


























































![Apple to Craft Key Foldable iPhone Components From Liquid Metal [Kuo]](https://www.iclarified.com/images/news/96784/96784/96784-640.jpg)

![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)












































































































_Federico_Caputo_Alamy.jpg?#)
































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)



















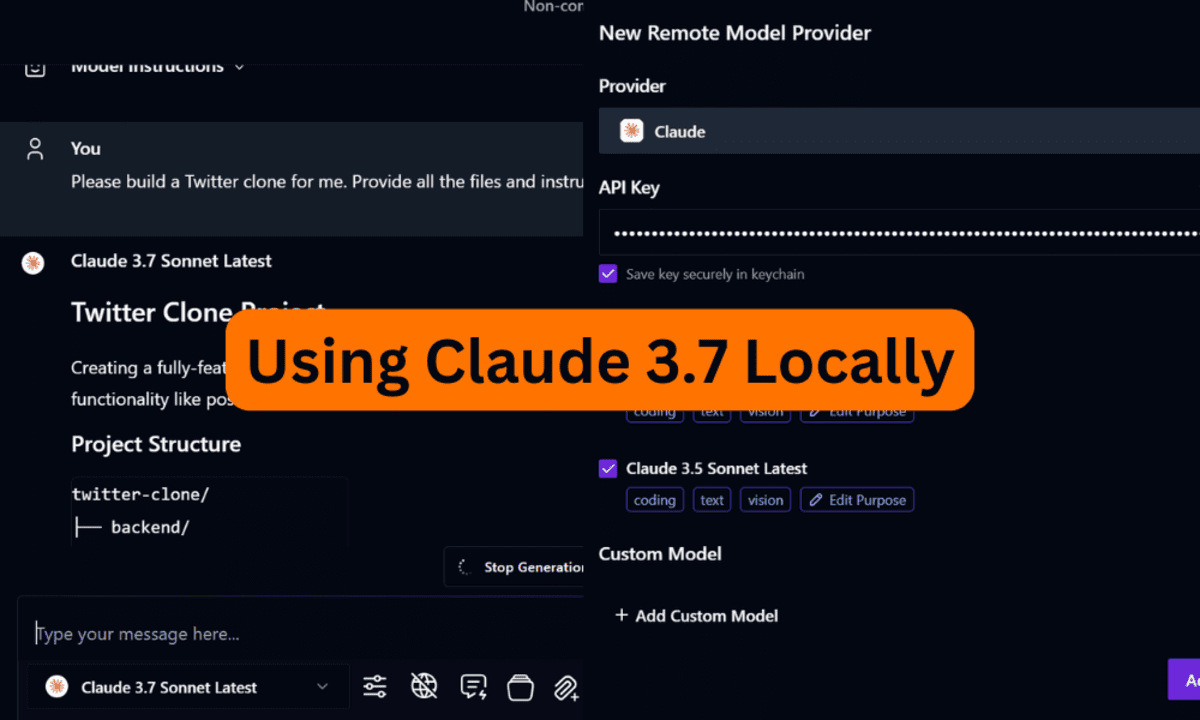
































































































![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)

































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





.png?#)













































"Unlocking Visual Intelligence: The Power of the TULIP Model in AI"
In a world increasingly dominated by visual data, the ability to harness and interpret this information is more crucial than ever. Have you ever felt overwhelmed by the sheer volume of images and videos flooding your screens daily? Or perhaps you've struggled to extract meaningful insights from complex visual content? You're not alone. Many professionals grapple with these challenges, yearning for clarity amidst chaos. Enter the TULIP Model—a revolutionary framework designed to unlock your visual intelligence potential in artificial intelligence (AI). This blog post will take you on an enlightening journey through the intricacies of visual intelligence, demystifying what it means and how the TULIP Model can transform your approach to AI applications. From understanding its core components to exploring real-world success stories that showcase its impact, we’ll delve into why adopting this model could be a game-changer for you and your organization. Are you ready to elevate your understanding of visuals in AI and discover practical strategies that lead to tangible results? Join us as we explore how unlocking visual intelligence can empower you in today’s data-driven landscape! Understanding Visual Intelligence Visual intelligence refers to the ability of machines to interpret and understand visual data, akin to human perception. The TULIP model exemplifies this concept by integrating advanced methodologies such as generative data augmentation and contrastive learning techniques. By focusing on fine-grained visual features while ensuring global semantic alignment, TULIP enhances tasks that require nuanced understanding, including multi-view reasoning and object localization. This model's architecture is designed for versatility in self-supervised image-text contrastive learning, making it a significant advancement in computer vision. Key Components of Visual Intelligence TULIP’s innovative approach combines various elements like image-image contrastive learning with reconstruction methods that balance high-frequency details against broader semantic contexts. Its performance across benchmarks illustrates its capability in zero-shot classification and few-shot scenarios—tasks where traditional models often struggle. Furthermore, the integration of attention visualization aids researchers in comprehending how models prioritize different aspects of input images during processing, thus enhancing transparency and trustworthiness within AI systems focused on visual intelligence. What is the TULIP Model? The TULIP model represents a significant advancement in contrastive image-text learning, addressing previous limitations by enhancing visual understanding and language alignment. By employing generative data augmentation alongside innovative techniques like image-image and text-text contrastive learning, TULIP effectively captures fine-grained visual features while ensuring global semantic coherence. This model excels particularly in zero-shot and few-shot classification tasks as well as complex vision-language applications such as multi-view reasoning, instance segmentation, counting, depth estimation, and object localization. The integration of GeCo for generative augmentation further strengthens its performance through effective regularization methods that balance high-frequency visual details with overarching semantic representations. Performance Insights TULIP's experimental framework utilizes diverse datasets including video and multi-view inputs to optimize its capabilities using advanced methodologies like the Adam optimizer. Its impressive results across various benchmarks demonstrate superior efficacy compared to existing models in detail-oriented tasks. Notably, ablation studies reveal critical components—such as reconstruction techniques—that significantly enhance performance on vision-centric challenges. Furthermore, the model's versatility positions it favorably within large-scale multimodal frameworks like LLaVA (Large Language Vision Architecture), showcasing its potential for self-supervised learning paradigms in contemporary AI research landscapes.# Applications of TULIP in AI The TULIP model showcases remarkable versatility across various applications within artificial intelligence, particularly in enhancing visual understanding and language alignment. Its strengths lie in zero-shot and few-shot classification tasks, making it invaluable for scenarios where labeled data is scarce. The integration of generative data augmentation techniques allows TULIP to excel in fine-grained visual tasks such as instance segmentation and object localization. Furthermore, its capabilities extend to complex vision-language interactions, enabling nuanced multi-view reasoning and depth estimation. Key Areas of Application Vision-Language Tasks: TULIP's architecture supports advanced multimodal learning by aligning textual descriptions with corresponding images effectively. Fine-Grained Visual Recogni

In a world increasingly dominated by visual data, the ability to harness and interpret this information is more crucial than ever. Have you ever felt overwhelmed by the sheer volume of images and videos flooding your screens daily? Or perhaps you've struggled to extract meaningful insights from complex visual content? You're not alone. Many professionals grapple with these challenges, yearning for clarity amidst chaos. Enter the TULIP Model—a revolutionary framework designed to unlock your visual intelligence potential in artificial intelligence (AI). This blog post will take you on an enlightening journey through the intricacies of visual intelligence, demystifying what it means and how the TULIP Model can transform your approach to AI applications. From understanding its core components to exploring real-world success stories that showcase its impact, we’ll delve into why adopting this model could be a game-changer for you and your organization. Are you ready to elevate your understanding of visuals in AI and discover practical strategies that lead to tangible results? Join us as we explore how unlocking visual intelligence can empower you in today’s data-driven landscape!
Understanding Visual Intelligence
Visual intelligence refers to the ability of machines to interpret and understand visual data, akin to human perception. The TULIP model exemplifies this concept by integrating advanced methodologies such as generative data augmentation and contrastive learning techniques. By focusing on fine-grained visual features while ensuring global semantic alignment, TULIP enhances tasks that require nuanced understanding, including multi-view reasoning and object localization. This model's architecture is designed for versatility in self-supervised image-text contrastive learning, making it a significant advancement in computer vision.
Key Components of Visual Intelligence
TULIP’s innovative approach combines various elements like image-image contrastive learning with reconstruction methods that balance high-frequency details against broader semantic contexts. Its performance across benchmarks illustrates its capability in zero-shot classification and few-shot scenarios—tasks where traditional models often struggle. Furthermore, the integration of attention visualization aids researchers in comprehending how models prioritize different aspects of input images during processing, thus enhancing transparency and trustworthiness within AI systems focused on visual intelligence.

What is the TULIP Model?
The TULIP model represents a significant advancement in contrastive image-text learning, addressing previous limitations by enhancing visual understanding and language alignment. By employing generative data augmentation alongside innovative techniques like image-image and text-text contrastive learning, TULIP effectively captures fine-grained visual features while ensuring global semantic coherence. This model excels particularly in zero-shot and few-shot classification tasks as well as complex vision-language applications such as multi-view reasoning, instance segmentation, counting, depth estimation, and object localization. The integration of GeCo for generative augmentation further strengthens its performance through effective regularization methods that balance high-frequency visual details with overarching semantic representations.
Performance Insights
TULIP's experimental framework utilizes diverse datasets including video and multi-view inputs to optimize its capabilities using advanced methodologies like the Adam optimizer. Its impressive results across various benchmarks demonstrate superior efficacy compared to existing models in detail-oriented tasks. Notably, ablation studies reveal critical components—such as reconstruction techniques—that significantly enhance performance on vision-centric challenges. Furthermore, the model's versatility positions it favorably within large-scale multimodal frameworks like LLaVA (Large Language Vision Architecture), showcasing its potential for self-supervised learning paradigms in contemporary AI research landscapes.# Applications of TULIP in AI
The TULIP model showcases remarkable versatility across various applications within artificial intelligence, particularly in enhancing visual understanding and language alignment. Its strengths lie in zero-shot and few-shot classification tasks, making it invaluable for scenarios where labeled data is scarce. The integration of generative data augmentation techniques allows TULIP to excel in fine-grained visual tasks such as instance segmentation and object localization. Furthermore, its capabilities extend to complex vision-language interactions, enabling nuanced multi-view reasoning and depth estimation.
Key Areas of Application
-
Vision-Language Tasks: TULIP's architecture supports advanced multimodal learning by aligning textual descriptions with corresponding images effectively.
-
Fine-Grained Visual Recognition: The model significantly improves performance on detail-oriented tasks through image-image contrastive learning combined with reconstruction methods.
-
Data Augmentation Techniques: By leveraging GeCo for generative augmentation, TULIP enhances the richness of training datasets while maintaining semantic integrity.
-
Benchmark Performance: Experimental results indicate that TULIP outperforms existing models across a variety of benchmarks, solidifying its position as a state-of-the-art solution for computer vision challenges.
Through these applications, the TULIP framework not only advances academic research but also paves the way for practical implementations in industries reliant on sophisticated image-text analysis systems.# Benefits of Using the TULIP Framework
The TULIP framework offers numerous advantages, particularly in enhancing visual understanding and language alignment. By leveraging generative data augmentation and contrastive learning techniques, it effectively captures fine-grained visual features while ensuring global semantic coherence. This model excels in zero-shot and few-shot classification tasks, making it highly adaptable for various applications such as instance segmentation and object localization. The incorporation of GeCo for generative augmentation further enriches its performance by balancing high-frequency visual information with robust semantic representation. Additionally, the experimental design utilizing diverse datasets ensures that TULIP remains at the forefront of state-of-the-art performance across multiple benchmarks.
Enhanced Performance Metrics
TULIP's architecture is specifically designed to address limitations found in existing models by employing innovative strategies like image-image contrastive learning and reconstruction methods. These enhancements lead to significant improvements in detail-oriented tasks within computer vision, allowing researchers to achieve better accuracy rates on complex datasets. Furthermore, ablation studies highlight which components contribute most effectively to its success—providing valuable insights into optimizing future multimodal models for both academic research and practical implementations in AI-driven solutions.
Real-World Success Stories
The TULIP model has demonstrated remarkable success across various real-world applications, particularly in enhancing visual understanding and language alignment. For instance, its performance in zero-shot classification allows it to accurately categorize images without prior training on specific classes, making it invaluable for dynamic environments where new categories frequently emerge. In practical scenarios like autonomous driving or surveillance systems, TULIP's ability to perform few-shot classification enables rapid adaptation to novel objects with minimal data input.
Moreover, the model excels in complex tasks such as object localization and depth estimation. This capability is crucial for industries ranging from robotics to augmented reality, where precise spatial awareness is essential. Companies leveraging TULIP have reported significant improvements in their AI-driven products' accuracy and efficiency—transforming user experiences by providing more intuitive interactions with technology.
Key Case Studies
One notable case study involves a leading tech firm utilizing TULIP for image segmentation tasks within medical imaging applications. By achieving state-of-the-art results on benchmark datasets, they enhanced diagnostic capabilities significantly while reducing processing time. Another example includes an e-commerce platform that employed TULIP’s generative augmentation techniques to improve product recommendation systems based on visual content analysis—leading to increased customer engagement and sales conversions.
These success stories highlight how the innovative features of the TULIP framework can lead not only to technological advancements but also substantial business growth across diverse sectors.
Future Trends in Visual Intelligence
The TULIP model represents a significant advancement in visual intelligence, addressing the limitations of traditional contrastive image-text models. By focusing on generative data augmentation and enhancing visual understanding through image-image and text-text contrastive learning, TULIP is poised to lead future trends in AI. Its ability to excel in zero-shot and few-shot classification tasks positions it as a versatile tool for complex applications such as multi-view reasoning and object localization. As researchers continue to explore its capabilities across diverse datasets, we can expect innovations that enhance fine-grained detail recognition while maintaining semantic coherence.
Advancements in Multimodal Learning
Future developments will likely emphasize multimodal learning frameworks that integrate various forms of data—textual, visual, and auditory—to create more comprehensive AI systems. The incorporation of attention visualization techniques within models like TULIP will enable deeper insights into how these systems interpret input data. This focus on transparency not only improves model performance but also builds trust among users by elucidating decision-making processes inherent in AI operations. Enhanced collaboration between computer vision experts and linguists may further refine these technologies, leading to breakthroughs that redefine human-computer interaction paradigms.

In conclusion, the exploration of visual intelligence through the TULIP model reveals its transformative potential in artificial intelligence. By understanding how visual perception can be enhanced and applied across various domains, we gain insight into the intricate workings of AI systems that mimic human-like understanding. The TULIP framework not only provides a structured approach to developing visual intelligence but also showcases its versatility in real-world applications ranging from healthcare diagnostics to autonomous vehicles. The benefits it offers—such as improved accuracy, efficiency, and decision-making capabilities—are evident in numerous success stories where organizations have harnessed this model for significant advancements. As we look toward future trends, it's clear that integrating frameworks like TULIP will play a crucial role in shaping more intuitive and capable AI systems that can better understand and interact with our world visually. Embracing these innovations will undoubtedly lead us towards a future where machines are equipped with enhanced cognitive abilities akin to those of humans.
FAQs about the TULIP Model in AI
1. What is visual intelligence and why is it important?
Visual intelligence refers to the ability of systems, particularly artificial intelligence (AI), to interpret and understand visual information from the world around them. It is crucial because it enables machines to analyze images, videos, and other visual data effectively, leading to advancements in various fields such as healthcare, security, autonomous vehicles, and more.
2. Can you explain what the TULIP model stands for?
The TULIP model is an acronym that represents a framework used in AI for enhancing visual intelligence. While specific interpretations may vary based on context or application within different organizations or research groups, generally it emphasizes key components necessary for effective image processing and understanding.
3. How can the TULIP model be applied in real-world scenarios?
The TULIP model can be applied across numerous sectors including healthcare (for medical imaging analysis), retail (for customer behavior analysis through video surveillance), agriculture (for crop monitoring using drones), and smart cities (enhancing traffic management with real-time video feeds). Each application leverages its capabilities to improve decision-making processes.
4. What are some benefits of utilizing the TULIP framework in AI projects?
Utilizing the TULIP framework provides several benefits including improved accuracy in image recognition tasks, enhanced efficiency by streamlining workflows related to visual data processing, better integration with existing technologies due to its modular design, and fostering innovation by enabling new applications of AI technology.
5. What future trends should we expect regarding visual intelligence powered by models like TULIP?
Future trends indicate that advancements will continue towards greater automation of visual tasks through deep learning techniques integrated into frameworks like TULIP. We may also see increased personalization in applications driven by user-specific data insights as well as enhancements in ethical considerations surrounding privacy when deploying these technologies across various industries.







