
































































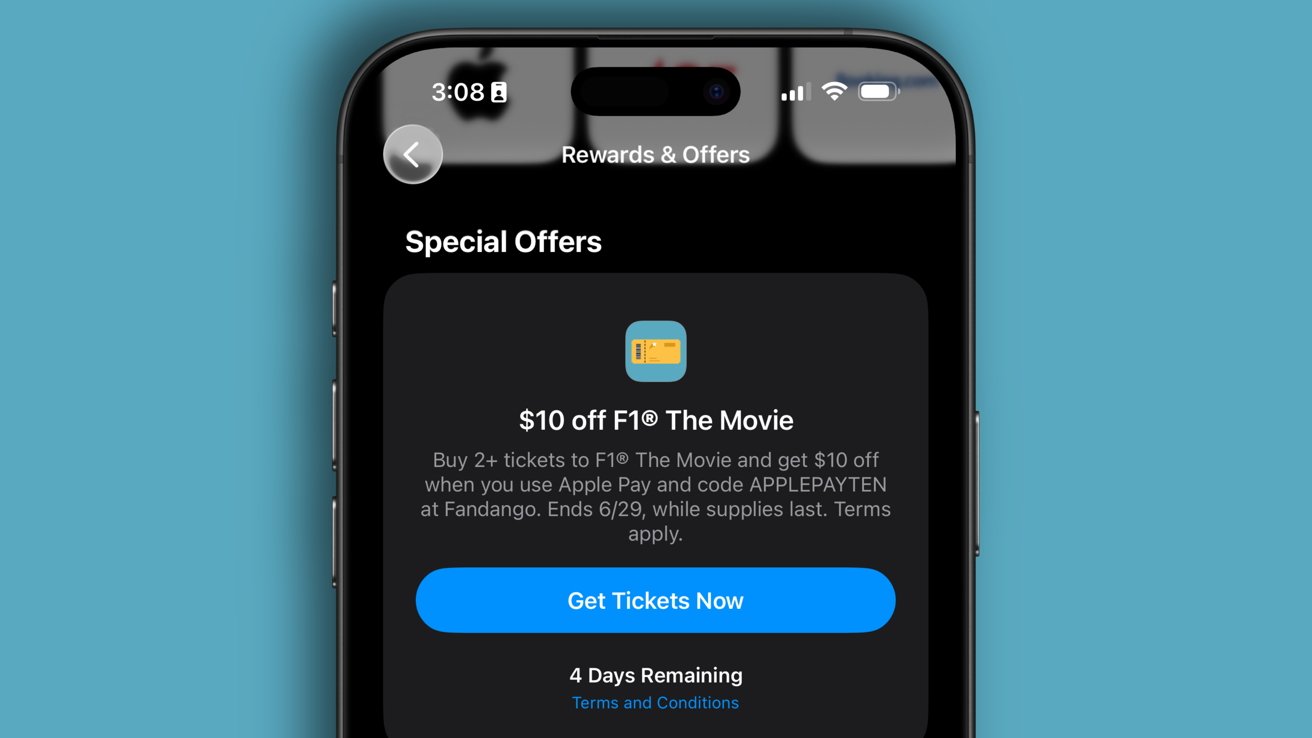
![Apple Releases New Beta Firmware for AirPods Pro 2 and AirPods 4 [8A293c]](https://www.iclarified.com/images/news/97704/97704/97704-640.jpg)














![Samsung teasing Galaxy Buds ‘Core’ ahead of launch later this week [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2023/10/samsung-galaxy-buds-fe-5.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

























































































_marcos_alvarado_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































































































![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)























































































































































































.png?#)


























































Getting Started with Microsoft’s Presidio: A Step-by-Step Guide to Detecting and Anonymizing Personally Identifiable Information PII in Text
In this tutorial, we will explore how to use Microsoft’s Presidio, an open-source framework designed for detecting, analyzing, and anonymizing personally identifiable information (PII) in free-form text. Built on top of the efficient spaCy NLP library, Presidio is both lightweight and modular, making it easy to integrate into real-time applications and pipelines. We will cover […] The post Getting Started with Microsoft’s Presidio: A Step-by-Step Guide to Detecting and Anonymizing Personally Identifiable Information PII in Text appeared first on MarkTechPost.

In this tutorial, we will explore how to use Microsoft’s Presidio, an open-source framework designed for detecting, analyzing, and anonymizing personally identifiable information (PII) in free-form text. Built on top of the efficient spaCy NLP library, Presidio is both lightweight and modular, making it easy to integrate into real-time applications and pipelines.
We will cover how to:
- Set up and install the necessary Presidio packages
- Detect common PII entities such as names, phone numbers, and credit card details
- Define custom recognizers for domain-specific entities (e.g., PAN, Aadhaar)
- Create and register custom anonymizers (like hashing or pseudonymization)
- Reuse anonymization mappings for consistent re-anonymization
Installing the libraries
To get started with Presidio, you’ll need to install the following key libraries:
- presidio-analyzer: This is the core library responsible for detecting PII entities in text using built-in and custom recognizers.
- presidio-anonymizer: This library provides tools to anonymize (e.g., redact, replace, hash) the detected PII using configurable operators.
- spaCy NLP model (en_core_web_lg): Presidio uses spaCy under the hood for natural language processing tasks like named entity recognition. The en_core_web_lg model provides high-accuracy results and is recommended for English-language PII detection.
pip install presidio-analyzer presidio-anonymizer
python -m spacy download en_core_web_lgYou might need to restart the session to install the libraries, if you are using Jupyter/Colab.
Presidio Analyzer
Basic PII Detection
In this block, we initialize the Presidio Analyzer Engine and run a basic analysis to detect a U.S. phone number from a sample text. We also suppress lower-level log warnings from the Presidio library for cleaner output.
The AnalyzerEngine loads spaCy’s NLP pipeline and predefined recognizers to scan the input text for sensitive entities. In this example, we specify PHONE_NUMBER as the target entity.
import logging
logging.getLogger("presidio-analyzer").setLevel(logging.ERROR)
from presidio_analyzer import AnalyzerEngine
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My phone number is 212-555-5555",
entities=["PHONE_NUMBER"],
language='en')
print(results)
Creating a Custom PII Recognizer with a Deny List (Academic Titles)
This code block shows how to create a custom PII recognizer in Presidio using a simple deny list, ideal for detecting fixed terms like academic titles (e.g., “Dr.”, “Prof.”). The recognizer is added to Presidio’s registry and used by the analyzer to scan input text.
While this tutorial covers only the deny list approach, Presidio also supports regex-based patterns, NLP models, and external recognizers. For those advanced methods, refer to the official docs: Adding Custom Recognizers.
Presidio Analyzer
Basic PII Detection
In this block, we initialize the Presidio Analyzer Engine and run a basic analysis to detect a U.S. phone number from a sample text. We also suppress lower-level log warnings from the Presidio library for cleaner output.
The AnalyzerEngine loads spaCy’s NLP pipeline and predefined recognizers to scan the input text for sensitive entities. In this example, we specify PHONE_NUMBER as the target entity.
import logging
logging.getLogger("presidio-analyzer").setLevel(logging.ERROR)
from presidio_analyzer import AnalyzerEngine
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My phone number is 212-555-5555",
entities=["PHONE_NUMBER"],
language='en')
print(results)Creating a Custom PII Recognizer with a Deny List (Academic Titles)
This code block shows how to create a custom PII recognizer in Presidio using a simple deny list, ideal for detecting fixed terms like academic titles (e.g., “Dr.”, “Prof.”). The recognizer is added to Presidio’s registry and used by the analyzer to scan input text.
While this tutorial covers only the deny list approach, Presidio also supports regex-based patterns, NLP models, and external recognizers. For those advanced methods, refer to the official docs: Adding Custom Recognizers.
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, RecognizerRegistry
# Step 1: Create a custom pattern recognizer using deny_list
academic_title_recognizer = PatternRecognizer(
supported_entity="ACADEMIC_TITLE",
deny_list=["Dr.", "Dr", "Professor", "Prof."]
)
# Step 2: Add it to a registry
registry = RecognizerRegistry()
registry.load_predefined_recognizers()
registry.add_recognizer(academic_title_recognizer)
# Step 3: Create analyzer engine with the updated registry
analyzer = AnalyzerEngine(registry=registry)
# Step 4: Analyze text
text = "Prof. John Smith is meeting with Dr. Alice Brown."
results = analyzer.analyze(text=text, language="en")
for result in results:
print(result)
Presidio Anonymizer
This code block demonstrates how to use the Presidio Anonymizer Engine to anonymize detected PII entities in a given text. In this example, we manually define two PERSON entities using RecognizerResult, simulating output from the Presidio Analyzer. These entities represent the names “Bond” and “James Bond” in the sample text.
We use the “replace” operator to substitute both names with a placeholder value (“BIP”), effectively anonymizing the sensitive data. This is done by passing an OperatorConfig with the desired anonymization strategy (replace) to the AnonymizerEngine.
This pattern can be easily extended to apply other built-in operations like “redact”, “hash”, or custom pseudonymization strategies.
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import RecognizerResult, OperatorConfig
# Initialize the engine:
engine = AnonymizerEngine()
# Invoke the anonymize function with the text,
# analyzer results (potentially coming from presidio-analyzer) and
# Operators to get the anonymization output:
result = engine.anonymize(
text="My name is Bond, James Bond",
analyzer_results=[
RecognizerResult(entity_type="PERSON", start=11, end=15, score=0.8),
RecognizerResult(entity_type="PERSON", start=17, end=27, score=0.8),
],
operators={"PERSON": OperatorConfig("replace", {"new_value": "BIP"})},
)
print(result)
Custom Entity Recognition, Hash-Based Anonymization, and Consistent Re-Anonymization with Presidio
In this example, we take Presidio a step further by demonstrating:
 Defining custom PII entities (e.g., Aadhaar and PAN numbers) using regex-based PatternRecognizers
Defining custom PII entities (e.g., Aadhaar and PAN numbers) using regex-based PatternRecognizers


