_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
































































![Apple Developing AI 'Vibe-Coding' Assistant for Xcode With Anthropic [Report]](https://www.iclarified.com/images/news/97200/97200/97200-640.jpg)
![Apple's New Ads Spotlight Apple Watch for Kids [Video]](https://www.iclarified.com/images/news/97197/97197/97197-640.jpg)












































































































_Andy_Dean_Photography_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)




























































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)





































































































How to Run DeepSeek Locally Using Ollama
In a time when data privacy, performance, and cost control are critical, running large language models (LLMs) locally is becoming increasingly practical. Among the open-source offerings, DeepSeek-R1 models stand out due to their strong performance in coding, logical reasoning, and problem-solving tasks. This guide explains how to install and run DeepSeek-R1 models locally using Ollama, and optionally expose them securely online using Pinggy. It's aimed at developers and IT professionals who want a self-hosted, offline-capable, and customizable LLM stack. Why Consider Running DeepSeek-R1 Models Locally? Running models like DeepSeek-R1 on your local machine offers several practical advantages: Data stays local – no external server or API receives your prompts. Zero cloud usage limits – you control the compute resources. Offline-ready – ideal for air-gapped or restricted networks. Choose models by system specs – from lightweight to high-performance variants. Step 1: Install Ollama Ollama provides a simple command-line interface to run open-source LLMs locally. Installation: Head to ollama. Choose your operating system (Linux, macOS, or Windows). Follow the installation prompts. After setup, open your terminal and check the installation: ollama --version Step 2: Pull a DeepSeek-R1 Model DeepSeek models are available in various sizes to suit different hardware capacities. Choose Based on Your System: Basic system (≤ 8GB RAM): ollama pull deepseek-r1:1.5b Mid-tier system (≥ 16GB RAM): ollama pull deepseek-r1:7b High-performance systems (≥ 32GB RAM): ollama pull deepseek-r1:8b ollama pull deepseek-r1:14b Check which models are downloaded: ollama list Step 3: Run the Model Locally Once the model is pulled, running it is straightforward: ollama run deepseek-r1:1.5b This opens an interactive terminal session. You can begin asking coding questions, logical reasoning problems, or other NLP tasks. Example prompt: You: What’s the output of the following Python code? print([i**2 for i in range(5)]) Step 4 (Optional): Use DeepSeek via API Ollama exposes an API interface so you can integrate DeepSeek-R1 into apps or scripts. Start the API Server: ollama serve Send an API request: curl http://localhost:11434/api/chat \ -H "Content-Type: application/json" \ -d '{ "model": "deepseek-r1:1.5b", "messages": [{"role":"user", "content":"Hello"}] }' You can build apps on top of this using JavaScript, Python, or other frameworks. Step 5 (Optional): Use a GUI via Open WebUI For those who prefer a ChatGPT-style web interface: Run Open WebUI via Docker: docker run -d -p 3000:8080 \ --add-host=host.docker.internal:host-gateway \ -v open-webui:/app/backend/data \ --name open-webui \ --restart always \ ghcr.io/open-webui/open-webui:main Access the GUI: Open your browser at http://localhost:3000, set up an admin account, and select a DeepSeek model to start chatting. Step 6 (Optional): Share Your Ollama API Online with Pinggy If you want to test or access your local model remotely, you can forward Ollama's API port online using Pinggy. Start Ollama Server: ollama serve Create a Public Tunnel: ssh -p 443 -R0:localhost:11434 -t qr@a.pinggy.io "u:Host:localhost:11434" Explanation: -p 443: Uses HTTPS-compatible port to avoid firewall blocks. -R0:localhost:11434: Forwards Ollama's local API port. qr@a.pinggy.io: Pinggy SSH endpoint. "u:Host:localhost:11434": Header forwarding to allow remote access. Once executed, Pinggy will return a public HTTPS URL like https://yourid.pinggy.link. Verify the API Online: curl https://yourid.pinggy.link/api/tags You can now test your model remotely or share this URL with collaborators. Performance Optimization Tips Use quantized versions to reduce memory usage: ollama pull deepseek-r1:1.5b-q4_K_M Limit context size to reduce latency: ollama run deepseek-r1:1.5b --num_ctx 1024 Control randomness and creativity with temperature: ollama run deepseek-r1:1.5b --temperature 0.7 --top_p 0.9 Troubleshooting Model not loading? Try a smaller size or close background applications. Slow output? Use a quantized model or reduce num_ctx. API not reachable? Confirm ollama serve is running and Pinggy tunnel is active. About the DeepSeek-R1 Family Released under the MIT license Models available: Qwen-based: 1.5B, 7B, 14B, 32B LLaMA-based: 8B, 70B Suitable for reasoning, software development, and general-purpose NLP Conclusion Running DeepSeek locally using Ollama is a powerful option for developers looking for secure, cost-efficie

In a time when data privacy, performance, and cost control are critical, running large language models (LLMs) locally is becoming increasingly practical. Among the open-source offerings, DeepSeek-R1 models stand out due to their strong performance in coding, logical reasoning, and problem-solving tasks.
This guide explains how to install and run DeepSeek-R1 models locally using Ollama, and optionally expose them securely online using Pinggy. It's aimed at developers and IT professionals who want a self-hosted, offline-capable, and customizable LLM stack.
Why Consider Running DeepSeek-R1 Models Locally?
Running models like DeepSeek-R1 on your local machine offers several practical advantages:
- Data stays local – no external server or API receives your prompts.
- Zero cloud usage limits – you control the compute resources.
- Offline-ready – ideal for air-gapped or restricted networks.
- Choose models by system specs – from lightweight to high-performance variants.
Step 1: Install Ollama
Ollama provides a simple command-line interface to run open-source LLMs locally.
Installation:
- Head to ollama.
- Choose your operating system (Linux, macOS, or Windows).
- Follow the installation prompts.
- After setup, open your terminal and check the installation:
ollama --version
Step 2: Pull a DeepSeek-R1 Model
DeepSeek models are available in various sizes to suit different hardware capacities.
Choose Based on Your System:
- Basic system (≤ 8GB RAM):
ollama pull deepseek-r1:1.5b
- Mid-tier system (≥ 16GB RAM):
ollama pull deepseek-r1:7b
- High-performance systems (≥ 32GB RAM):
ollama pull deepseek-r1:8b
ollama pull deepseek-r1:14b
Check which models are downloaded:
ollama list

Step 3: Run the Model Locally
Once the model is pulled, running it is straightforward:
ollama run deepseek-r1:1.5b
This opens an interactive terminal session. You can begin asking coding questions, logical reasoning problems, or other NLP tasks.
Example prompt:
You: What’s the output of the following Python code?
print([i**2 for i in range(5)])
Step 4 (Optional): Use DeepSeek via API
Ollama exposes an API interface so you can integrate DeepSeek-R1 into apps or scripts.
Start the API Server:
ollama serve
Send an API request:
curl http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1:1.5b",
"messages": [{"role":"user", "content":"Hello"}]
}'
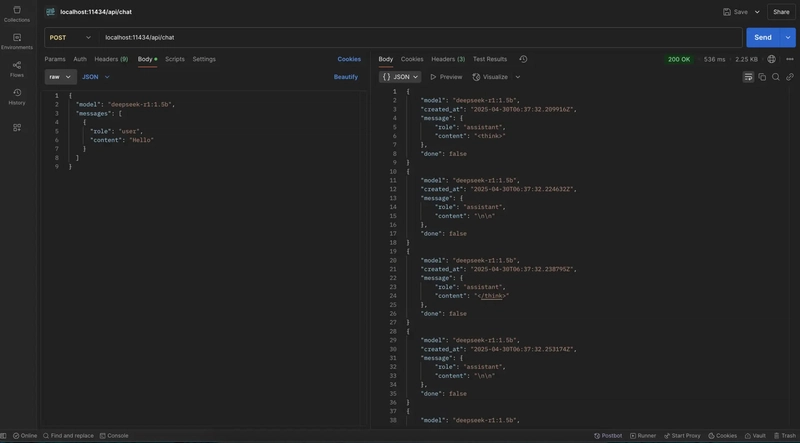
You can build apps on top of this using JavaScript, Python, or other frameworks.
Step 5 (Optional): Use a GUI via Open WebUI
For those who prefer a ChatGPT-style web interface:
Run Open WebUI via Docker:
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
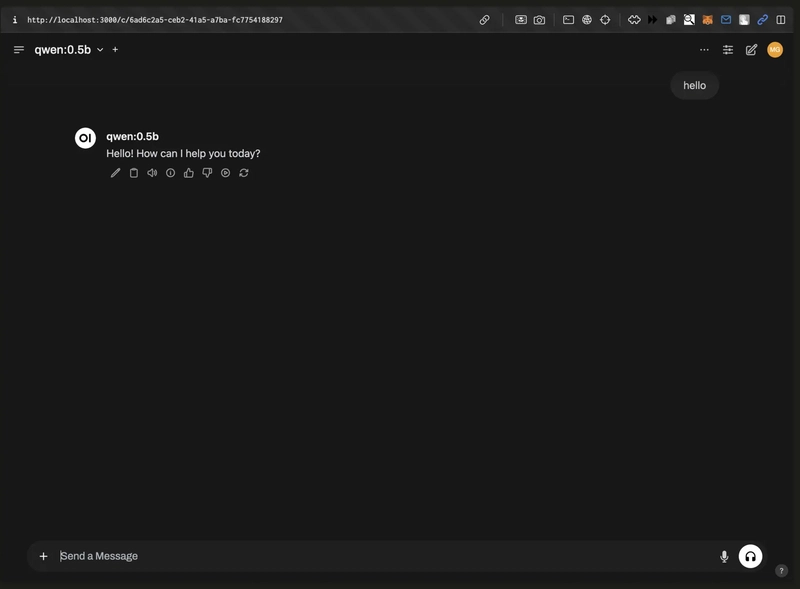
Access the GUI:
Open your browser at http://localhost:3000, set up an admin account, and select a DeepSeek model to start chatting.
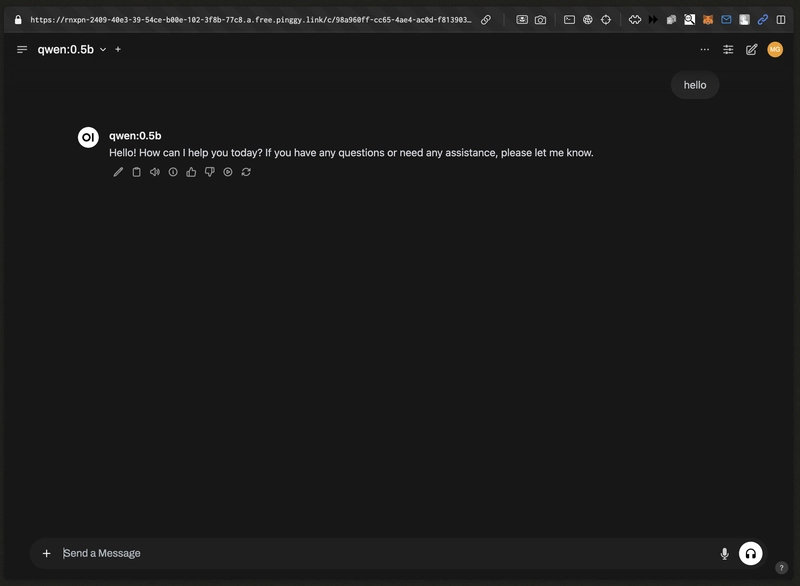
Step 6 (Optional): Share Your Ollama API Online with Pinggy
If you want to test or access your local model remotely, you can forward Ollama's API port online using Pinggy.
Start Ollama Server:
ollama serve

Create a Public Tunnel:
ssh -p 443 -R0:localhost:11434 -t qr@a.pinggy.io "u:Host:localhost:11434"

Explanation:
-
-p 443: Uses HTTPS-compatible port to avoid firewall blocks. -
-R0:localhost:11434: Forwards Ollama's local API port. -
qr@a.pinggy.io: Pinggy SSH endpoint. -
"u:Host:localhost:11434": Header forwarding to allow remote access.
Once executed, Pinggy will return a public HTTPS URL like https://yourid.pinggy.link.

Verify the API Online:
curl https://yourid.pinggy.link/api/tags
You can now test your model remotely or share this URL with collaborators.

Performance Optimization Tips
- Use quantized versions to reduce memory usage:
ollama pull deepseek-r1:1.5b-q4_K_M
- Limit context size to reduce latency:
ollama run deepseek-r1:1.5b --num_ctx 1024
- Control randomness and creativity with temperature:
ollama run deepseek-r1:1.5b --temperature 0.7 --top_p 0.9
Troubleshooting
- Model not loading? Try a smaller size or close background applications.
-
Slow output? Use a quantized model or reduce
num_ctx. -
API not reachable? Confirm
ollama serveis running and Pinggy tunnel is active.
About the DeepSeek-R1 Family
- Released under the MIT license
-
Models available:
- Qwen-based: 1.5B, 7B, 14B, 32B
- LLaMA-based: 8B, 70B
Suitable for reasoning, software development, and general-purpose NLP
Conclusion
Running DeepSeek locally using Ollama is a powerful option for developers looking for secure, cost-efficient AI solutions. Whether you’re prototyping applications, working in restricted environments, or simply want better control over AI workflows, this local deployment method gives you freedom without sacrificing performance.




