-controlled definitions of infrastructure that can be consistently deployed and managed.
For ML workloads, IaC is particularly valuable because it:
- Ensures consistency between development, testing, and production environments
- Provides audit trails for model training infrastructure, crucial for regulatory compliance
- Enables rapid deployment of complex, multi-component ML systems
- Facilitates disaster recovery and business continuity for critical ML applications
- Streamlines the transition from experimentation to production
The following sections demonstrate different IaC approaches for deploying ML infrastructure on AWS, each with its own strengths and ecosystem.
AWS CloudFormation/CDK implementation
AWS Cloud Development Kit (CDK) provides a higher-level abstraction over CloudFormation, allowing infrastructure to be defined using familiar programming languages. This approach is particularly valuable for ML infrastructure, where complex relationships between components are common.
Create a secure SageMaker environment using AWS CDK:
from aws_cdk import (
aws_sagemaker as sagemaker,
aws_ec2 as ec2,
aws_iam as iam,
aws_kms as kms,
Stack
)
from constructs import Construct
class SecureSageMakerStack(Stack):
def __init__(self, scope: Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
# Create a VPC with isolated subnets
vpc = ec2.Vpc(self, "MLWorkloadVPC",
max_azs=2,
subnet_configuration=[
ec2.SubnetConfiguration(
name="private",
subnet_type=ec2.SubnetType.PRIVATE_ISOLATED,
cidr_mask=24
)
]
)
# Add VPC Endpoints for SageMaker API, Runtime, and S3
vpc.add_interface_endpoint("SageMakerAPI",
service=ec2.InterfaceVpcEndpointAwsService.SAGEMAKER_API
)
vpc.add_interface_endpoint("SageMakerRuntime",
service=ec2.InterfaceVpcEndpointAwsService.SAGEMAKER_RUNTIME
)
vpc.add_gateway_endpoint("S3Endpoint",
service=ec2.GatewayVpcEndpointAwsService.S3
)
# Create KMS key for encryption
kms_key = kms.Key(self, "MLDataKey",
enable_key_rotation=True,
description="KMS key for ML data encryption"
)
# Create IAM role with least privilege
notebook_role = iam.Role(self, "NotebookRole",
assumed_by=iam.ServicePrincipal("sagemaker.amazonaws.com")
)
# Add necessary permissions
notebook_role.add_managed_policy(
iam.ManagedPolicy.from_aws_managed_policy_name("AmazonSageMakerFullAccess")
)
# Create security group for the notebook instance
sg = ec2.SecurityGroup(self, "NotebookSG",
vpc=vpc,
description="Security group for SageMaker notebook instance",
allow_all_outbound=False
)
# Create a SageMaker notebook instance
notebook = sagemaker.CfnNotebookInstance(self, "SecureNotebook",
instance_type="ml.t3.medium",
role_arn=notebook_role.role_arn,
root_access="Disabled",
direct_internet_access="Disabled",
subnet_id=vpc.private_subnets[0].subnet_id,
security_group_ids=[sg.security_group_id],
kms_key_id=kms_key.key_arn,
volume_size_in_gb=50
)
This CDK implementation creates a secure SageMaker development environment with several important security features:
Network Isolation: The SageMaker notebook instance is deployed in a private, isolated subnet without direct internet access. This prevents unauthorized data exfiltration and limits exposure to external threats.
VPC Endpoints: Interface endpoints for SageMaker API and Runtime, along with a gateway endpoint for S3, allow the notebook instance to communicate with AWS services without traversing the public internet. This enhances security while maintaining functionality.
Data Encryption: A dedicated KMS key is created for encrypting ML data, with automatic key rotation enabled. This encryption protects sensitive data at rest, addressing requirements in regulations like GDPR and industry standards like PCI-DSS.
Least Privilege Access: The IAM role created for the notebook instance follows the principle of least privilege, though in this example it uses the managed policy
AmazonSageMakerFullAccess. In a production environment, this would typically be replaced with a more restrictive custom policy.Root Access Restriction: The
root_access="Disabled"setting prevents users from gaining root access to the underlying instance, limiting the potential for system-level modifications that could compromise security.
This infrastructure definition can be version-controlled, reviewed through standard code review processes, and deployed consistently across multiple environments. It also serves as documentation of the infrastructure, making it easier to understand the system's architecture and security controls.
For ML workloads, CDK's programming model provides advantages over raw CloudFormation:
- Logic for dynamic resource configuration (e.g., scaling instance types based on data size)
- Reusable components for common ML infrastructure patterns
- Integration with existing software development workflows
- Type safety and IDE support for catching errors early
Terraform implementation
Terraform is a popular multi-cloud IaC tool that provides a consistent workflow across different cloud providers. For organizations using multiple clouds or migrating between providers, Terraform offers valuable flexibility.
Configure a secure SageMaker endpoint with Terraform:
provider "aws" {
region = "us-east-1"
}
resource "aws_iam_role" "sagemaker_role" {
name = "sagemaker-execution-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "sagemaker.amazonaws.com"
}
}
]
})
}
resource "aws_iam_role_policy_attachment" "sagemaker_policy" {
role = aws_iam_role.sagemaker_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSageMakerFullAccess"
}
resource "aws_security_group" "training_sg" {
name = "sagemaker-training-sg"
description = "Security group for SageMaker training jobs"
vpc_id = var.vpc_id
egress {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
description = "Allow HTTPS outbound traffic"
}
}
resource "aws_sagemaker_model" "ml_model" {
name = "secure-ml-model"
execution_role_arn = aws_iam_role.sagemaker_role.arn
primary_container {
image = "${var.account_id}.dkr.ecr.${var.region}.amazonaws.com/${var.model_image}:latest"
model_data_url = "s3://${var.model_bucket}/${var.model_key}"
}
vpc_config {
subnets = var.private_subnet_ids
security_group_ids = [aws_security_group.training_sg.id]
}
enable_network_isolation = true
}
resource "aws_sagemaker_endpoint_configuration" "endpoint_config" {
name = "secure-endpoint-config"
production_variants {
variant_name = "variant-1"
model_name = aws_sagemaker_model.ml_model.name
initial_instance_count = 1
instance_type = "ml.c5.large"
}
kms_key_arn = var.kms_key_arn
}
resource "aws_sagemaker_endpoint" "endpoint" {
name = "secure-ml-endpoint"
endpoint_config_name = aws_sagemaker_endpoint_configuration.endpoint_config.name
}
This Terraform configuration deploys a secure SageMaker endpoint for model inference, incorporating several security best practices:
Network Isolation: The
enable_network_isolation = truesetting ensures that the model container cannot make outbound network calls, preventing potential data exfiltration or unauthorized API access.VPC Deployment: The model is deployed within a VPC, with security groups controlling network traffic. This provides network-level isolation and control over communication paths.
Restrictive Egress Rules: The security group allows only HTTPS outbound traffic (port 443), restricting the model container's ability to communicate with external services.
Encryption: The endpoint configuration references a KMS key (provided as a variable) for encrypting data at rest, including the model artifacts and endpoint storage.
The configuration also demonstrates Terraform's use of variables (var.vpc_id, var.private_subnet_ids, etc.), which allow the same infrastructure definition to be deployed across different environments with environment-specific parameters.
For ML infrastructure, Terraform offers several advantages:
- State management for tracking infrastructure changes over time
- Modules for encapsulating and reusing infrastructure patterns
- Provider ecosystem for managing resources across multiple cloud providers
- Plan/apply workflow for reviewing changes before implementation
Terraform's declarative approach is particularly valuable for compliance-focused organizations, as it provides clear documentation of infrastructure state and changes over time. This audit trail is crucial for regulated industries like finance and healthcare, where ML model deployments must meet stringent governance requirements.
Pulumi implementation
Pulumi takes a different approach to IaC, allowing infrastructure to be defined using general-purpose programming languages like Python, TypeScript, Go, and others. This approach is particularly valuable for ML infrastructure, where complex logic may be needed to configure resources based on model characteristics or data properties.
Create a secure ML infrastructure using Pulumi:
import pulumi
import pulumi_aws as aws
# Create IAM role for SageMaker
sagemaker_role = aws.iam.Role("sagemaker-role",
assume_role_policy=aws.iam.get_policy_document(statements=[
aws.iam.GetPolicyDocumentStatementArgs(
actions=["sts:AssumeRole"],
principals=[aws.iam.GetPolicyDocumentStatementPrincipalArgs(
type="Service",
identifiers=["sagemaker.amazonaws.com"],
)]
)
]).json
)
# Attach the SageMaker policy
role_policy_attachment = aws.iam.RolePolicyAttachment("sagemaker-policy-attachment",
role=sagemaker_role.name,
policy_arn="arn:aws:iam::aws:policy/AmazonSageMakerFullAccess"
)
# Create a VPC for secure ML workloads
vpc = aws.ec2.Vpc("ml-vpc",
cidr_block="10.0.0.0/16",
enable_dns_hostnames=True,
enable_dns_support=True
)
# Create private subnets
private_subnet_1 = aws.ec2.Subnet("private-subnet-1",
vpc_id=vpc.id,
cidr_block="10.0.1.0/24",
availability_zone="us-east-1a",
map_public_ip_on_launch=False
)
private_subnet_2 = aws.ec2.Subnet("private-subnet-2",
vpc_id=vpc.id,
cidr_block="10.0.2.0/24",
availability_zone="us-east-1b",
map_public_ip_on_launch=False
)
# Create a security group for ML workloads
ml_security_group = aws.ec2.SecurityGroup("ml-security-group",
vpc_id=vpc.id,
description="Security group for ML workloads",
egress=[aws.ec2.SecurityGroupEgressArgs(
from_port=0,
to_port=0,
protocol="-1",
cidr_blocks=["0.0.0.0/0"],
description="Allow all outbound traffic"
)]
)
# Create the SageMaker model
model = aws.sagemaker.Model("ml-model",
execution_role_arn=sagemaker_role.arn,
primary_container=aws.sagemaker.ModelPrimaryContainerArgs(
image=f"{account_id}.dkr.ecr.{region}.amazonaws.com/{model_image}:latest",
model_data_url=f"s3://{model_bucket}/{model_key}"
),
vpc_config=aws.sagemaker.ModelVpcConfigArgs(
security_group_ids=[ml_security_group.id],
subnets=[private_subnet_1.id, private_subnet_2.id]
),
enable_network_isolation=True
)
# Create an endpoint configuration
endpoint_config = aws.sagemaker.EndpointConfiguration("ml-endpoint-config",
production_variants=[aws.sagemaker.EndpointConfigurationProductionVariantArgs(
variant_name="variant-1",
model_name=model.name,
initial_instance_count=1,
instance_type="ml.c5.large",
initial_variant_weight=1.0
)]
)
# Create the endpoint
endpoint = aws.sagemaker.Endpoint("ml-endpoint",
endpoint_config_name=endpoint_config.name
)
# Export the endpoint name
pulumi.export("endpoint_name", endpoint.name)
This Pulumi program creates a similar infrastructure to the Terraform example, but with the advantages of a general-purpose programming language:
Full Programming Capabilities: The code can include conditional logic, loops, functions, and other programming constructs to create more dynamic infrastructure definitions. For ML workloads, this might include scaling resources based on model size or complexity.
Object-Oriented Design: The infrastructure can be modeled using object-oriented principles, with classes representing reusable infrastructure patterns. This is particularly valuable for ML infrastructure, which often involves similar patterns across different models or applications.
Native Integration with Application Code: Pulumi allows infrastructure definitions to live alongside application code, facilitating DevOps practices and ensuring that infrastructure changes are coordinated with application changes.
Testing Framework Integration: Infrastructure code can be tested using standard programming language testing frameworks, enabling test-driven development for infrastructure.
For ML operations (MLOps), Pulumi's programming model can be particularly valuable when infrastructure needs to adapt to model characteristics. For example, instance types could be selected based on model size, memory requirements, or computational complexity, all calculated programmatically as part of the infrastructure definition.
The example creates a secure deployment environment with private networking, appropriate security groups, and network isolation for the SageMaker model. The multi-AZ deployment across two availability zones (us-east-1a and us-east-1b) enhances availability, ensuring that the ML service remains accessible even if one availability zone experiences issues.
5. AI/ML-specific security considerations
Machine learning systems introduce unique security challenges that go beyond traditional application security concerns. From protecting sensitive training data to preventing adversarial attacks on deployed models, ML security requires a comprehensive approach addressing the entire ML lifecycle.
For fraud detection systems, security is particularly critical given the financial impact of compromises and the sensitive nature of the data involved. The following sections outline key ML-specific security considerations and how to address them on AWS.
Model security and adversarial attack prevention
AI/ML models face unique security challenges that require specialized protection:
Model Poisoning Mitigation
- Implement rigorous data validation procedures before training
- Deploy anomaly detection to filter potentially adversarial data
- Track data origins using OWASP CycloneDX or ML-BOM
- Configure SageMaker training jobs with
EnableNetworkIsolationset totrue
Model poisoning represents a significant threat to ML systems, particularly those used for security-critical applications like fraud detection. In a poisoning attack, an adversary manipulates the training data to introduce vulnerabilities or backdoors that can be exploited later. For example, a fraudster might attempt to poison a fraud detection model's training data to create blind spots for specific fraud patterns.
Data validation procedures are the first line of defense against poisoning attacks. These procedures should check for statistical anomalies, inconsistencies, and patterns that might indicate tampering. For fraud detection models, this might include checking for unusual distributions of transaction amounts, suspicious patterns in IP addresses, or anomalous relationships between features.
Tracking data provenance using frameworks like OWASP CycloneDX or ML Bill of Materials (ML-BOM) provides accountability and traceability for all data used in model training. This audit trail is valuable not only for security but also for regulatory compliance, allowing organizations to demonstrate due diligence in data handling.
Network isolation during training prevents the training job from making unauthorized network calls, which could potentially exfiltrate sensitive data or import compromised code or data. This isolation is a simple but effective security control that should be standard practice for all production ML training jobs.
Adversarial Attack Prevention
- Implement thorough validation pipelines for inference inputs
- Maintain model version control for quick recovery
- Use retrieval-augmented generation (RAG) to reduce hallucination risks
Adversarial attacks on deployed models represent another significant threat. In these attacks, an adversary crafts inputs specifically designed to confuse or mislead the model, causing it to produce incorrect outputs. For fraud detection, this might involve creating transaction patterns that appear legitimate to the model despite being fraudulent.
Input validation for inference requests is crucial for preventing adversarial attacks. This validation should check for input values outside expected ranges, unusual combinations of features, or patterns known to be associated with adversarial attempts. For example, a fraud detection system might flag transactions with abnormally precise amounts or suspiciously round timestamps.
Model version control enables rapid response to detected vulnerabilities or attacks. If a model is found to be compromised or vulnerable to specific adversarial patterns, having a robust versioning system allows for quick rollback to a previous secure version while the issue is addressed.
For models that incorporate generative components, retrieval-augmented generation (RAG) can reduce the risk of "hallucinations" or fabricated outputs. By grounding generated content in retrieved information from trusted sources, RAG helps ensure that the model's outputs are based on factual information rather than confabulations that might be exploited by attackers.
Data encryption and protection
Implement comprehensive data security measures:
# KMS encryption configuration for ML data (Terraform)
resource "aws_kms_key" "ml_data_key" {
description = "KMS key for ML data encryption"
deletion_window_in_days = 30
enable_key_rotation = true
policy = data.aws_iam_policy_document.ml_kms_policy.json
}
resource "aws_s3_bucket" "ml_data_bucket" {
bucket = "secure-ml-data-${random_string.suffix.result}"
}
resource "aws_s3_bucket_server_side_encryption_configuration" "ml_bucket_encryption" {
bucket = aws_s3_bucket.ml_data_bucket.id
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = aws_kms_key.ml_data_key.arn
sse_algorithm = "aws:kms"
}
}
}
Data protection is particularly critical for ML systems, which often process large volumes of sensitive information. The configuration above demonstrates several important data protection measures:
KMS Key Management: Creating a dedicated KMS key for ML data provides fine-grained control over encryption and access. The 30-day deletion window provides protection against accidental key deletion, while automatic key rotation enhances security by periodically changing the encryption material.
Bucket Encryption: Configuring server-side encryption using the KMS key ensures that all data stored in the bucket is automatically encrypted at rest. This addresses regulatory requirements for data protection and reduces the risk of data exposure if storage media are compromised.
Randomized Bucket Name: Including a random suffix in the bucket name (
${random_string.suffix.result}) prevents predictable resource naming, making it harder for attackers to guess resource names.
For ML workloads, data protection should address the entire data lifecycle:
- Collection: Secure methods for gathering and importing data, including encrypted transit
- Storage: Encryption at rest for all data, with appropriate access controls
- Processing: Secure computing environments for feature engineering and training
- Archival: Long-term storage with encryption and strict access limitations
- Deletion: Secure deletion procedures for data that is no longer needed
In the context of fraud detection, data protection is particularly important due to the sensitive nature of financial transaction data. The system must protect not only the raw transaction data but also derived features, model parameters, and inference results, all of which could potentially reveal sensitive information about customers or financial patterns.
IAM configurations for least privilege
Create specific roles for different ML phases:
# IAM policy for training job role (CloudFormation)
SageMakerTrainingRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: sagemaker.amazonaws.com
Action: 'sts:AssumeRole'
Policies:
- PolicyName: SageMakerTrainingPolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:ListBucket
Resource:
- !Sub arn:aws:s3:::${TrainingDataBucket}
- !Sub arn:aws:s3:::${TrainingDataBucket}/*
Condition:
StringEquals:
aws:ResourceTag/Purpose: 'MLTraining'
- Effect: Allow
Action:
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${ModelArtifactBucket}/*
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/sagemaker/*
The principle of least privilege is crucial for ML security, particularly given the sensitive data often involved. This IAM policy demonstrates several important least-privilege practices:
Phase-Specific Roles: Creating a dedicated role for training jobs ensures that training code only has the permissions necessary for that specific phase of the ML lifecycle. Similar phase-specific roles should be created for data preprocessing, model deployment, monitoring, etc.
Resource-Level Restrictions: The policy grants access only to specific S3 buckets (referenced by the
TrainingDataBucketandModelArtifactBucketparameters), rather than all S3 resources. This prevents the training job from accessing unrelated data or interfering with other ML projects.Action-Level Restrictions: The policy grants only the specific S3 actions needed (
GetObjectandListBucketfor input data,PutObjectfor output artifacts), rather than broader permissions likes3:*.Condition-Based Access: The policy includes a condition that restricts access to resources tagged with a specific purpose (
'MLTraining'). This tag-based access control allows for more granular permission management and clearer audit trails.Logging Permissions: The policy grants only the specific CloudWatch Logs permissions needed for the training job to log its output, scoped to the relevant log group prefix.
For a complete ML system, similar least-privilege roles should be created for each component and phase:
- Data Scientists: Access to development environments and training data, but not production systems
- MLOps Engineers: Deployment and infrastructure management capabilities, but limited data access
- Model Registry: Permissions to register and version models, but not deploy them
- Inference Services: Access to model artifacts and input data, but not training systems
- Monitoring Services: Ability to collect and analyze metrics, but not modify models or data
In the context of fraud detection, these least-privilege practices help prevent insider threats and limit the impact of compromised credentials. By ensuring that each component has only the permissions it absolutely needs, the system minimizes the potential damage from any single security breach.
Network security for distributed training
Configure secure inter-node communication:
// VPC configuration for training (CDK)
const vpc = new ec2.Vpc(this, 'TrainingVpc', {
maxAzs: 2,
subnetConfiguration: [
{
cidrMask: 24,
name: 'training',
subnetType: ec2.SubnetType.PRIVATE_ISOLATED,
}
]
});
const securityGroup = new ec2.SecurityGroup(this, 'TrainingSecurityGroup', {
vpc,
description: 'Security group for ML training cluster',
allowAllOutbound: false
});
// Allow traffic between training nodes on specific ports
securityGroup.addIngressRule(
securityGroup,
ec2.Port.tcp(7777),
'Allow inter-node communication for distributed training'
);
Distributed training introduces unique network security considerations. The training cluster needs to communicate efficiently between nodes, but this communication should be protected from eavesdropping, tampering, and other threats. The CDK configuration above demonstrates several important security measures:
Private, Isolated Subnets: Using
PRIVATE_ISOLATEDsubnet type ensures that the training cluster has no direct internet connectivity, reducing the attack surface and preventing data exfiltration.Restrictive Security Group: Setting
allowAllOutbound: falseblocks all outbound traffic by default, requiring explicit rules for necessary communications. This prevents unauthorized data transfers and command-and-control connections.Targeted Communication Rules: The ingress rule allows TCP traffic on port 7777 only between instances in the same security group. This permits the necessary communication for distributed training while blocking other traffic.
For production ML workloads, additional network security measures might include:
- VPC Endpoints: For accessing AWS services without traversing the public internet
- Network Traffic Inspection: For monitoring and filtering traffic to detect potential threats
- VPC Flow Logs: For auditing and analyzing network traffic patterns
- Private Link: For secure connection to external services or data sources
- Transit Gateway: For controlled connectivity between multiple VPCs or on-premises networks
In distributed training for fraud detection models, network security is particularly important given the sensitive data involved. The training cluster might process complete transaction histories, customer identity information, and other regulated data that must be protected from unauthorized access. The isolated network configuration ensures that this data remains within controlled boundaries during the resource-intensive training process.
Container security for ML workloads
Secure your ML containers:
# Dockerfile with security best practices
FROM python:3.9-slim
# Create non-root user
RUN groupadd -r mluser && useradd -r -g mluser mluser
# Install only necessary packages
RUN apt-get update && apt-get install -y --no-install-recommends \
wget \
&& rm -rf /var/lib/apt/lists/*
# Install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy only necessary files
COPY --chown=mluser:mluser model/ /opt/ml/model/
COPY --chown=mluser:mluser code/ /opt/ml/code/
# Set work directory and user
WORKDIR /opt/ml
USER mluser
# Set entrypoint
ENTRYPOINT ["python", "/opt/ml/code/inference.py"]
Container security is critical for ML workloads, as containers are the primary deployment mechanism for both training and inference. The Dockerfile above demonstrates several container security best practices:
Minimal Base Image: Using
python:3.9-slimrather than a full distribution reduces the attack surface by minimizing the number of installed packages and potential vulnerabilities.Non-Root User: Creating and using a dedicated non-root user (
mluser) prevents the container process from having unnecessary privileges, limiting the potential impact of security breaches.Minimal Dependencies: Installing only the specific packages needed (
wgetin this example) and cleaning up package manager caches reduces both the container size and the attack surface.Clean File Ownership: Using
--chown=mluser:mluserwhen copying files ensures that the application files are owned by the non-root user, preventing privilege escalation through file permission issues.Explicit Entrypoint: Setting a specific entrypoint limits what commands can be run in the container, preventing attackers from executing arbitrary code even if they gain access to the container.
In addition to these Dockerfile practices, ML container security should also address:
- Image Scanning: Regular vulnerability scanning of container images to identify and remediate security issues
- Image Signing: Cryptographic signing of images to verify their integrity and authenticity
- Runtime Security: Monitoring container behavior for anomalies or potential security breaches
- Resource Limits: Setting appropriate CPU, memory, and storage limits to prevent denial of service
- Secrets Management: Securely providing necessary credentials and keys to containers without embedding them in images
For fraud detection models deployed in containers, these security practices help protect both the model itself and the sensitive data it processes. By following the principle of least privilege and minimizing the attack surface, the container configuration reduces the risk of compromise even in high-stakes financial applications.
6. Monitoring and observability for ML workloads
Machine learning systems require specialized monitoring beyond traditional application metrics. In addition to infrastructure and application performance, ML monitoring must track model accuracy, data drift, concept drift, and other ML-specific concerns. Comprehensive monitoring is particularly crucial for fraud detection systems, where model degradation can have immediate financial impact.
Metrics collection and visualization
Implement ML-specific monitoring:
# Setting up CloudWatch custom metrics for ML models
import boto3
from datetime import datetime
cloudwatch = boto3.client('cloudwatch')
def publish_inference_metrics(model_name, latency, throughput):
cloudwatch.put_metric_data(
Namespace='ML/ModelPerformance',
MetricData=[
{
'MetricName': 'InferenceLatency',
'Dimensions': [
{
'Name': 'ModelName',
'Value': model_name
},
],
'Value': latency,
'Unit': 'Milliseconds',
'Timestamp': datetime.now()
},
{
'MetricName': 'InferenceThroughput',
'Dimensions': [
{
'Name': 'ModelName',
'Value': model_name
},
],
'Value': throughput,
'Unit': 'Count/Second',
'Timestamp': datetime.now()
}
]
)
This code demonstrates how to publish custom metrics to CloudWatch for tracking ML model performance. For fraud detection systems, which must maintain both accuracy and performance under varying load conditions, operational metrics like latency and throughput are crucial.
The metrics collection approach includes several important elements:
Custom Namespace: Using a dedicated namespace (
ML/ModelPerformance) separates ML metrics from other application metrics, making it easier to create focused dashboards and alerts.Dimensional Data: Including the model name as a dimension allows metrics to be tracked separately for each model, facilitating comparison between models and analysis of individual model performance.
Latency Tracking: Monitoring inference latency is critical for real-time systems like fraud detection, where decisions must be made within strict time constraints (sub-100ms in this case).
Throughput Monitoring: Tracking the rate of inference requests helps identify capacity issues and ensure that the system can handle peak loads.
For a comprehensive ML monitoring system, additional metrics might include:
- Model Accuracy: How well the model's predictions match ground truth
- Feature Distribution: Statistical properties of input features over time
- Prediction Distribution: Distribution of model outputs or confidence scores
- Resource Utilization: CPU, memory, GPU, and network usage during inference
- Error Rates: Frequency and types of errors during inference
- Cache Hit Rates: Effectiveness of feature or prediction caching
- Data Lag: Delays in availability of features or training data
These metrics should be visualized in dashboards that provide both overview and detailed views, allowing operators to quickly identify issues while also supporting in-depth analysis. For fraud detection, dashboards might include views specific to different fraud types, customer segments, or transaction channels.
Model performance monitoring
Configure SageMaker Model Monitor:
# Setting up a custom model quality monitor
from sagemaker.model_monitor import ModelQualityMonitor, EndpointInput
from sagemaker.model_monitor.dataset_format import DatasetFormat
model_quality_monitor = ModelQualityMonitor(
role=role,
instance_count=1,
instance_type='ml.m5.xlarge',
volume_size_in_gb=20,
max_runtime_in_seconds=3600
)
# Create a baseline for monitoring
model_quality_monitor.suggest_baseline(
job_name='model-quality-baseline-job',
baseline_dataset='s3://bucket/path/to/baseline/dataset.csv',
dataset_format=DatasetFormat.csv(header=True),
problem_type='Regression',
inference_attribute='prediction',
ground_truth_attribute='actual',
output_s3_uri='s3://bucket/path/to/output'
)
# Set up a monitoring schedule
model_quality_monitor.create_monitoring_schedule(
monitor_schedule_name='model-quality-monitoring-schedule',
endpoint_input=EndpointInput(
endpoint_name='endpoint-name',
destination='/opt/ml/processing/input',
inference_attribute='prediction'
),
ground_truth_input=ground_truth_input,
output_s3_uri='s3://bucket/path/to/monitoring/output',
statistics=model_quality_monitor.baseline_statistics(),
constraints=model_quality_monitor.suggested_constraints(),
schedule_cron_expression='cron(0 * ? * * *)', # Hourly monitoring
enable_cloudwatch_metrics=True
)
SageMaker Model Monitor provides automated monitoring for ML models, detecting issues like data drift and model performance degradation. The configuration above sets up quality monitoring, which compares model predictions to ground truth labels as they become available.
For fraud detection, model quality monitoring is essential because:
- Fraud Patterns Evolve: Fraudsters continuously adapt their tactics, causing model performance to degrade if not updated
- Data Distributions Change: Legitimate transaction patterns change due to factors like seasons, events, or economic conditions
- Model Bias Can Emerge: Over time, models may develop biases against certain customer segments or transaction types
- Regulatory Scrutiny: Financial regulators increasingly require active monitoring of model performance and fairness
The monitoring configuration includes several key components:
Baseline Definition: The
suggest_baselinemethod analyzes a representative dataset to establish expected statistical properties and performance metrics, creating a reference point for future comparisons.Scheduled Evaluation: The hourly schedule (
cron(0 * ? * * *)) ensures regular evaluation of model performance, allowing for timely detection of degradation.Ground Truth Integration: The configuration expects ground truth data (actual fraud/non-fraud labels) to be provided for comparison with model predictions, enabling accurate performance assessment.
CloudWatch Integration: Enabling CloudWatch metrics allows for alerting and visualization of model quality trends over time.
In practice, ground truth for fraud detection often comes with a delay, as it takes time to confirm whether transactions were truly fraudulent or legitimate. The monitoring system must account for this delay by comparing predictions to ground truth labels that become available later, often through a specialized data pipeline.
Data drift and model drift detection
Implement advanced drift detection:
# Setting up data drift detection for NLP models using embeddings
from sagemaker.model_monitor import DataQualityMonitor
# Create a custom preprocessing script for text embeddings
preprocessing_script = """
import numpy as np
import pandas as pd
from transformers import AutoTokenizer, AutoModel
import torch
def get_embeddings(texts):
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
# Mean pooling
token_embeddings = model_output[0]
attention_mask = encoded_input['attention_mask']
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return (sum_embeddings / sum_mask).numpy()
def preprocess_handler(data, context):
df = pd.read_json(data)
text_column = 'text' # Adjust based on your data
embeddings = get_embeddings(df[text_column].tolist())
return pd.DataFrame(embeddings).to_json(orient='records')
"""
# Configure drift detection with the custom preprocessing
drift_monitor = DataQualityMonitor(
role=role,
instance_count=1,
instance_type='ml.m5.xlarge',
volume_size_in_gb=20,
max_runtime_in_seconds=3600,
preprocessing_script=preprocessing_script
)
Data drift and model drift are critical concerns for ML systems, particularly in dynamic domains like fraud detection where patterns change frequently. The code above demonstrates an advanced approach to drift detection for text data using embeddings, which captures semantic shifts that might not be apparent in simpler statistical measures.
This approach is particularly valuable for monitoring components of the fraud detection system that process text data, such as transaction descriptions, customer communications, or merchant information. By converting text to embeddings, the monitoring system can detect subtle changes in language patterns that might indicate emerging fraud tactics or shifts in legitimate transaction descriptions.
The monitoring approach includes several sophisticated elements:
Custom Preprocessing: The script converts text data to vector embeddings using a pre-trained transformer model (
sentence-transformers/all-MiniLM-L6-v2), capturing semantic meaning rather than just surface-level text properties.Mean Pooling: The code implements mean pooling to create a fixed-length vector representation of text inputs of varying length, suitable for statistical comparison over time.
Attention Mask Handling: The preprocessing properly accounts for padding tokens using the attention mask, ensuring that only actual content influences the embeddings.
Format Conversion: The handler converts between JSON and DataFrame formats to integrate with SageMaker's monitoring infrastructure.
Beyond text data, comprehensive drift detection for fraud detection systems should monitor multiple aspects:
- Feature Drift: Changes in the statistical properties of individual features
- Covariate Shift: Changes in the relationships between features
- Concept Drift: Changes in the relationship between features and targets (e.g., what constitutes fraud)
- Prediction Drift: Changes in the distribution of model outputs
- Performance Drift: Degradation in model accuracy, precision, recall, or other metrics
For fraud detection, different types of drift have different implications. For example, feature drift in transaction amounts might reflect inflation or seasonal spending patterns, while concept drift might indicate new fraud tactics that the model hasn't learned to detect. The monitoring system should distinguish between these types of drift to guide appropriate responses.
Advanced alerting and automated remediation
Configure automated response to detected issues:
# Setting up an automated remediation workflow
import boto3
events_client = boto3.client('events')
sfn_client = boto3.client('stepfunctions')
# Create an EventBridge rule that triggers when model drift is detected
events_client.put_rule(
Name='ModelDriftDetectedRule',
EventPattern=json.dumps({
"source": ["aws.sagemaker"],
"detail-type": ["SageMaker Model Quality Monitor Drift Detected"],
"detail": {
"monitoringScheduleName": ["your-monitoring-schedule-name"]
}
}),
State='ENABLED'
)
# Target a Step Function workflow for automated model retraining
events_client.put_targets(
Rule='ModelDriftDetectedRule',
Targets=[
{
'Id': 'ModelRetrainingTarget',
'Arn': 'arn:aws:states:region:account-id:stateMachine:ModelRetrainingWorkflow',
'RoleArn': 'arn:aws:iam::account-id:role/EventBridgeToStepFunctionsRole'
}
]
)
Detecting issues is only valuable if appropriate actions follow. The code above sets up automated remediation using AWS EventBridge and Step Functions, creating a serverless workflow that responds to detected model drift without manual intervention.
This automated remediation approach offers several advantages:
Rapid Response: Automated workflows trigger immediately when drift is detected, reducing the time during which the model operates with degraded performance.
Consistent Process: The Step Function workflow ensures that remediation follows a consistent, documented process, reducing the risk of errors during manual interventions.
Audit Trail: The execution history of the Step Function provides a clear record of when and why remediation was triggered, valuable for compliance and operational reviews.
Scalable Operations: Automation allows the ML operations team to manage more models with the same resources, as routine issues are handled without manual intervention.
For fraud detection, automated remediation might include several strategies:
- Model Retraining: Triggering the continuous learning pipeline to update the model with recent data
- Feature Recalibration: Adjusting feature normalization or transformation parameters based on current distributions
- Threshold Adjustment: Temporarily modifying decision thresholds to maintain target precision or recall
- Fallback Activation: Routing traffic to a more robust fallback model while the primary model is being updated
- Human Review Expansion: Lowering thresholds for human review to compensate for reduced model confidence
The appropriate remediation strategy depends on the nature and severity of the detected issue. For critical problems that might indicate security incidents (like sudden, dramatic shifts in transaction patterns), the workflow might include notification of security teams in addition to technical remediation steps.
In regulated environments like financial services, automated remediation must be balanced with governance requirements. The Step Function workflow might include approval steps for certain actions, ensuring that significant changes receive appropriate review while still maintaining responsiveness.
7. Cost optimization techniques
Machine learning workloads can be expensive, particularly for large-scale applications like fraud detection that require continuous operation and frequent retraining. Cost optimization strategies help balance performance requirements with budget constraints, ensuring that resources are used efficiently.
Spot instance strategies for training
Leverage spot instances for significant cost savings:
# Configuring SageMaker managed spot training with checkpointing
from sagemaker.estimator import Estimator
estimator = Estimator(
image_uri='your-training-image',
role='your-role-arn',
instance_count=4,
instance_type='ml.p4d.24xlarge',
volume_size=100,
max_run=86400,
input_mode='File',
output_path='s3://your-bucket/output',
use_spot_instances=True,
max_wait=172800, # Maximum time to wait for spot instances (48 hours)
checkpoint_s3_uri='s3://your-bucket/checkpoints',
checkpoint_local_path='/opt/ml/checkpoints'
)
# Configure distributed training
estimator.distribution = {
'torch_distributed': {
'enabled': True
}
}
# Start training job
estimator.fit('s3://your-bucket/training-data')
Spot instances offer substantial cost savings—often 70-90% compared to on-demand pricing—but introduce the risk of interruption when AWS reclaims the capacity for on-demand users. The configuration above demonstrates how to use spot instances effectively for ML training while mitigating the interruption risk.
Key elements of this approach include:
Managed Spot Training: SageMaker's managed spot training (
use_spot_instances=True) handles the complexity of requesting and using spot instances, automatically bidding according to current market conditions.Checkpointing: The configuration specifies both local and S3 checkpoint paths, enabling the training job to save progress periodically. If a spot instance is reclaimed, training can resume from the last checkpoint rather than starting over.
Max Wait Time: The
max_waitparameter (48 hours in this example) defines how long SageMaker will wait for spot capacity if instances are not immediately available, allowing for flexibility in job scheduling.Distributed Configuration: The distribution configuration enables efficient use of multiple instances, maximizing the value of the spot capacity when it's available.
For fraud detection model training, spot instances are particularly valuable because:
- Training jobs are typically non-urgent and can tolerate some delay
- Periodic retraining is predictable and can be scheduled during periods of lower spot pricing
- Model training is computationally intensive but intermittent, ideal for spot economics
- Checkpointing is already a best practice for resilience, making spot interruptions manageable
Organizations using spot instances for ML training typically see cost reductions of 60-80% for training infrastructure, which can translate to millions of dollars annually for large-scale operations. These savings can be redirected to other aspects of the ML system, such as more extensive feature engineering or more sophisticated model architectures.
Intelligent auto-scaling
Configure advanced auto-scaling for inference endpoints:
# Setting up an advanced auto-scaling configuration for a SageMaker endpoint
import boto3
client = boto3.client('sagemaker')
client.update_endpoint_auto_scaling_configuration(
EndpointName='your-endpoint-name',
ServiceNamespace='sagemaker',
ResourceId='endpoint/your-endpoint-name/variant/your-variant-name',
MinCapacity=1,
MaxCapacity=20,
RoleARN='your-role-arn',
ScalableDimension='sagemaker:variant:DesiredInstanceCount',
ScalingPolicies=[
{
'PolicyName': 'InvocationsScalingPolicy',
'PolicyType': 'TargetTrackingScaling',
'TargetTrackingScalingPolicyConfiguration': {
'TargetValue': 70.0, # Target utilization percentage
'PredefinedMetricSpecification': {
'PredefinedMetricType': 'SageMakerVariantInvocationsPerInstance'
},
'ScaleInCooldown': 300, # 5 minutes
'ScaleOutCooldown': 60, # 1 minute
'DisableScaleIn': False
}
},
{
'PolicyName': 'GPUUtilizationScalingPolicy',
'PolicyType': 'TargetTrackingScaling',
'TargetTrackingScalingPolicyConfiguration': {
'TargetValue': 60.0, # Target GPU utilization
'CustomizedMetricSpecification': {
'MetricName': 'GPUUtilization',
'Namespace': 'AWS/SageMaker',
'Dimensions': [
{
'Name': 'EndpointName',
'Value': 'your-endpoint-name'
},
{
'Name': 'VariantName',
'Value': 'your-variant-name'
}
],
'Statistic': 'Average',
'Unit': 'Percent'
},
'ScaleInCooldown': 300,
'ScaleOutCooldown': 60,
'DisableScaleIn': False
}
}
]
)
Inference endpoints can be a major cost center for ML systems, particularly for applications like fraud detection that require continuous operation. Auto-scaling helps optimize costs by matching capacity to demand, avoiding both over-provisioning (wasted resources) and under-provisioning (performance issues).
The auto-scaling configuration above demonstrates several advanced techniques:
Multiple Scaling Policies: The configuration includes two scaling policies—one based on invocation count and another on GPU utilization—providing more nuanced scaling decisions based on both throughput and resource utilization.
Target Tracking: Both policies use target tracking, which maintains a specified utilization level (70% for invocations, 60% for GPU) by adjusting capacity automatically. This approach is simpler and more effective than threshold-based scaling for most workloads.
Asymmetric Cooldowns: The configuration uses different cooldown periods for scaling out (1 minute) and scaling in (5 minutes), reflecting the different urgency of these operations. Rapid scale-out ensures that the system can handle traffic spikes, while slower scale-in prevents oscillation.
Custom Metrics: The GPU utilization policy uses a custom metric, demonstrating how auto-scaling can be based on application-specific indicators beyond the standard metrics.
For fraud detection systems, intelligent auto-scaling is particularly valuable because:
- Transaction volume varies predictably with time of day, day of week, and seasonal patterns
- Unexpected traffic spikes may indicate fraud attempts that require immediate handling
- Maintaining low latency during peak periods is critical to user experience
- Resource efficiency directly impacts the cost per transaction analyzed
To maximize the benefits of auto-scaling, the fraud detection system should be designed with scaling in mind:
- Stateless components that can scale horizontally without coordination
- Efficient instance warm-up to minimize the delay when adding capacity
- Graceful shutdown procedures to prevent transaction loss during scale-in
- Load balancing that distributes traffic effectively across instances
Properly configured auto-scaling can reduce inference costs by 30-50% compared to static provisioning, while maintaining or improving performance during peak periods.
Storage lifecycle management
Optimize storage costs for ML artifacts:
# Setting up a lifecycle policy for ML artifacts in S3
import boto3
s3 = boto3.client('s3')
# Create a lifecycle configuration for ML artifacts
lifecycle_config = {
'Rules': [
{
'ID': 'ArchiveOldCheckpoints',
'Status': 'Enabled',
'Filter': {
'Prefix': 'checkpoints/'
},
'Transitions': [
{
'Days': 30,
'StorageClass': 'STANDARD_IA'
},
{
'Days': 90,
'StorageClass': 'GLACIER'
}
],
'Expiration': {
'Days': 365
}
},
{
'ID': 'ArchiveOldModels',
'Status': 'Enabled',
'Filter': {
'Prefix': 'models/'
},
'Transitions': [
{
'Days': 60,
'StorageClass': 'STANDARD_IA'
},
{
'Days': 180,
'StorageClass': 'GLACIER'
}
]
},
{
'ID': 'DeleteTemporaryArtifacts',
'Status': 'Enabled',
'Filter': {
'Prefix': 'temp/'
},
'Expiration': {
'Days': 7
}
}
]
}
# Apply the lifecycle configuration to an S3 bucket
s3.put_bucket_lifecycle_configuration(
Bucket='your-ml-artifacts-bucket',
LifecycleConfiguration=lifecycle_config
)
ML workflows generate large volumes of data artifacts, including interim training data, model checkpoints, evaluation results, and model versions. Without proper management, storage costs for these artifacts can grow rapidly, particularly for iterative development and continuous training pipelines.
The lifecycle configuration above demonstrates a structured approach to managing ML artifacts based on their usage patterns and retention requirements:
Tiered Storage Strategy: The configuration defines different storage tiers based on access frequency, moving checkpoints from standard storage to Standard-IA after 30 days and to Glacier after 90 days, reducing storage costs for rarely accessed data.
Different Policies for Different Artifacts: Each type of artifact (checkpoints, models, temporary files) has a policy tailored to its specific usage pattern and retention requirements, recognizing that not all ML data has the same lifecycle.
Automatic Cleanup: Temporary artifacts are automatically deleted after 7 days, preventing accumulation of transient data that is no longer needed.
Long-term Archiving: Completed models are preserved in increasingly cost-effective storage tiers, maintaining the ability to reference or restore historical models when needed while minimizing ongoing storage costs.
For fraud detection systems, storage lifecycle management is particularly important because:
- Historical transaction data and models may need to be retained for compliance and audit purposes
- Model lineage must be maintained to explain past decisions if challenged
- Development and experimentation generate large volumes of intermediate artifacts
- Regular retraining creates a continuous stream of new model versions and evaluation results
An effective storage lifecycle strategy should align with both operational needs and governance requirements:
- Regulatory requirements may dictate minimum retention periods for certain artifacts
- Model governance policies may require preserving the exact training data used for each model version
- Business needs may require occasional access to historical models for comparison or analysis
- Operational efficiency benefits from cleaning up unnecessary artifacts that clutter development environments
By implementing comprehensive storage lifecycle management, organizations can reduce ML storage costs by 40-60% while maintaining compliance with retention requirements and preserving access to important historical artifacts.
Network cost optimization
Configure SageMaker processing jobs to minimize cross-AZ traffic:
# Configure a SageMaker processing job to minimize network costs
from sagemaker.processing import ProcessingInput, ProcessingOutput, ScriptProcessor
processor = ScriptProcessor(
image_uri='your-processing-image',
role='your-role-arn',
instance_count=1,
instance_type='ml.m5.xlarge',
network_config=NetworkConfig(
subnets=['subnet-in-same-az-as-data'],
security_group_ids=['sg-id'],
enable_network_isolation=True
)
)
processor.run(
code='preprocessing.py',
inputs=[
ProcessingInput(
source='s3://your-bucket/input-data',
destination='/opt/ml/processing/input',
s3_data_distribution_type='ShardedByS3Key' # Optimizes data distribution
)
],
outputs=[
ProcessingOutput(
output_name='processed_data',
source='/opt/ml/processing/output',
destination='s3://your-bucket/processed-data'
)
]
)
Network data transfer can be a significant but often overlooked cost in ML workflows, particularly for large-scale data processing and distributed training. AWS charges for data transfer between availability zones (AZs) and for outbound traffic from AWS to the internet, making network optimization an important cost consideration.
The configuration above demonstrates several network cost optimization techniques:
AZ-Aware Placement: By specifying a subnet in the same availability zone as the data source, the configuration minimizes cross-AZ data transfer costs. This is particularly important for large datasets where transfer costs can be substantial.
Data Sharding: The
s3_data_distribution_type='ShardedByS3Key'parameter optimizes how data is distributed to processing instances, ensuring that each instance processes a contiguous range of keys rather than scattered objects, which can reduce redundant data transfers.Network Isolation: Enabling network isolation prevents the processing job from making unnecessary network calls that might incur data transfer costs, particularly for outbound internet traffic.
Single-Instance Processing: For this particular job, using a single instance (
instance_count=1) eliminates inter-node communication costs that would occur in distributed processing. For larger jobs where multiple instances are necessary, placing all instances in the same subnet minimizes transfer costs.
For fraud detection systems, network cost optimization should consider the entire data flow:
- Ingestion: Efficiently streaming transaction data from source systems to AWS
- Processing: Transforming raw data into features without unnecessary transfers
- Training: Distributing training data to model training clusters efficiently
- Inference: Deploying models close to where they will be accessed
- Monitoring: Collecting metrics and logs without excessive data movement
Network optimization goes beyond cost considerations to also impact performance and reliability:
- Reduced network hops can lower latency for real-time inference
- Minimized dependencies on cross-AZ communication improve resilience to AZ issues
- Efficient data movement reduces bottlenecks in processing pipelines
By carefully designing network topology and data flows, organizations can reduce network transfer costs by 30-50% while improving system performance and reliability.
Savings Plans and reserved instances
Implement a hybrid commitment strategy:
# Using AWS Cost Explorer API to analyze ML workload patterns
import boto3
ce = boto3.client('ce')
# Analyze ML instance usage to inform Savings Plans purchases
response = ce.get_cost_and_usage(
TimePeriod={
'Start': '2025-01-01',
'End': '2025-03-31'
},
Granularity='MONTHLY',
Filter={
'And': [
{
'Dimensions': {
'Key': 'SERVICE',
'Values': ['Amazon SageMaker']
}
},
{
'Tags': {
'Key': 'Workload',
'Values': ['ML-Training']
}
}
]
},
Metrics=['UnblendedCost', 'UsageQuantity'],
GroupBy=[
{
'Type': 'DIMENSION',
'Key': 'INSTANCE_TYPE'
}
]
)
For predictable ML workloads, commitment-based pricing models like Savings Plans and Reserved Instances can provide substantial discounts compared to on-demand pricing. These models offer lower rates in exchange for commitments to use a certain amount of compute capacity over a period (typically 1 or 3 years).
The code above demonstrates how to analyze historical usage patterns to inform commitment purchasing decisions. By examining past usage broken down by instance type, organizations can identify stable, predictable workloads that are good candidates for commitments while leaving variable workloads on on-demand or spot pricing.
For ML systems with different components, a hybrid approach typically works best:
Steady-State Inference: Baseline inference capacity that runs continuously is ideal for Compute Savings Plans or SageMaker Savings Plans, which offer up to 64% savings compared to on-demand pricing.
Regular Training Jobs: For models that are retrained on a predictable schedule with consistent resource requirements, partial Reserved Instances (RI) coverage can provide significant savings.
Variable Loads: Peak inference capacity and exploratory training jobs are better suited for on-demand pricing or spot instances, providing flexibility without unused commitments.
Development Environments: Interactive development instances that run during business hours might benefit from scheduled automatic shutdown during off-hours rather than commitments.
For fraud detection specifically, commitment planning might look like:
- Real-time Scoring Endpoint: 80% coverage with SageMaker Savings Plans for the baseline capacity needed 24/7
- Daily Model Retraining: Reserved Instances for predictable daily jobs
- Quarterly Deep Training: On-demand or spot for less frequent, intensive training
- Experimentation Environment: Automatic shutdown outside business hours to minimize costs
Effective commitment management can reduce overall compute costs by 30-45% compared to pure on-demand pricing, but requires careful analysis and planning to avoid paying for unused commitments.
The Cost Explorer analysis provides the data needed to optimize this approach, showing historical usage patterns that inform commitment levels. Regular review of commitment utilization and adjustment of the commitment portfolio helps maintain optimal coverage as workloads evolve.
Conclusion
Deploying sophisticated AI/ML workloads on AWS requires a holistic approach that addresses compute optimization, infrastructure management, security, monitoring, and cost efficiency. The financial fraud detection implementation showcases how these elements can be integrated into a cohesive solution that meets stringent performance, security, and scalability requirements.
Organizations can achieve significant performance improvements and cost savings by selecting appropriate hardware accelerators, implementing efficient distributed training architectures, applying model optimization techniques, and leveraging AWS's comprehensive suite of ML services. The infrastructure-as-code examples provided using CloudFormation/CDK, Terraform, and Pulumi enable consistent, repeatable deployments while maintaining security and compliance.
As AI workloads continue to grow in complexity and scale, the importance of proper architecture, optimization, and operational excellence will only increase. By following the technical practices outlined in this guide, organizations can build robust, efficient, and secure AI/ML systems on AWS.