






























![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)












![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)


![Oppo ditches Alert Slider in teaser for smaller Find X8s, five-camera Find X8 Ultra [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/03/oppo-find-x8s-ultra-teaser-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










-xl-xl.jpg)





















































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)
















































































































![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)
















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)






























-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





























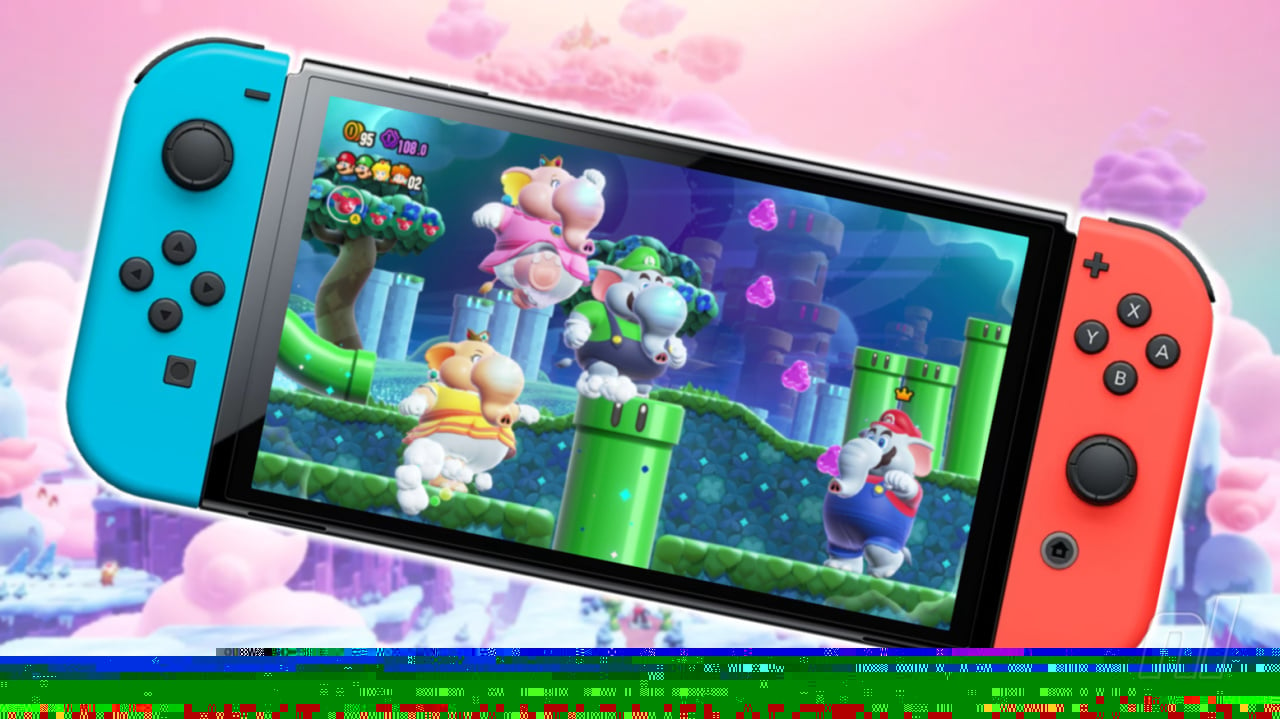
























High-Performance Secure Networking with RIOC
In distributed systems, network communication often becomes the bottleneck that limits overall application performance. We've seen this firsthand while building HPKV, our high-performance key-value store. This article explores how we approached networking challenges in RIOC (Remote I/O Control), the networking layer that powers HPKV's distributed capabilities. What is RIOC? RIOC is a client-server protocol implementation designed specifically for interfacing with high-performance storage systems like HPKV. What sets it apart isn't just raw performance, but how it balances three critical requirements: Latency and Throughput: Zero-copy operations, vectored I/O, and batch processing Data Consistency: Atomic operations with proper memory barriers Transport Security: TLS 1.3 with mutual authentication (mTLS) The Architecture At its core, RIOC consists of client and server components communicating over a binary protocol. The high-level architecture looks like this: Performance Optimizations Network performance is often overlooked, but it's a critical component in any distributed system. RIOC implements several key optimizations that work together to achieve exceptional performance. Vectored I/O: Reducing System Call Overhead Traditional network programs use sequential send/recv calls to transmit data. For operations involving multiple data segments (headers, keys, values), this can lead to multiple system calls and context switches. Vectored I/O is a powerful technique that allows a single system call to send or receive multiple discontinuous data buffers. RIOC uses the writev and readv system calls to simultaneously transmit multiple memory segments without having to copy them into a contiguous buffer first. Here's how it works in RIOC: // Example from RIOC implementation struct iovec iovs[4]; // batch_header + op_header + key + value int iov_count = 0; // Setup batch header iovs[iov_count].iov_base = &batch_header; iovs[iov_count].iov_len = sizeof(batch_header); iov_count++; // Setup op header iovs[iov_count].iov_base = &op_header; iovs[iov_count].iov_len = sizeof(op_header); iov_count++; // Setup key iovs[iov_count].iov_base = (void*)key; iovs[iov_count].iov_len = key_len; iov_count++; // Setup value if present if (value && value_len > 0) { iovs[iov_count].iov_base = (void*)value; iovs[iov_count].iov_len = value_len; iov_count++; } // Send all segments in a single system call writev(socket, iovs, iov_count); The benefits of this approach are significant: Reduced System Call Overhead: A single call to writev replaces multiple calls to send No Extra Memory Copies: Data is sent directly from its original locations Fewer Context Switches: Minimizing transitions between user space and system space Improved Packet Efficiency: The TCP/IP stack can optimize packet boundaries RIOC's implementation also includes size-based optimizations: For transfers under 4KB, it uses a stack-allocated buffer to minimize heap allocations For larger transfers, it dynamically adjusts to use vectored I/O with prefetching hints Zero-Copy Data Transfers A natural extension of vectored I/O is the concept of zero-copy data transfers. Traditional network programming often involves multiple data copies: From application buffer to socket buffer From socket buffer to network interface From network interface to socket buffer on the receiving side From socket buffer to application buffer on the receiving side RIOC minimizes these copies in several ways: // Example of zero-copy receive for large values ssize_t rioc_zero_copy_recv(int fd, struct rioc_value *value) { // Allocate memory once, to be used directly by application if (!value->data) { value->data = aligned_alloc(RIOC_CACHE_LINE_SIZE, value->size); if (!value->data) return -1; } // Read directly into application memory return recv_all(fd, value->data, value->size); } For operations where the client will be accessing the data immediately, RIOC can also leverage techniques like: Memory mapping: For very large values, memory-mapped I/O can be used to avoid buffer copying Scatter-gather DMA: When supported by the hardware, RIOC can work with the network stack to use DMA operations Buffer ownership transfer: Using smart pointers or reference counting to transfer buffer ownership instead of copying content While zero-copy is powerful, it's not always the most efficient approach for small data sizes due to the overhead of memory management and registration. RIOC dynamically selects the appropriate strategy based on operation size and access patterns. Socket Tuning: Beyond Default Parameters TCP's default settings are designed for general-purpose internet communication, prioritizing compatibility and reliability over raw performance. For high-performance local or data center networking, these defaults can be limiting. RIOC
In distributed systems, network communication often becomes the bottleneck that limits overall application performance. We've seen this firsthand while building HPKV, our high-performance key-value store. This article explores how we approached networking challenges in RIOC (Remote I/O Control), the networking layer that powers HPKV's distributed capabilities.
What is RIOC?
RIOC is a client-server protocol implementation designed specifically for interfacing with high-performance storage systems like HPKV. What sets it apart isn't just raw performance, but how it balances three critical requirements:
- Latency and Throughput: Zero-copy operations, vectored I/O, and batch processing
- Data Consistency: Atomic operations with proper memory barriers
- Transport Security: TLS 1.3 with mutual authentication (mTLS)
The Architecture
At its core, RIOC consists of client and server components communicating over a binary protocol. The high-level architecture looks like this:
Performance Optimizations
Network performance is often overlooked, but it's a critical component in any distributed system. RIOC implements several key optimizations that work together to achieve exceptional performance.
Vectored I/O: Reducing System Call Overhead
Traditional network programs use sequential send/recv calls to transmit data. For operations involving multiple data segments (headers, keys, values), this can lead to multiple system calls and context switches.
Vectored I/O is a powerful technique that allows a single system call to send or receive multiple discontinuous data buffers. RIOC uses the writev and readv system calls to simultaneously transmit multiple memory segments without having to copy them into a contiguous buffer first.
Here's how it works in RIOC:
// Example from RIOC implementation
struct iovec iovs[4]; // batch_header + op_header + key + value
int iov_count = 0;
// Setup batch header
iovs[iov_count].iov_base = &batch_header;
iovs[iov_count].iov_len = sizeof(batch_header);
iov_count++;
// Setup op header
iovs[iov_count].iov_base = &op_header;
iovs[iov_count].iov_len = sizeof(op_header);
iov_count++;
// Setup key
iovs[iov_count].iov_base = (void*)key;
iovs[iov_count].iov_len = key_len;
iov_count++;
// Setup value if present
if (value && value_len > 0) {
iovs[iov_count].iov_base = (void*)value;
iovs[iov_count].iov_len = value_len;
iov_count++;
}
// Send all segments in a single system call
writev(socket, iovs, iov_count);
The benefits of this approach are significant:
-
Reduced System Call Overhead: A single call to
writevreplaces multiple calls tosend - No Extra Memory Copies: Data is sent directly from its original locations
- Fewer Context Switches: Minimizing transitions between user space and system space
- Improved Packet Efficiency: The TCP/IP stack can optimize packet boundaries
RIOC's implementation also includes size-based optimizations:
- For transfers under 4KB, it uses a stack-allocated buffer to minimize heap allocations
- For larger transfers, it dynamically adjusts to use vectored I/O with prefetching hints
Zero-Copy Data Transfers
A natural extension of vectored I/O is the concept of zero-copy data transfers. Traditional network programming often involves multiple data copies:
- From application buffer to socket buffer
- From socket buffer to network interface
- From network interface to socket buffer on the receiving side
- From socket buffer to application buffer on the receiving side
RIOC minimizes these copies in several ways:
// Example of zero-copy receive for large values
ssize_t rioc_zero_copy_recv(int fd, struct rioc_value *value) {
// Allocate memory once, to be used directly by application
if (!value->data) {
value->data = aligned_alloc(RIOC_CACHE_LINE_SIZE, value->size);
if (!value->data) return -1;
}
// Read directly into application memory
return recv_all(fd, value->data, value->size);
}
For operations where the client will be accessing the data immediately, RIOC can also leverage techniques like:
- Memory mapping: For very large values, memory-mapped I/O can be used to avoid buffer copying
- Scatter-gather DMA: When supported by the hardware, RIOC can work with the network stack to use DMA operations
- Buffer ownership transfer: Using smart pointers or reference counting to transfer buffer ownership instead of copying content
While zero-copy is powerful, it's not always the most efficient approach for small data sizes due to the overhead of memory management and registration. RIOC dynamically selects the appropriate strategy based on operation size and access patterns.
Socket Tuning: Beyond Default Parameters
TCP's default settings are designed for general-purpose internet communication, prioritizing compatibility and reliability over raw performance. For high-performance local or data center networking, these defaults can be limiting.
RIOC applies careful socket tuning to maximize throughput and minimize latency:
// TCP_NODELAY: Disable Nagle's algorithm
int flag = 1;
setsockopt(socket, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof(flag));
// Increase socket buffers to 1MB
int buffer_size = 1024 * 1024; // 1MB
setsockopt(socket, SOL_SOCKET, SO_RCVBUF, &buffer_size, sizeof(buffer_size));
setsockopt(socket, SOL_SOCKET, SO_SNDBUF, &buffer_size, sizeof(buffer_size));
// Set low-latency type-of-service
int tos = IPTOS_LOWDELAY;
setsockopt(socket, IPPROTO_IP, IP_TOS, &tos, sizeof(tos));
// Enable TCP Quick ACK on Linux
#ifdef TCP_QUICKACK
setsockopt(socket, IPPROTO_TCP, TCP_QUICKACK, &flag, sizeof(flag));
#endif
Let's examine why each option matters:
TCP_NODELAY: Disables Nagle's algorithm, which otherwise would buffer small packets to reduce header overhead. While this can improve efficiency for some workloads, it introduces latency by delaying transmission until either a full packet can be sent or a timeout occurs. For RIOC's low-latency requirements, disabling this is crucial.
Socket Buffer Sizing: Default socket buffers (often ~128KB) can limit throughput, especially on high-bandwidth networks. By increasing to 1MB, RIOC ensures the TCP window can scale appropriately, keeping the network pipe full.
IPTOS_LOWDELAY: This sets the Type of Service (ToS) field in IP packets to request low-latency handling from network equipment. While not all network devices honor this, those that do will prioritize these packets over bulk transfers.
TCP_QUICKACK: On Linux, this disables delayed ACKs, ensuring that TCP acknowledgments are sent immediately rather than waiting to piggyback on data packets or timeouts.
TCP_CORK: Strategic Packet Coalescing
For operations that involve sending multiple segments that should logically be processed together, RIOC uses TCP_CORK to control packet boundaries.
Unlike Nagle's algorithm (which TCP_NODELAY disables), TCP_CORK gives the application explicit control over when packets are sent:
// Enable TCP_CORK
int flag = 1;
setsockopt(socket, IPPROTO_TCP, TCP_CORK, &flag, sizeof(flag));
// Send multiple segments...
send(socket, header, header_size, 0);
send(socket, key, key_size, 0);
send(socket, value, value_size, 0);
// Disable TCP_CORK to flush any remaining data
flag = 0;
setsockopt(socket, IPPROTO_TCP, TCP_CORK, &flag, sizeof(flag));
This technique has several advantages:
- Reduced Packet Count: Data is coalesced into fewer, larger packets
- Better Utilization: More data per packet means better amortization of TCP/IP header overhead
- Lower Processing Cost: Network equipment processes fewer packets
RIOC applies TCP_CORK selectively based on operation size:
- Small operations (≤4KB) are sent immediately
- Larger operations use TCP_CORK to optimize packet boundaries
- The cork is always explicitly removed when transmission is complete, preventing indefinite delays
Lockless Data Structures
Contention on locks can severely impact performance in multi-threaded systems. In high-performance networking, every microsecond counts, and traditional lock-based synchronization can introduce significant overhead. RIOC employs several lockless techniques to minimize contention:
1. Lock-Free Sequence Numbers
For client request tracking, RIOC uses atomic sequence counters that can be accessed without locks:
// Lockless sequence counter for client requests
struct rioc_client {
// Other fields...
atomic_uint64_t sequence; // Atomic sequence counter
};
// Atomically increment sequence number without locks
uint64_t rioc_get_next_sequence(struct rioc_client *client) {
return atomic_fetch_add_explicit(&client->sequence, 1, memory_order_relaxed);
}
This approach allows multiple threads to generate unique sequence numbers without contention, which is crucial for high-throughput scenarios.
2. Single-Producer, Single-Consumer Queues
For passing data between dedicated threads, RIOC implements true lockless SPSC (Single-Producer, Single-Consumer) queues:
struct spsc_queue {
atomic_size_t head;
atomic_size_t tail;
void *items[QUEUE_SIZE];
} __attribute__((aligned(RIOC_CACHE_LINE_SIZE)));
// Producer: Add item to queue without locks
bool spsc_enqueue(struct spsc_queue *q, void *item) {
size_t tail = atomic_load_explicit(&q->tail, memory_order_relaxed);
size_t next_tail = (tail + 1) % QUEUE_SIZE;
// Check if queue is full
if (next_tail == atomic_load_explicit(&q->head, memory_order_acquire))
return false; // Queue full
// Add item and update tail
q->items[tail] = item;
atomic_store_explicit(&q->tail, next_tail, memory_order_release);
return true;
}
// Consumer: Remove item from queue without locks
void* spsc_dequeue(struct spsc_queue *q) {
size_t head = atomic_load_explicit(&q->head, memory_order_relaxed);
// Check if queue is empty
if (head == atomic_load_explicit(&q->tail, memory_order_acquire))
return NULL; // Queue empty
// Get item and update head
void *item = q->items[head];
atomic_store_explicit(&q->head, (head + 1) % QUEUE_SIZE, memory_order_release);
return item;
}
This implementation uses memory ordering primitives to ensure correctness without locks:
-
memory_order_relaxedfor operations where order doesn't matter -
memory_order_acquireto ensure all subsequent reads see updates -
memory_order_releaseto ensure all prior writes are visible
3. Read-Copy-Update (RCU) for Connection Management
RIOC uses a simplified RCU-like pattern for managing active connections, allowing lookups to proceed without locking while updates happen concurrently:
// Connection table with lockless reads
struct connection_table {
atomic_ptr_t connections[MAX_CONNECTIONS]; // Array of atomic pointers
// Other fields...
};
// Lookup connection without locking
struct connection* find_connection(struct connection_table *table, connection_id_t id) {
if (id >= MAX_CONNECTIONS)
return NULL;
// Atomic read with acquire semantics to ensure we see a complete structure
return atomic_load_explicit(&table->connections[id], memory_order_acquire);
}
// Add new connection (requires synchronization for writers)
void add_connection(struct connection_table *table, connection_id_t id, struct connection *conn) {
// Synchronize writers (omitted for brevity)
// Ensure connection is fully initialized before publishing
atomic_store_explicit(&table->connections[id], conn, memory_order_release);
}
// Remove connection
void remove_connection(struct connection_table *table, connection_id_t id) {
// Synchronize writers (omitted for brevity)
// Set to NULL with release semantics
atomic_store_explicit(&table->connections[id], NULL, memory_order_release);
// The actual connection cleanup is deferred until all readers are done
schedule_deferred_cleanup(find_connection(table, id));
}
This approach allows connection lookups to proceed at full speed without locking, while the less-frequent operations of adding and removing connections can use heavier synchronization.
4. Concurrent Statistics Collection
RIOC maintains various statistics counters that are updated by multiple threads without locking:
struct rioc_stats {
atomic_uint64_t operations_total;
atomic_uint64_t bytes_sent;
atomic_uint64_t bytes_received;
atomic_uint64_t errors;
// More counters...
} __attribute__((aligned(RIOC_CACHE_LINE_SIZE)));
// Increment operation counter from any thread
void count_operation(struct rioc_stats *stats) {
atomic_fetch_add_explicit(&stats->operations_total, 1, memory_order_relaxed);
}
// Add to bytes sent counter
void add_bytes_sent(struct rioc_stats *stats, size_t bytes) {
atomic_fetch_add_explicit(&stats->bytes_sent, bytes, memory_order_relaxed);
}
// Snapshot statistics safely
void snapshot_stats(struct rioc_stats *stats, struct rioc_stats_snapshot *snapshot) {
// Use memory barrier to ensure consistent view
atomic_thread_fence(memory_order_acquire);
snapshot->operations_total = atomic_load_explicit(&stats->operations_total, memory_order_relaxed);
snapshot->bytes_sent = atomic_load_explicit(&stats->bytes_sent, memory_order_relaxed);
snapshot->bytes_received = atomic_load_explicit(&stats->bytes_received, memory_order_relaxed);
snapshot->errors = atomic_load_explicit(&stats->errors, memory_order_relaxed);
// Copy other counters...
}
By using atomic operations with appropriate memory ordering, these counters can be updated at very high frequency without locks, while still providing accurate statistics.
5. Hybrid Approaches for Complex Data Structures
For more complex data structures like the multi-producer, multi-consumer work queue, RIOC uses a hybrid approach combining atomic operations with minimal locking:
// Ring buffer with atomic head/tail pointers
size_t head = atomic_load_explicit(&queue->head, memory_order_acquire);
size_t tail = atomic_load_explicit(&queue->tail, memory_order_acquire);
// Check if empty without locking
if (head == tail) {
// Empty queue handling
}
// Only lock for modifications, not for simple checks
if (need_to_modify) {
pthread_mutex_lock(&queue->mutex);
// Double-check conditions after acquiring lock (avoid TOCTOU)
head = atomic_load_explicit(&queue->head, memory_order_relaxed);
tail = atomic_load_explicit(&queue->tail, memory_order_relaxed);
if (still_need_to_modify) {
// Modify queue state
}
pthread_mutex_unlock(&queue->mutex);
}
Although not completely lockless, this approach minimizes the duration of critical sections and avoids locking altogether for read-only operations, significantly reducing contention.
Choosing the Right Approach
RIOC's approach to concurrency balances correctness, performance, and code complexity:
- Fully Lockless Algorithms: Used for simple patterns with clear ownership (sequence numbers, SPSC queues, statistics)
- RCU-like Patterns: Used for read-heavy data structures where readers should never block
- Fine-grained Locking: Used where truly lockless algorithms would be too complex or error-prone
- Atomic Operations: Used throughout to ensure proper memory ordering and visibility
While fully lockless algorithms can provide the highest theoretical performance, they often come with increased complexity and subtle correctness issues. RIOC pragmatically chooses the appropriate synchronization mechanism based on the specific requirements of each component.
Cache-Conscious Design
Modern CPUs rely heavily on cache efficiency. RIOC's design considers cache behavior at multiple levels:
1. Cache Line Alignment
To prevent false sharing (where threads inadvertently contend for the same cache line), RIOC aligns critical data structures to cache line boundaries:
// Cache line size detection
#ifndef RIOC_CACHE_LINE_SIZE
#define RIOC_CACHE_LINE_SIZE 64
#endif
// Apply alignment to structures
struct rioc_connection {
// Fields frequently accessed together
} __attribute__((aligned(RIOC_CACHE_LINE_SIZE)));
// Pad data structures to prevent false sharing
struct work_queue {
atomic_size_t head;
char pad1[RIOC_CACHE_LINE_SIZE - sizeof(atomic_size_t)]; // Padding
atomic_size_t tail;
char pad2[RIOC_CACHE_LINE_SIZE - sizeof(atomic_size_t)]; // Padding
// Rest of structure...
};
2. Data Locality
RIOC organizes data structures to keep related data together:
// Group related fields for better locality
struct rioc_batch_op {
// Header and key fields that are accessed together during parsing
struct rioc_op_header header;
char key[RIOC_MAX_KEY_SIZE];
// Value pointer and metadata accessed during data processing
char *value_ptr;
size_t value_offset;
// Response fields accessed together
struct rioc_response response;
};
3. Prefetching
For predictable access patterns, RIOC uses explicit prefetching to hide memory latency:
// Prefetch next batch operation
for (size_t i = 0; i < batch->count; i++) {
struct rioc_batch_op *op = &batch->ops[i];
// Prefetch the next operation if available
if (i + 1 < batch->count) {
__builtin_prefetch(&batch->ops[i + 1], 0, 3);
}
// Process current operation...
}
Platform-Specific Optimizations
RIOC is designed to work well across platforms, but it also includes targeted optimizations for specific environments:
Linux-Specific Optimizations
#ifdef __linux__
// Use Linux-specific socket options
#ifdef TCP_QUICKACK
setsockopt(fd, IPPROTO_TCP, TCP_QUICKACK, &flag, sizeof(flag));
#endif
#ifdef SO_BUSY_POLL
// Reduce latency with busy polling for Linux kernels >= 3.11
int busy_poll = 50; // 50 microseconds
setsockopt(fd, SOL_SOCKET, SO_BUSY_POLL, &busy_poll, sizeof(busy_poll));
#endif
// CPU affinity for performance-critical threads
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(target_cpu, &cpuset);
pthread_setaffinity_np(pthread_self(), sizeof(cpu_set_t), &cpuset);
#endif
macOS/BSD-Specific Optimizations
#if defined(__APPLE__) || defined(__FreeBSD__)
// Use kqueue for event notification
int kq = kqueue();
struct kevent ev;
EV_SET(&ev, fd, EVFILT_READ, EV_ADD, 0, 0, NULL);
kevent(kq, &ev, 1, NULL, 0, NULL);
#endif
Windows-Specific Optimizations
#ifdef _WIN32
// Use Windows-specific socket options
int timeout = 1000; // 1 second in milliseconds
setsockopt(fd, SOL_SOCKET, SO_RCVTIMEO, (const char*)&timeout, sizeof(timeout));
// Use I/O completion ports for scalable I/O
HANDLE iocp = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, 0, 0);
CreateIoCompletionPort((HANDLE)fd, iocp, (ULONG_PTR)context, 0);
#endif
Thread-per-Connection Model with Worker Pool
RIOC's server architecture uses a sophisticated threading model that balances throughput, latency, and resource utilization.
Traditional server designs follow either a thread-per-connection model (simple but resource-intensive) or an event loop model (efficient but complex to implement and potentially higher latency). RIOC takes a hybrid approach:
// Connection acceptance loop
while (server_running) {
client_fd = accept(server_fd, ...);
// Create client context
client_ctx = create_client_context(client_fd, ...);
// Queue for worker thread rather than handling inline
work_queue_push(client_ctx);
}
// Worker thread function
void* worker_thread_func(void *arg) {
while (server_running) {
// Get next client context from queue
client_ctx = work_queue_pop();
if (!client_ctx) continue;
// Process client requests
process_client_requests(client_ctx);
}
}
The implementation uses a lock-free work queue with cache-line alignment to minimize contention:
struct work_queue {
// Align head and tail to different cache lines to prevent false sharing
atomic_size_t head RIOC_ALIGNED;
char pad1[CACHE_LINE_SIZE - sizeof(atomic_size_t)];
atomic_size_t tail RIOC_ALIGNED;
char pad2[CACHE_LINE_SIZE - sizeof(atomic_size_t)];
struct client_context *clients[MAX_QUEUE_SIZE];
// Mutex and condition variables for synchronization
pthread_mutex_t mutex;
pthread_cond_t not_empty;
pthread_cond_t not_full;
} RIOC_ALIGNED;
This design provides several benefits:
- Connection/Processing Separation: Connection handling is decoupled from request processing
- Controlled Concurrency: The worker pool size limits the number of concurrent operations
- Efficient CPU Utilization: Work is distributed across available cores without oversubscription
- Reduced Contention: Cache-line alignment and atomic operations minimize lock contention
For memory barriers, RIOC uses C11's atomic operations to ensure proper ordering:
// Store with release semantics
atomic_store_explicit(&work_queue.tail, next_tail, memory_order_release);
// Load with acquire semantics to ensure visibility of previous stores
size_t head = atomic_load_explicit(&work_queue.head, memory_order_acquire);
Secure Communication with mTLS
Security shouldn't come at the expense of performance. RIOC implements TLS 1.3 with mutual authentication (mTLS) for secure client-server communication.
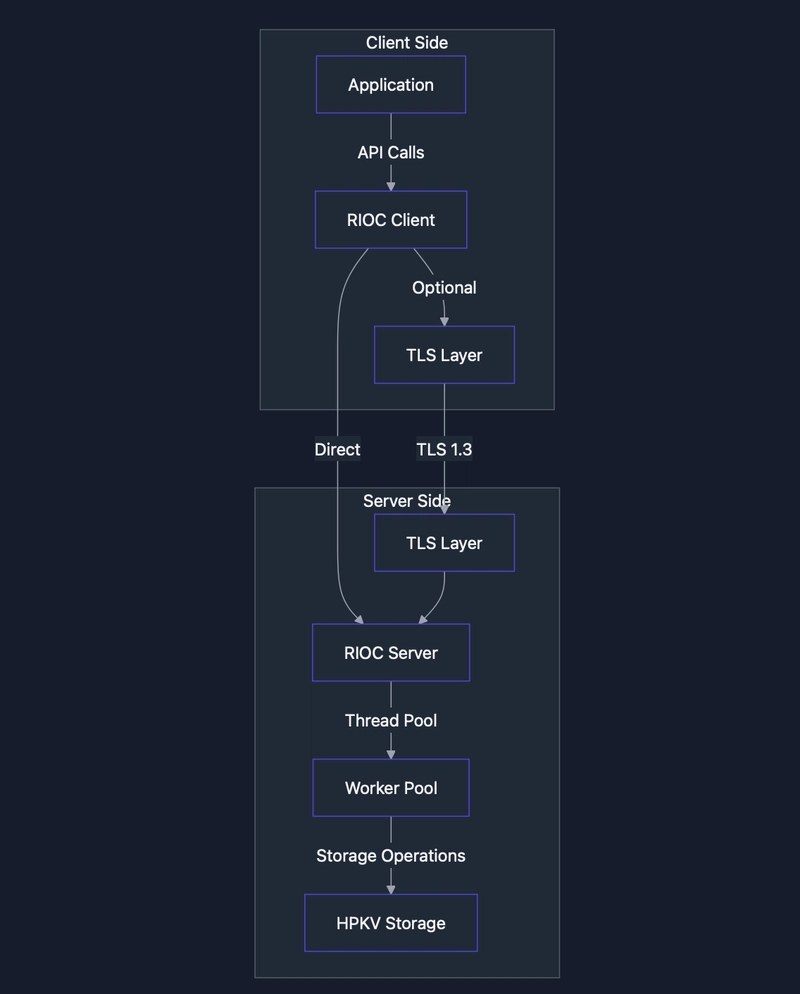
What is mTLS?
Traditional TLS primarily authenticates the server to the client. Mutual TLS (mTLS) extends this by also authenticating the client to the server:
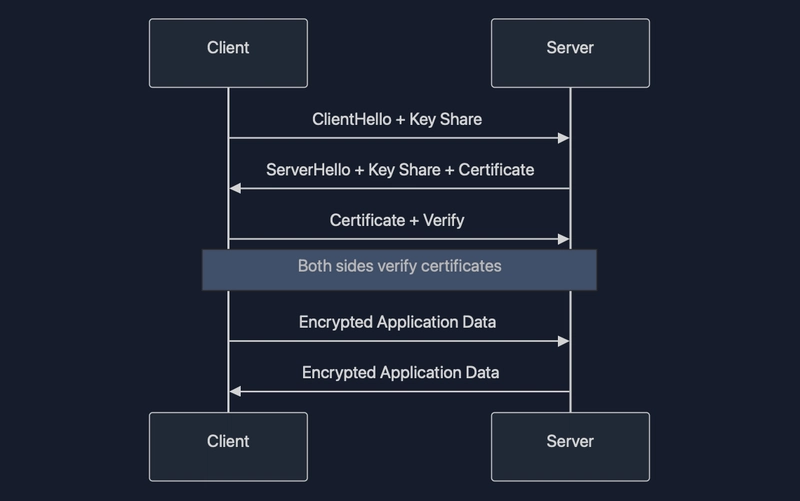
This bidirectional verification ensures that both parties are who they claim to be, which is essential in distributed systems where nodes need to trust each other.
RIOC's TLS Implementation
RIOC implements TLS using OpenSSL with the following key features:
- TLS 1.3 Only: Enforces the use of the latest TLS protocol version
SSL_CTX_set_min_proto_version(ctx, TLS1_3_VERSION);
SSL_CTX_set_max_proto_version(ctx, TLS1_3_VERSION);
- Client and Server Verification: Optional but recommended mutual authentication
// When verification is enabled
SSL_CTX_set_verify(ctx, SSL_VERIFY_PEER | SSL_VERIFY_FAIL_IF_NO_PEER_CERT, NULL);
- Hostname/IP Validation: Ensures the certificate matches the expected hostname
X509_VERIFY_PARAM *param = SSL_get0_param(ssl);
X509_VERIFY_PARAM_set1_host(param, hostname, strlen(hostname));
Performance Implications of TLS
TLS traditionally adds overhead, but RIOC mitigates this through several approaches:
- Chunked TLS I/O: Uses optimal chunk sizes (16KB) for TLS encryption/decryption
#define RIOC_TLS_CHUNK_SIZE 16000 // Slightly less than 16KB for TLS overhead
Session Reuse: Maintains TLS sessions for repeated connections between the same endpoints, avoiding expensive handshakes
Modern Ciphers: TLS 1.3 includes more efficient symmetric encryption algorithms like ChaCha20-Poly1305 and AES-GCM
Batch Processing for Amplified Performance
Individual operations have fixed overhead costs. RIOC's batch API allows grouping multiple operations.
The implementation uses a structured approach to minimize memory allocations and maximizes locality:
struct rioc_batch_op {
struct rioc_op_header header;
char key[RIOC_MAX_KEY_SIZE]; // Fixed buffer for key
char *value_ptr; // Pointer to value in shared buffer
size_t value_offset; // Offset in batch buffer
struct rioc_response response; // Pre-allocated response
struct iovec iov[RIOC_MAX_IOV]; // Pre-allocated IOVs
} __attribute__((aligned(RIOC_CACHE_LINE_SIZE)));
struct rioc_batch {
struct rioc_batch_header batch_header;
struct rioc_batch_op ops[RIOC_MAX_BATCH_SIZE];
char *value_buffer; // Single buffer for all values
size_t value_buffer_size;
size_t value_buffer_used;
size_t count;
size_t iov_count;
uint32_t flags;
} __attribute__((aligned(RIOC_CACHE_LINE_SIZE)));
This structure optimizes memory usage in several ways:
- Single Allocation: Values are stored in a contiguous buffer, reducing fragmentation
- Pre-allocated IOVs: Each operation has pre-allocated I/O vectors, avoiding dynamic allocations
- Cache Alignment: Structures are aligned to cache lines to prevent false sharing
- Key Size Limits: Fixed-size key buffers avoid dynamic allocation for common cases
The batch API provides both synchronous and asynchronous interfaces:
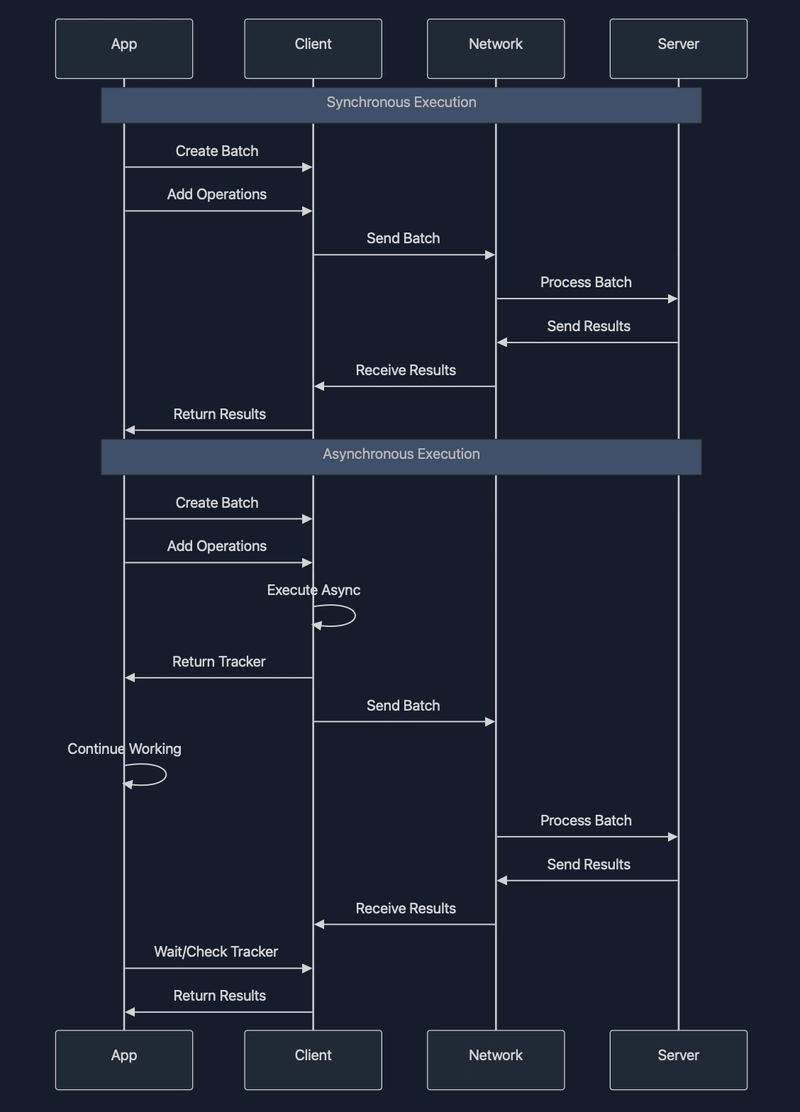
Real-world Performance Considerations
While the optimizations described above yield significant benefits, several real-world factors influence RIOC's performance:
Network Latency
Our benchmarks show that deployment environment drastically affects observed latency:
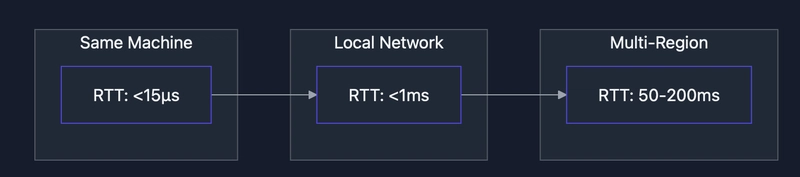
When latency increases, batching becomes even more critical for maintaining throughput. Our tests show:
- Same Machine: Single operations take ~15μs, while batched operations amortize to <1μs per operation
- Local Network: Single operations take ~500-800μs, while batched operations drop to ~100μs per operation
- Multi-Region: Batching becomes essential, reducing effective per-operation time by up to 90%
Memory Management
RIOC uses thread-local buffers and alignment to optimize memory access:
static __thread char recv_buffer[4096] __attribute__((aligned(RIOC_CACHE_LINE_SIZE)));
This prevents false sharing between threads and reduces cache line bouncing. The __thread qualifier ensures each thread has its own copy of the buffer, eliminating contention and synchronization needs.
The implementation also strategically uses prefetching hints to mitigate memory latency:
// Prefetch the next IOV entry before processing
if (curr_iovcnt > 1) {
__builtin_prefetch(curr_iov + 1, 0, 3); // Read, high temporal locality
}
Conclusion
Building high-performance networking for distributed systems requires careful attention to both low-level details and higher-level architectural choices. In RIOC, we've tried to balance several competing concerns:
- Performance through vectored I/O, zero-copy transfers, socket tuning, and batching
- Security through TLS 1.3 and mutual authentication
- Reliability through timeout handling and error recovery
- Maintainability through clear architecture and platform abstractions
While we're pleased with the results achieved so far, we recognize that networking performance optimization is never truly "finished." There's always room for improvement, and we continue to learn and refine our approach as we gather more real-world usage data and as the underlying platforms evolve.
Many of the techniques described here weren't novel inventions—they build on the excellent work of others in the systems and networking communities. Our contribution has been to synthesize these approaches into a coherent system that addresses the specific needs of high-performance distributed key-value stores.
If you're interested in exploring RIOC further or contributing to its development, you can find the code (except the server component) in our GitHub repository as part of the HPKV project. We welcome feedback, questions, and contributions as we continue this journey.