
































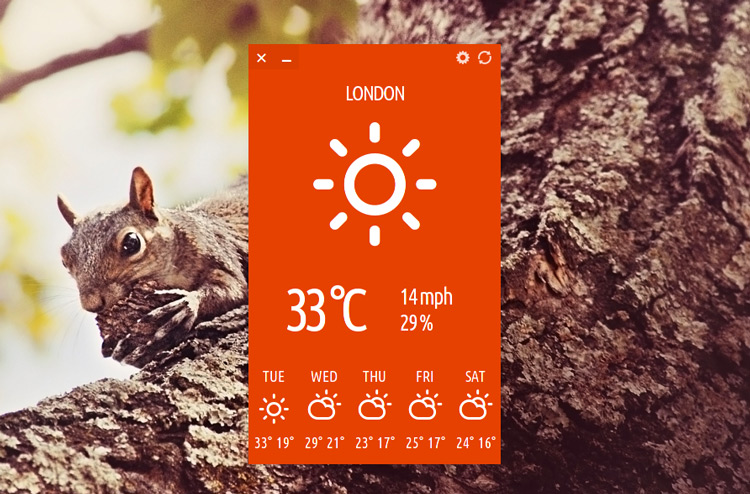



























![Nomad Goods Launches 15% Sitewide Sale for 48 Hours Only [Deal]](https://www.iclarified.com/images/news/96899/96899/96899-640.jpg)


![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)

















![watchOS 11.4 now available with three new features for Apple Watch [U: Back]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/01/watchOS-11.4-hero.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



























































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

















































































































![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)


















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)

































-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















































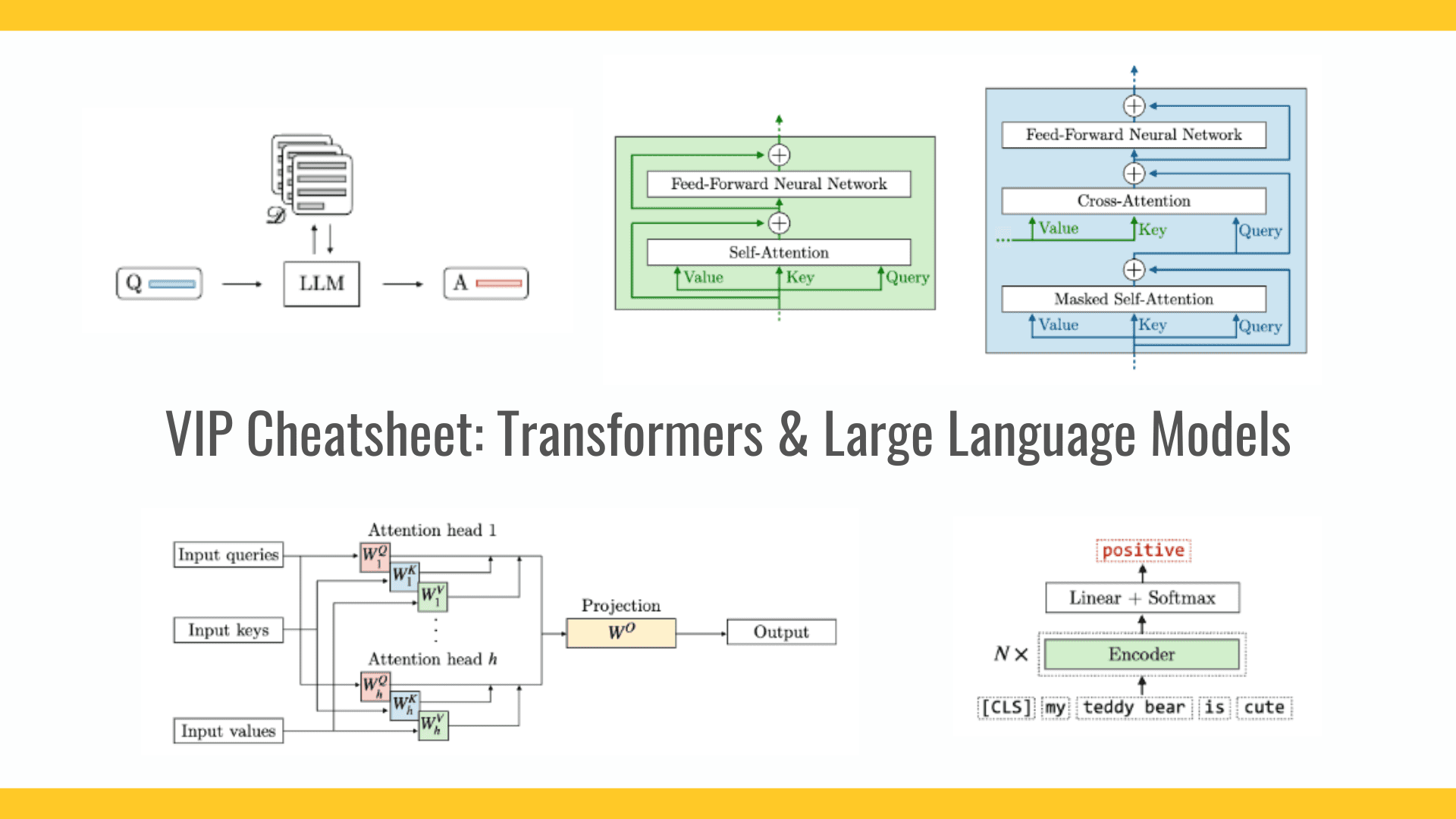
VideoMind: A Role-Based Agent for Temporal-Grounded Video Understanding
LLMs have shown impressive capabilities in reasoning tasks like Chain-of-Thought (CoT), enhancing accuracy and interpretability in complex problem-solving. While researchers are extending these capabilities to multi-modal domains, videos present unique challenges due to their temporal dimension. Unlike static images, videos require understanding dynamic interactions over time. Current visual CoT methods excel with static inputs but […] The post VideoMind: A Role-Based Agent for Temporal-Grounded Video Understanding appeared first on MarkTechPost.

LLMs have shown impressive capabilities in reasoning tasks like Chain-of-Thought (CoT), enhancing accuracy and interpretability in complex problem-solving. While researchers are extending these capabilities to multi-modal domains, videos present unique challenges due to their temporal dimension. Unlike static images, videos require understanding dynamic interactions over time. Current visual CoT methods excel with static inputs but struggle with video content because they cannot explicitly localize or revisit specific moments in sequences. Humans overcome these challenges by breaking down complex problems, identifying and revisiting key moments, and synthesizing observations into coherent answers. This approach highlights the need for AI systems to manage multiple reasoning abilities.
Recent video understanding advances have improved tasks like captioning and question answering, but models often lack visual-grounded correspondence and interpretability, especially for long-form videos. Video Temporal Grounding addresses this by requiring precise localization. Large Multimodal Models trained with supervised instruction-tuning struggle with complex reasoning tasks. Two major approaches have emerged to address these limitations: agent-based interfaces and pure text-based reasoning paradigms exemplified by CoT processes. Moreover, Inference-time searching techniques are valuable in domains like robotics, games, and navigation by allowing models to iteratively refine outputs without changing underlying weights.
Researchers from the Hong Kong Polytechnic University and Show Lab, National University of Singapore, have proposed VideoMind, a video-language agent designed for temporal-grounded video understanding. VideoMind introduces two key innovations to address the challenges of video reasoning. First, it identifies essential capabilities for video temporal reasoning and implements a role-based agentic workflow with specialized components: a planner, a grounder, a verifier, and an answerer. Second, it proposes a Chain-of-LoRA strategy that enables seamless role-switching through lightweight LoRA adaptors, avoiding the overhead of multiple models while balancing efficiency and flexibility. Experiments across 14 public benchmarks show state-of-the-art performance in diverse video understanding tasks.

VideoMind builds upon the Qwen2-VL, combining an LLM backbone with a ViT-based visual encoder capable of handling dynamic resolution inputs. Its core innovation is its Chain-of-LoRA strategy, which dynamically activates role-specific LoRA adapters during inference via self-calling. Moreover, it contains four specialized components: (a) Planner, which coordinates all other roles and determines which function to call next based on query, (b) Grounder, which localizes relevant moments by identifying start and end timestamps based on text queries (c) Verifier, which provides binary (“Yes”/”No”) responses to validate temporal intervals and (d) Answerer, which generates responses based on either cropped video segments identified by the Grounder or the entire video when direct answering is more appropriate.
In grounding metrics, VideoMind’s lightweight 2B model outperforms most compared models, including InternVL2-78B and Claude-3.5-Sonnet, with only GPT-4o showing superior results. However, the 7B version of VideoMind surpasses even GPT-4o, achieving competitive overall performance. On the NExT-GQA benchmark, the 2B model matches state-of-the-art 7B models across both agent-based and end-to-end approaches, comparing favorably with text-rich, agent-based solutions like LLoVi, LangRepo, and SeViLA. VideoMind shows exceptional zero-shot capabilities, outperforming all LLM-based temporal grounding methods and achieving competitive results compared to fine-tuned temporal grounding experts. Moreover, VideoMind excels in general video QA tasks across Video-MME (Long), MLVU, and LVBench, showing effective localization of cue segments before answering questions.
In this paper, researchers introduced VideoMind, a significant advancement in temporal grounded video reasoning. It addresses the complex challenges of video understanding through agentic workflow, combining a Planner, Grounder, Verifier, Answerer, and an efficient Chain-of-LoRA strategy for role-switching. Experiments across three key domains, grounded video question-answering, video temporal grounding, and general video question-answering, confirm VideoMind’s effectiveness for long-form video reasoning tasks where it provides precise, evidence-based answers. This work establishes a foundation for future developments in multimodal video agents and reasoning capabilities, opening new pathways for more complex video understanding systems.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post VideoMind: A Role-Based Agent for Temporal-Grounded Video Understanding appeared first on MarkTechPost.







