













![Lowest Prices Ever: Apple Pencil Pro Just $79.99, USB-C Pencil Only $49.99 [Deal]](https://www.iclarified.com/images/news/96863/96863/96863-640.jpg)
![Apple Releases iOS 18.4 RC 2 and iPadOS 18.4 RC 2 to Developers [Download]](https://www.iclarified.com/images/news/96860/96860/96860-640.jpg)













































































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)
































































































































![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)





































.png?#)





















![Mini Review: Rendering Ranger: R2 [Rewind] (Switch) - A Novel Run 'N' Gun/Shooter Hybrid That's Finally Affordable](https://images.nintendolife.com/0e9d68643dde0/large.jpg?#)

























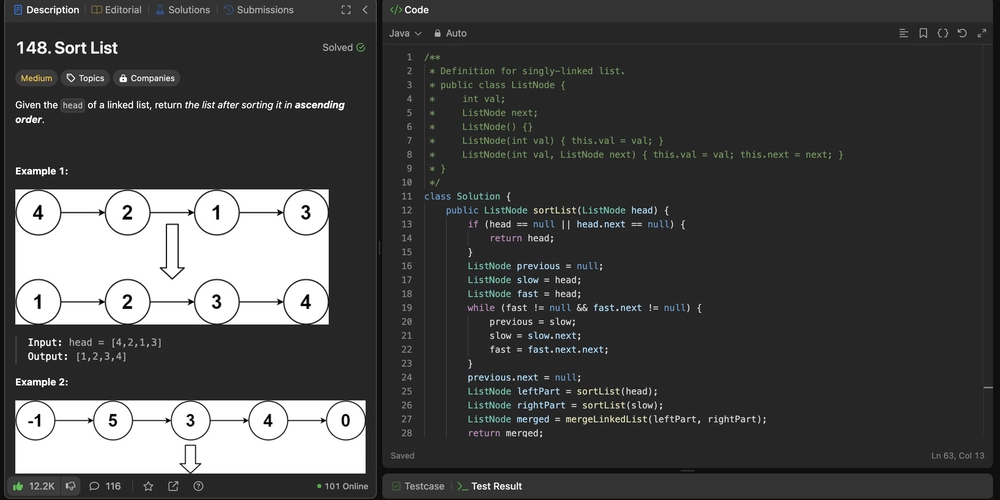
How Notion Handles 200 Billion Notes Without Crashing: A Technical Deep Dive
Notion isn’t just a note-taking app—it’s a real-time, collaborative database masquerading as a minimalist UI. But how does it handle 200+ billion blocks (database entries) without buckling under pressure? Let’s peel back the layers. Notion’s Data Model: A Database in Disguise Every action in Notion—typing text, toggling a checkbox—creates a block, stored as a row in PostgreSQL. Here’s the schema of a block: CREATE TABLE blocks ( id UUID PRIMARY KEY, type VARCHAR(50), -- 'paragraph', 'checkbox', etc. parent_id UUID, -- Parent block (if nested) workspace_id UUID, -- Critical for sharding properties JSONB -- Flexible content storage ); Fun Fact: When you hit ↑ or ↓ in Notion, it’s not moving a cursor—it’s jumping between database rows. A "simple" page with 10 elements = 10+ database queries! The Scaling Crisis: 20 Billion Blocks and Chaos Why Postgres Almost Died Single database: Pre-2021, all blocks lived in one PostgreSQL instance. Indexes bloated: Querying a workspace’s blocks required scanning millions of rows. Writes stalled: Concurrent edits from 100M users? Good luck. The Sharding Savior Notion split data into 480 logical shards (32 machines × 15 shards each). How? Shard Key: workspace_id (every block belongs to one workspace). Routing: Application code directs queries like: shard = hash(workspace_id) % 480 # Simple but effective Pro Tip: Sharding isn’t free. Cross-shard queries (e.g., global search) require fan-out—sending requests to all shards. Notion avoids this with Elasticsearch for search. Zero-Downtime Migration: The Double-Write Dance Migrating 20B+ blocks live? Notion’s 3-step playbook: Double Writes: def save_block(block): old_db.write(block) # Legacy database new_sharded_db.write(block) # New shard Audit Logs: A Kafka stream recorded all changes for reconciliation. The Big Cutover: 5-minute downtime to flip the switch. Dark reads compared old/new DB outputs silently. Underrated Hack: They used PostgreSQL’s logical replication to sync shards—no third-party tools needed. Beyond Postgres: The Data Lake Pivot Postgres is great for OLTP (transactions), but analytics? Not so much. Notion’s new pipeline: graph LR A[Postgres Shards] -->|CDC| B[Apache Kafka] B --> C[Apache Spark] C --> D[Amazon S3 Data Lake] D --> E[Snowflake for Analytics] Why? Cost: Snowflake charges per query; S3 is dirt-cheap storage. AI Ready: Unstructured data (e.g., page content) fuels Notion’s AI features. Gotcha: Snowflake hates updates. Notion’s update-heavy workload forced them to build custom tooling. Open Source Gems in Notion’s Stack Apache Kafka: Handles 4M+ messages/sec during peak loads. pgbouncer: Connection pooling to avoid Postgres meltdowns. Apache Hudi: Manages change-data-capture (CDC) for the data lake. Lesson: Notion’s engineers prefer boring tech—Postgres over MongoDB, Kafka over proprietary queues. The Future: What’s Next for Notion’s Stack? Edge Caching: Reduce latency for global users. Columnar Storage: For faster analytics (e.g., Apache Parquet). Vector Databases: To power AI features (semantic search, etc.). Why This Matters for You Even if you’re not building the next Notion, these principles apply: Sharding: Plan it early. Use a clear key (like workspace_id). Data Lakes: Separate OLTP and analytics early. Open Source: Avoid vendor lock-in; Kafka/Postgres will outlive any SaaS. Found this interesting ? To follow me - MY Github, Twitter
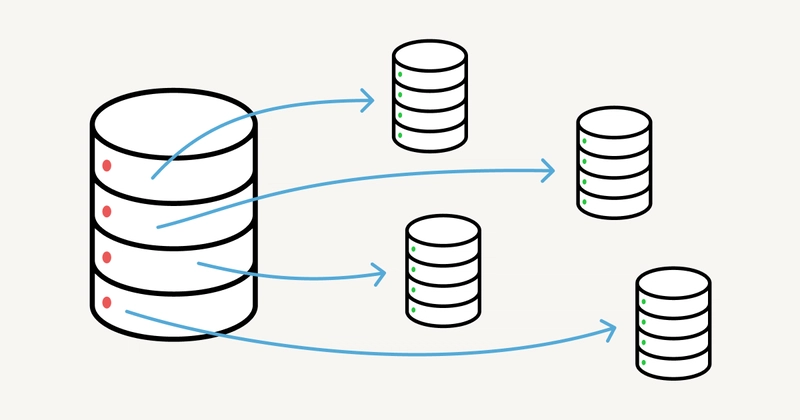
Notion isn’t just a note-taking app—it’s a real-time, collaborative database masquerading as a minimalist UI. But how does it handle 200+ billion blocks (database entries) without buckling under pressure?
Let’s peel back the layers.
Notion’s Data Model: A Database in Disguise
Every action in Notion—typing text, toggling a checkbox—creates a block, stored as a row in PostgreSQL. Here’s the schema of a block:
CREATE TABLE blocks (
id UUID PRIMARY KEY,
type VARCHAR(50), -- 'paragraph', 'checkbox', etc.
parent_id UUID, -- Parent block (if nested)
workspace_id UUID, -- Critical for sharding
properties JSONB -- Flexible content storage
);
Fun Fact:
When you hit ↑ or ↓ in Notion, it’s not moving a cursor—it’s jumping between database rows. A "simple" page with 10 elements = 10+ database queries!
The Scaling Crisis: 20 Billion Blocks and Chaos
Why Postgres Almost Died
- Single database: Pre-2021, all blocks lived in one PostgreSQL instance.
- Indexes bloated: Querying a workspace’s blocks required scanning millions of rows.
- Writes stalled: Concurrent edits from 100M users? Good luck.
The Sharding Savior
Notion split data into 480 logical shards (32 machines × 15 shards each).
How?
-
Shard Key:
workspace_id(every block belongs to one workspace). - Routing: Application code directs queries like:
shard = hash(workspace_id) % 480 # Simple but effective
Pro Tip:
Sharding isn’t free. Cross-shard queries (e.g., global search) require fan-out—sending requests to all shards. Notion avoids this with Elasticsearch for search.
Zero-Downtime Migration: The Double-Write Dance
Migrating 20B+ blocks live? Notion’s 3-step playbook:
- Double Writes:
def save_block(block):
old_db.write(block) # Legacy database
new_sharded_db.write(block) # New shard
- Audit Logs: A Kafka stream recorded all changes for reconciliation.
-
The Big Cutover:
- 5-minute downtime to flip the switch.
- Dark reads compared old/new DB outputs silently.
Underrated Hack:
They used PostgreSQL’s logical replication to sync shards—no third-party tools needed.
Beyond Postgres: The Data Lake Pivot
Postgres is great for OLTP (transactions), but analytics? Not so much. Notion’s new pipeline:
graph LR
A[Postgres Shards] -->|CDC| B[Apache Kafka]
B --> C[Apache Spark]
C --> D[Amazon S3 Data Lake]
D --> E[Snowflake for Analytics]
Why?
- Cost: Snowflake charges per query; S3 is dirt-cheap storage.
- AI Ready: Unstructured data (e.g., page content) fuels Notion’s AI features.
Gotcha:
Snowflake hates updates. Notion’s update-heavy workload forced them to build custom tooling.
Open Source Gems in Notion’s Stack
- Apache Kafka: Handles 4M+ messages/sec during peak loads.
- pgbouncer: Connection pooling to avoid Postgres meltdowns.
- Apache Hudi: Manages change-data-capture (CDC) for the data lake.
Lesson:
Notion’s engineers prefer boring tech—Postgres over MongoDB, Kafka over proprietary queues.
The Future: What’s Next for Notion’s Stack?
- Edge Caching: Reduce latency for global users.
- Columnar Storage: For faster analytics (e.g., Apache Parquet).
- Vector Databases: To power AI features (semantic search, etc.).
Why This Matters for You
Even if you’re not building the next Notion, these principles apply:
-
Sharding: Plan it early. Use a clear key (like
workspace_id). - Data Lakes: Separate OLTP and analytics early.
- Open Source: Avoid vendor lock-in; Kafka/Postgres will outlive any SaaS.