





























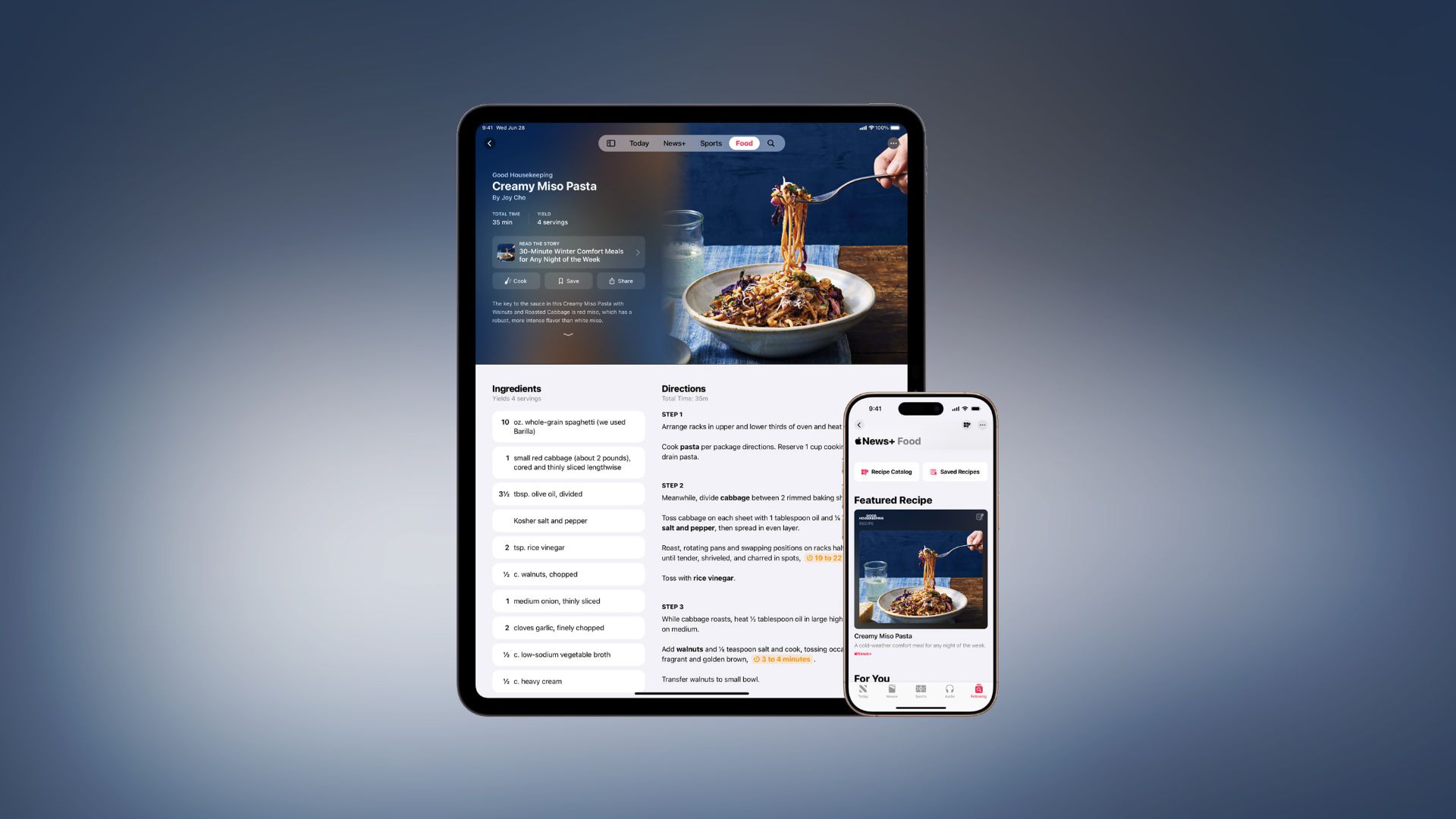































![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)












![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


![Oppo ditches Alert Slider in teaser for smaller Find X8s, five-camera Find X8 Ultra [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/oppo-find-x8s-ultra-teaser-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










-xl-xl.jpg)





















































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)
















































































































![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)






























-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





















































How OpenAI’s o3, Grok 3, DeepSeek R1, Gemini 2.0, and Claude 3.7 Differ in Their Reasoning Approaches
Large language models (LLMs) are rapidly evolving from simple text prediction systems into advanced reasoning engines capable of tackling complex challenges. Initially designed to predict the next word in a sentence, these models have now advanced to solving mathematical equations, writing functional code, and making data-driven decisions. The development of reasoning techniques is the key […] The post How OpenAI’s o3, Grok 3, DeepSeek R1, Gemini 2.0, and Claude 3.7 Differ in Their Reasoning Approaches appeared first on Unite.AI.


Large language models (LLMs) are rapidly evolving from simple text prediction systems into advanced reasoning engines capable of tackling complex challenges. Initially designed to predict the next word in a sentence, these models have now advanced to solving mathematical equations, writing functional code, and making data-driven decisions. The development of reasoning techniques is the key driver behind this transformation, allowing AI models to process information in a structured and logical manner. This article explores the reasoning techniques behind models like OpenAI's o3, Grok 3, DeepSeek R1, Google's Gemini 2.0, and Claude 3.7 Sonnet, highlighting their strengths and comparing their performance, cost, and scalability.
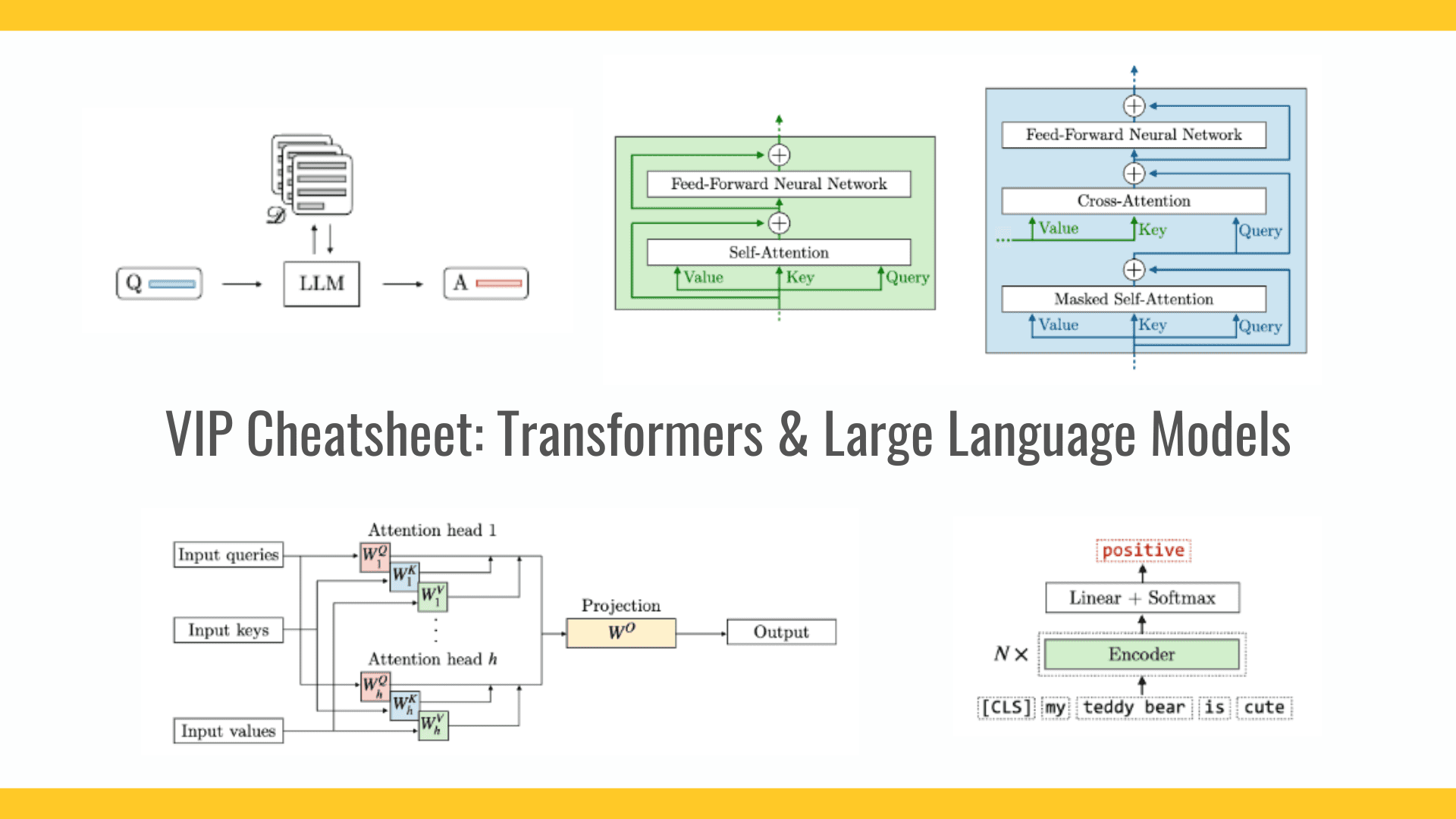
Reasoning Techniques in Large Language Models
To see how these LLMs reason differently, we first need to look at different reasoning techniques these models are using. In this section, we present four key reasoning techniques.
- Inference-Time Compute Scaling
This technique improves model’s reasoning by allocating extra computational resources during the response generation phase, without altering the model’s core structure or retraining it. It allows the model to “think harder” by generating multiple potential answers, evaluating them, or refining its output through additional steps. For example, when solving a complex math problem, the model might break it down into smaller parts and work through each one sequentially. This approach is particularly useful for tasks that require deep, deliberate thought, such as logical puzzles or intricate coding challenges. While it improves the accuracy of responses, this technique also leads to higher runtime costs and slower response times, making it suitable for applications where precision is more important than speed. - Pure Reinforcement Learning (RL)
In this technique, the model is trained to reason through trial and error by rewarding correct answers and penalizing mistakes. The model interacts with an environment—such as a set of problems or tasks—and learns by adjusting its strategies based on feedback. For instance, when tasked with writing code, the model might test various solutions, earning a reward if the code executes successfully. This approach mimics how a person learns a game through practice, enabling the model to adapt to new challenges over time. However, pure RL can be computationally demanding and sometimes unstable, as the model may find shortcuts that don’t reflect true understanding. - Pure Supervised Fine-Tuning (SFT)
This method enhances reasoning by training the model solely on high-quality labeled datasets, often created by humans or stronger models. The model learns to replicate correct reasoning patterns from these examples, making it efficient and stable. For instance, to improve its ability to solve equations, the model might study a collection of solved problems, learning to follow the same steps. This approach is straightforward and cost-effective but relies heavily on the quality of the data. If the examples are weak or limited, the model’s performance may suffer, and it could struggle with tasks outside its training scope. Pure SFT is best suited for well-defined problems where clear, reliable examples are available. - Reinforcement Learning with Supervised Fine-Tuning (RL+SFT)
The approach combines the stability of supervised fine-tuning with the adaptability of reinforcement learning. Models first undergo supervised training on labeled datasets, which provides a solid knowledge foundation. Subsequently, reinforcement learning helps refine the model's problem-solving skills. This hybrid method balances stability and adaptability, offering effective solutions for complex tasks while reducing the risk of erratic behavior. However, it requires more resources than pure supervised fine-tuning.
Reasoning Approaches in Leading LLMs
Now, let's examine how these reasoning techniques are applied in the leading LLMs including OpenAI's o3, Grok 3, DeepSeek R1, Google's Gemini 2.0, and Claude 3.7 Sonnet.
- OpenAI's o3
OpenAI's o3 primarily uses Inference-Time Compute Scaling to enhance its reasoning. By dedicating extra computational resources during response generation, o3 is able to deliver highly accurate results on complex tasks like advanced mathematics and coding. This approach allows o3 to perform exceptionally well on benchmarks like the ARC-AGI test. However, it comes at the cost of higher inference costs and slower response times, making it best suited for applications where precision is crucial, such as research or technical problem-solving. - xAI's Grok 3
Grok 3, developed by xAI, combines Inference-Time Compute Scaling with specialized hardware, such as co-processors for tasks like symbolic mathematical manipulation. This unique architecture allows Grok 3 to process large amounts of data quickly and accurately, making it highly effective for real-time applications like financial analysis and live data processing. While Grok 3 offers rapid performance, its high computational demands can drive up costs. It excels in environments where speed and accuracy are paramount. - DeepSeek R1
DeepSeek R1 initially uses Pure Reinforcement Learning to train its model, allowing it to develop independent problem-solving strategies through trial and error. This makes DeepSeek R1 adaptable and capable of handling unfamiliar tasks, such as complex math or coding challenges. However, Pure RL can lead to unpredictable outputs, so DeepSeek R1 incorporates Supervised Fine-Tuning in later stages to improve consistency and coherence. This hybrid approach makes DeepSeek R1 a cost-effective choice for applications that prioritize flexibility over polished responses. - Google's Gemini 2.0
Google's Gemini 2.0 uses a hybrid approach, likely combining Inference-Time Compute Scaling with Reinforcement Learning, to enhance its reasoning capabilities. This model is designed to handle multimodal inputs, such as text, images, and audio, while excelling in real-time reasoning tasks. Its ability to process information before responding ensures high accuracy, particularly in complex queries. However, like other models using inference-time scaling, Gemini 2.0 can be costly to operate. It is ideal for applications that require reasoning and multimodal understanding, such as interactive assistants or data analysis tools. - Anthropic's Claude 3.7 Sonnet
Claude 3.7 Sonnet from Anthropic integrates Inference-Time Compute Scaling with a focus on safety and alignment. This enables the model to perform well in tasks that require both accuracy and explainability, such as financial analysis or legal document review. Its “extended thinking” mode allows it to adjust its reasoning efforts, making it versatile for both quick and in-depth problem-solving. While it offers flexibility, users must manage the trade-off between response time and depth of reasoning. Claude 3.7 Sonnet is especially suited for regulated industries where transparency and reliability are crucial.
The Bottom Line
The shift from basic language models to sophisticated reasoning systems represents a major leap forward in AI technology. By leveraging techniques like Inference-Time Compute Scaling, Pure Reinforcement Learning, RL+SFT, and Pure SFT, models such as OpenAI’s o3, Grok 3, DeepSeek R1, Google’s Gemini 2.0, and Claude 3.7 Sonnet have become more adept at solving complex, real-world problems. Each model’s approach to reasoning defines its strengths, from o3’s deliberate problem-solving to DeepSeek R1’s cost-effective flexibility. As these models continue to evolve, they will unlock new possibilities for AI, making it an even more powerful tool for addressing real-world challenges.
The post How OpenAI’s o3, Grok 3, DeepSeek R1, Gemini 2.0, and Claude 3.7 Differ in Their Reasoning Approaches appeared first on Unite.AI.







