











































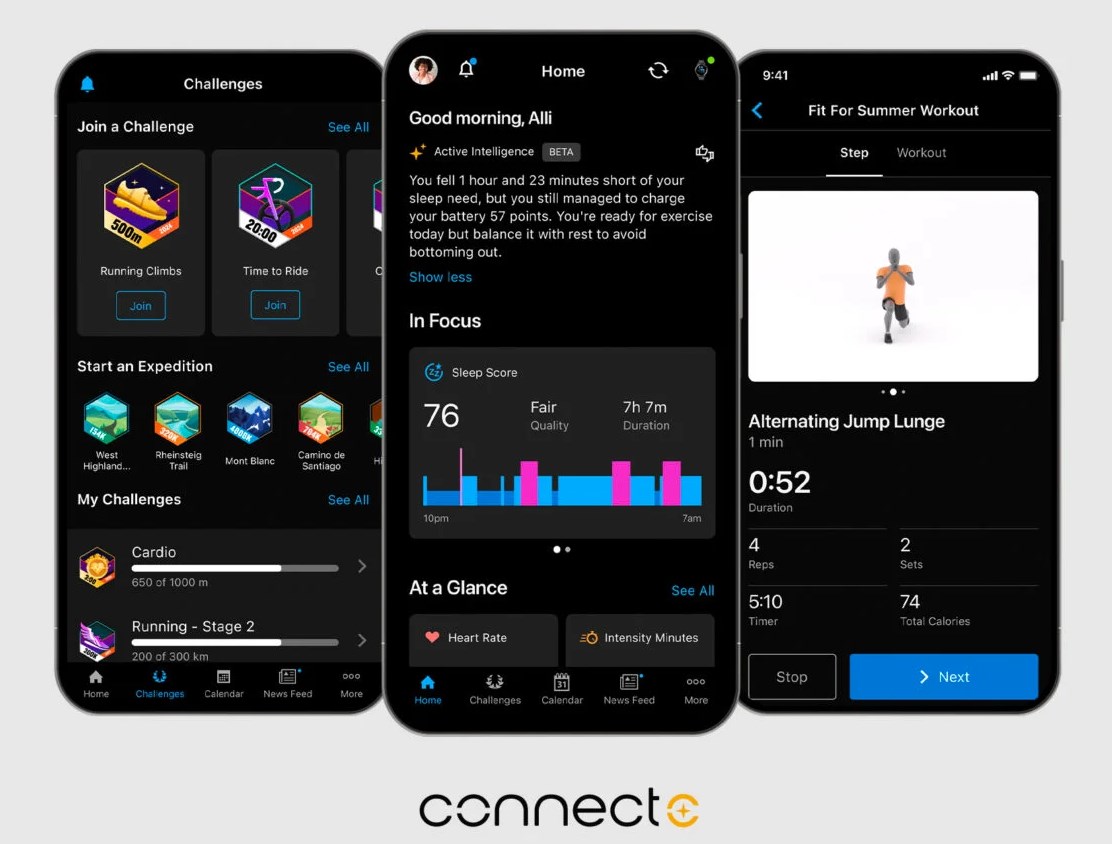
















![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)











![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














-xl-xl.jpg)



















































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)
















































































































![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)




























-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





















































This AI Paper Propose the UI-R1 Framework that Extends Rule-based Reinforcement Learning to GUI Action Prediction Tasks
Supervised fine-tuning (SFT) is the standard training paradigm for large language models (LLMs) and graphic user interface (GUI) agents. However, SFT demands high-quality labeled datasets, resulting in extended training periods and high computational expenses. This dependence on extensive data creates bottlenecks in AI development workflows. Moreover, existing VLM-based GUI agents trained through SFT show performance […] The post This AI Paper Propose the UI-R1 Framework that Extends Rule-based Reinforcement Learning to GUI Action Prediction Tasks appeared first on MarkTechPost.

Supervised fine-tuning (SFT) is the standard training paradigm for large language models (LLMs) and graphic user interface (GUI) agents. However, SFT demands high-quality labeled datasets, resulting in extended training periods and high computational expenses. This dependence on extensive data creates bottlenecks in AI development workflows. Moreover, existing VLM-based GUI agents trained through SFT show performance deficiencies when confronted with out-of-domain scenarios, severely limiting their practical utility in diverse real-world applications. Rule-based reinforcement learning (RL) or reinforcement fine-tuning (RFT) is a promising alternative, requiring only dozens to thousands of samples instead of massive datasets.
Various approaches have been developed to advance GUI agents and optimize their training. The AppAgent and Mobile-Agent series integrate commercial models like GPT for planning and prediction tasks but heavily depend on prompt engineering and multi-agent collaboration, requiring careful manual design for optimal performance. So, researchers have fine-tuned smaller open-source MLLMs on task-specific GUI datasets to create specialist agents. Rule-based RL has become an efficient alternative to traditional training paradigms and utilizes predefined rule-based reward functions that focus on final results while allowing models to learn reasoning processes organically. The technique proves effective even on smaller models and is extended to multimodal models through task-specific rewards for visual tasks.
Researchers from vivo AI Lab and MMLab @ CUHK have proposed UI-R1 to enhance multimodal LLMs’ reasoning capabilities for GUI action prediction tasks through DeepSeek R1 style RL. Researchers present the first exploration of how rule-based RL can improve MLLM reasoning for graphic UI action prediction. A small yet high-quality dataset is curated with 136 challenging tasks across five common mobile device action types. Model optimization is enabled through policy-based algorithms by introducing a unified rule-based action reward, specifically Group Relative Policy Optimization (GRPO). This approach has shown great effectiveness for in-domain and out-of-domain tasks, with significant improvements in action type accuracy and grounding accuracy compared to the base Qwen2.5-VL-3B model.

The system’s grounding capabilities are evaluated using two specialized benchmarks: ScreenSpot, which evaluates GUI grounding across mobile, desktop, and web platforms, and ScreenSpot-Pro, which focuses on high-resolution professional environments with expert-annotated tasks spanning 23 applications, five industries, and three operating systems. Moreover, the model undergoes testing for single-step action prediction based on low-level instructions using a selected subset of ANDROIDCONTROL, which introduces a broader range of action types beyond the ScreenSpot benchmark. The research methodology also explores the critical relationship between training data size and model performance, comparing random sampling versus difficulty-based selection in training data selection.
The UI-R1 improves the GUI grounding capability of the 3B model by 20% on ScreenSpot and 6% on ScreenSpot-Pro, outperforming most 7B models on both benchmarks. UI-R1 achieves performance comparable to state-of-the-art 7B models such as AGUVIS and OS-Atlas, despite those models being trained using SFT on larger labeled datasets. When compared directly with the Qwen2.5-VL (ZS) model, UI-R1 shows a 15% improvement in action type prediction accuracy and a 20% enhancement in click element grounding accuracy using only 136 training data points. The research also reveals that while model performance improves with increased training data, this relationship gradually saturates, and the difficulty-based selection method consistently outperforms random selection.
In conclusion, researchers introduced the UI-R1 framework, which successfully extends rule-based RL to GUI action prediction tasks, providing a scalable and efficient alternative to traditional SFT. It uses a novel reward function that simultaneously evaluates both action type and arguments, effectively reducing task complexity while enhancing learning efficiency. Despite utilizing only 130+ training samples from the mobile domain, UI-R1 achieves remarkable performance, showing strong generalization capabilities when applied to out-of-domain datasets across desktop and web platforms. UI-R1’s exceptional adaptability, data efficiency, and effectiveness in handling specialized tasks establish a promising future direction in developing multimodal GUI agents.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post This AI Paper Propose the UI-R1 Framework that Extends Rule-based Reinforcement Learning to GUI Action Prediction Tasks appeared first on MarkTechPost.







