






























































![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)

![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)


































































































_Christophe_Coat_Alamy.jpg?#)











































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)




































.jpg?#)



.png?#)


















































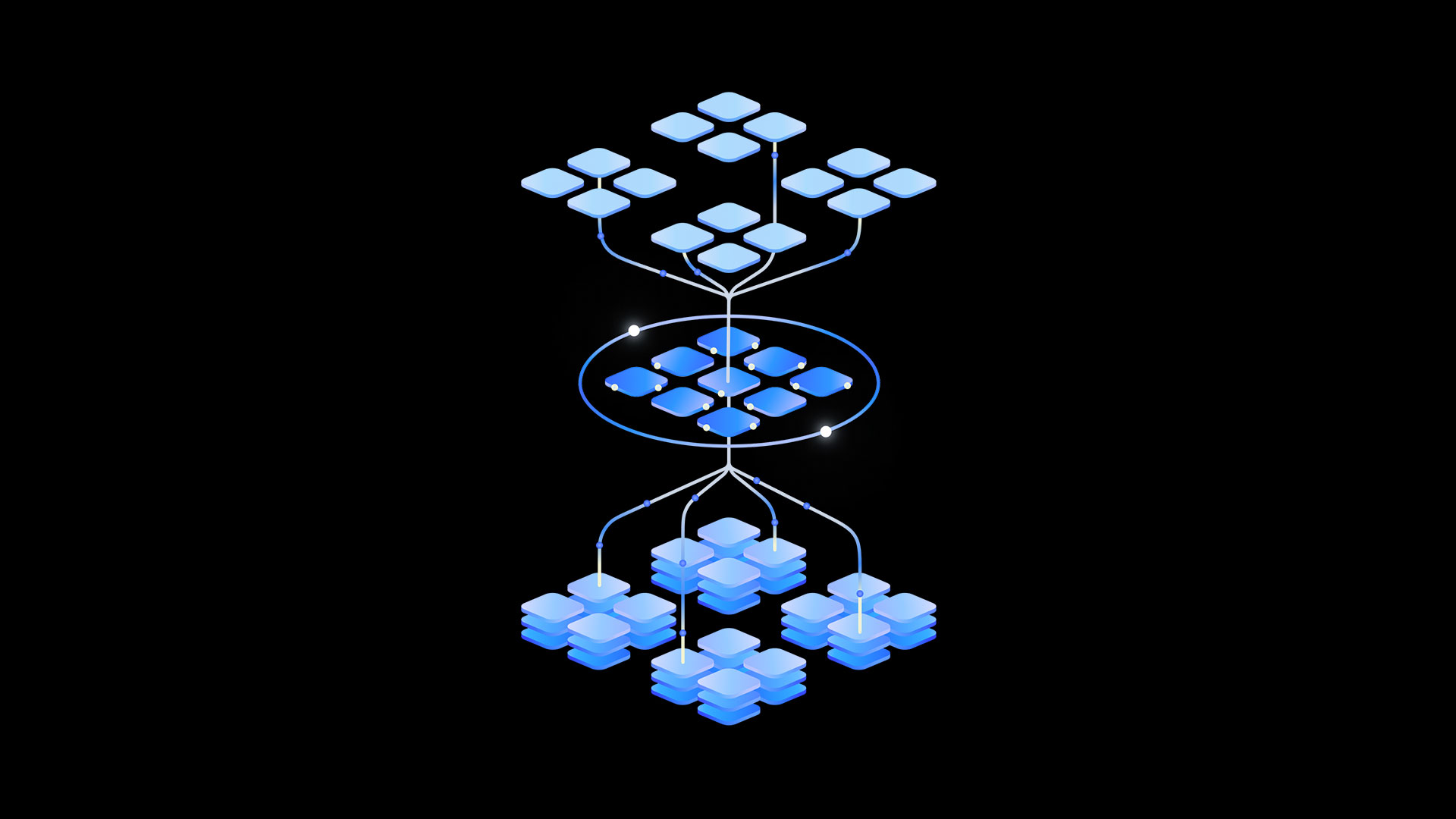
New AI Reward System Outperforms Larger Models Using Smart Inference Scaling
This is a Plain English Papers summary of a research paper called New AI Reward System Outperforms Larger Models Using Smart Inference Scaling. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview DeepSeek-GRM introduces a new approach to reward modeling for large language models Uses Self-Principled Critique Tuning (SPCT) to improve inference-time scalability Generates principles and critiques adaptively for better reward signals Employs parallel sampling and meta reward modeling for effective compute scaling Outperforms existing methods across various benchmarks without severe biases Shows inference-time scaling can be more effective than training-time scaling Plain English Explanation When we train advanced AI systems like large language models (LLMs), we need ways to tell them when they're doing a good job. This is called "reward modeling" - creating signals that guide the AI toward better performance. The researchers behind this paper developed a new appr... Click here to read the full summary of this paper

This is a Plain English Papers summary of a research paper called New AI Reward System Outperforms Larger Models Using Smart Inference Scaling. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- DeepSeek-GRM introduces a new approach to reward modeling for large language models
- Uses Self-Principled Critique Tuning (SPCT) to improve inference-time scalability
- Generates principles and critiques adaptively for better reward signals
- Employs parallel sampling and meta reward modeling for effective compute scaling
- Outperforms existing methods across various benchmarks without severe biases
- Shows inference-time scaling can be more effective than training-time scaling
Plain English Explanation
When we train advanced AI systems like large language models (LLMs), we need ways to tell them when they're doing a good job. This is called "reward modeling" - creating signals that guide the AI toward better performance.
The researchers behind this paper developed a new appr...







