














![Apple to Craft Key Foldable iPhone Components From Liquid Metal [Kuo]](https://www.iclarified.com/images/news/96784/96784/96784-640.jpg)

![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)












































































































_Federico_Caputo_Alamy.jpg?#)
































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)



















































































































![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)

































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





.png?#)













































Where to Start in Web Development: Ignoring learning HTTP(S), URLs, DNS, IP, SSL will have consequences...
This is the second article in a series on Web Development. If you’re just starting out, I highly recommend reading the first part first. In that part I illustrated and explained the DOM (Document Object Model); in this article, I’ll use the term DOM assuming you’re already familiar with it. This isn’t my first article on networking. From my profile stats, I’ve noticed that topics around networking get few readers, so I can guess that now you might be thinking, "I can skip this for now—I don’t really need it for starting with web dev". Well, here’s what I believe might happen on your web development learning path if you postpone learning the things listed in the title: CRUD Applications, the Database part will be pretty tough. Improper database client configuration, struggle with setting up secure connections and handling data flows properly. HTML Forms & HTTP methods mess-ups Sensitive data unintentionally spawning in URL because of GET method in form tag? Plus, in general, handling user inputs may be confusing. Try/Catch Blocks in JS fetch functions When you fetch data using JS, you’re dealing with network requests and responses. If you do not understand how those work, you will be confused by what you’re actually catching in an error. Debugging fetching functions Without understanding HTTP language or the request-response cycle, you will spend extra time trying to understand why your frontend does not display what it should. Let's not mention the situationships when some try to fetch something from remote servers pointing to the localhost. Hosting your web apps (portfolio, pet projects, etc.) Eventually, you’ll want to put your work online. Without networking fundamentals, you might not know even where to start. Routing in your web apps If you don’t understand how URLs translate into requests and how servers respond, you might struggle with design of your app's routing schemes. APIs Web development revolves around APIs. APIs are mostly about communication via network. Dockerizing your apps I noticed the urge to containerize anything that is not yet containerized even on early stages of development, but containerization involves such things as port mappings, virtual networking etc. You might also struggle with linking containers together or exposing your app's parts properly. I hope I have convinced you somehow to invest your time in learning networking fundamentals. In the previous part’s conclusion, I showed this scheme visualizing on high level how browsers work: As you can see in that diagram, the "query" from the browser’s address bar plays a key role: by using that "query", your browser’s networking layer sends a request and receives a response from the correct server. That response contains some data (for example, .html, .css, and .js files) that gets rendered—based on these files the Document Object Model is constructed by the browser—and then visualized. In this article, I’ll focus on what’s happening in the browser’s networking layer and also explain what servers are and what role they play (Spoiler: "server" is not always about a backend!). Here is the roadmap: Browser's Address Bar URIs and URLs HTTP Protocol Internet Protocol and IP addresses Transmission Control Protocol (TCP) TCP/HTTP Network traffic Understanding Ports DNS TCP in action: 3-way handshake HTTPS Little extra info: multiple IP addresses and horizontal scaling of web apps About encryption TLS/SSL certificates Secure communication channel 1. Browser's Address Bar Modern browsers are quite powerful, and you might not even notice that when you type something in the address bar, you’re effectively using it like a search engine (default search engine of your browser). You can drop in any text, and the browser takes that text and forwards it to your default search engine—all without you really realizing. But if you’ve been using browsers and the internet for a long time, you might remember it wasn’t always like this. You couldn’t just throw any random text into the search bar and expect the browser to figure it out. Back then, you had to first go to the search engine’s website (e.g., Google or Bing) and then type your search query there. For demonstration purposes, I’ll use a silly "query". My browser is Brave, and its default search engine is Brave Search. I type this into the search bar: difference between .com and .dev. This is what I see: What if I type the same "query" without spaces, and even worse, with dots between words - difference.between.comand.dev? It can happen—maybe you’ve done it when typing quickly on your phone and missed the spaces. Such "query" results in: Error example: DNS address could not be resolved Jump back to DNS section So here comes the error: the browser definitely did not process both queries the same way. The first query was treated as a string that got passed to the search engine, but the second query (with dots) made th

This is the second article in a series on Web Development. If you’re just starting out, I highly recommend reading the first part first. In that part I illustrated and explained the DOM (Document Object Model); in this article, I’ll use the term DOM assuming you’re already familiar with it.
This isn’t my first article on networking. From my profile stats, I’ve noticed that topics around networking get few readers, so I can guess that now you might be thinking, "I can skip this for now—I don’t really need it for starting with web dev". Well, here’s what I believe might happen on your web development learning path if you postpone learning the things listed in the title:
-
CRUD Applications, the Database part will be pretty tough.
Improper database client configuration, struggle with setting up secure connections and handling data flows properly.
-
HTML Forms & HTTP methods mess-ups
Sensitive data unintentionally spawning in URL because of GET method in form tag? Plus, in general, handling user inputs may be confusing.
-
Try/Catch Blocks in JS fetch functions
When you fetch data using JS, you’re dealing with network requests and responses. If you do not understand how those work, you will be confused by what you’re actually catching in an error.
-
Debugging fetching functions
Without understanding HTTP language or the request-response cycle, you will spend extra time trying to understand why your frontend does not display what it should. Let's not mention the situationships when some try to fetch something from remote servers pointing to the
localhost. -
Hosting your web apps (portfolio, pet projects, etc.)
Eventually, you’ll want to put your work online. Without networking fundamentals, you might not know even where to start.
-
Routing in your web apps
If you don’t understand how URLs translate into requests and how servers respond, you might struggle with design of your app's routing schemes.
-
APIs
Web development revolves around APIs. APIs are mostly about communication via network.
-
Dockerizing your apps
I noticed the urge to containerize anything that is not yet containerized even on early stages of development, but containerization involves such things as port mappings, virtual networking etc. You might also struggle with linking containers together or exposing your app's parts properly.
I hope I have convinced you somehow to invest your time in learning networking fundamentals.
In the previous part’s conclusion, I showed this scheme visualizing on high level how browsers work:
As you can see in that diagram, the "query" from the browser’s address bar plays a key role: by using that "query", your browser’s networking layer sends a request and receives a response from the correct server. That response contains some data (for example, .html, .css, and .js files) that gets rendered—based on these files the Document Object Model is constructed by the browser—and then visualized.
In this article, I’ll focus on what’s happening in the browser’s networking layer and also explain what servers are and what role they play (Spoiler: "server" is not always about a backend!).
Here is the roadmap:
- Browser's Address Bar
- URIs and URLs
- HTTP Protocol
- Internet Protocol and IP addresses
- Transmission Control Protocol (TCP)
- TCP/HTTP Network traffic
- Understanding Ports
- DNS
- TCP in action: 3-way handshake
- HTTPS
- Little extra info: multiple IP addresses and horizontal scaling of web apps
- About encryption
- TLS/SSL certificates
- Secure communication channel
1. Browser's Address Bar
Modern browsers are quite powerful, and you might not even notice that when you type something in the address bar, you’re effectively using it like a search engine (default search engine of your browser). You can drop in any text, and the browser takes that text and forwards it to your default search engine—all without you really realizing.
But if you’ve been using browsers and the internet for a long time, you might remember it wasn’t always like this. You couldn’t just throw any random text into the search bar and expect the browser to figure it out. Back then, you had to first go to the search engine’s website (e.g., Google or Bing) and then type your search query there.
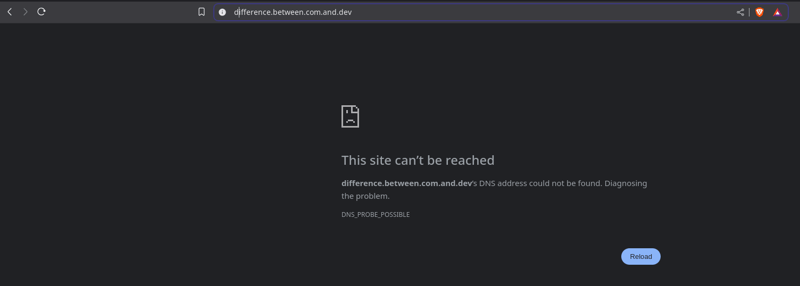
For demonstration purposes, I’ll use a silly "query". My browser is Brave, and its default search engine is Brave Search. I type this into the search bar: difference between .com and .dev. This is what I see:

What if I type the same "query" without spaces, and even worse, with dots between words - difference.between.comand.dev? It can happen—maybe you’ve done it when typing quickly on your phone and missed the spaces. Such "query" results in:
Error example: DNS address could not be resolved
 Jump back to DNS section
Jump back to DNS section
So here comes the error: the browser definitely did not process both queries the same way. The first query was treated as a string that got passed to the search engine, but the second query (with dots) made the browser do something else instead of just processing it along as a search query.
If I double-click on the search bar in both cases, here’s what I see:
-
https://differencebetween.com.and.dev/— which leads to an error page https://search.brave.com/search?q=difference+between+.com+and+.dev&source=desktop&summary=1&conversation=1dd960092fc9678fb88e64
Those are the "queries" the browser processed. I keep putting "query" in quotes (" ") because the technically correct term is a URI, and the actual "query" part is:
?q=difference+between+.com+and+.dev&source=desktop&summary=1&conversation=1dd960092fc9678fb88e64. That’s part of what I typed into the browser’s search bar. Let’s start with what a URI is.
2. URIs and URLs
Uniform Resource Identifiers (URI) are used to identify "resources" on the web. URIs are commonly used as targets of HTTP requests, in which case the URI represents a location for a physical resource, such as a document, a photo, binary data.
The most common type of URI is a Uniform Resource Locator (URL), which is known as the web address.
A Uniform Resource Name (URN) is a URI that identifies a resource by name in a particular namespace. (MDN web docs: URIs)
A URL (Uniform Resource Locator) is renown term not only by developers but also by just users. The point is that a URL ∈ URI (is a subset of), meaning a URI is broader (every URL is a URI, but not every URI is a URL). A URL is a specific type of URI that not only identifies a resource but also provides the information needed to retrieve it (such as its network location and protocol).
In the previous article, I gave examples of opening files from my PC using this URI:
file:///home/lalala/Projects/DEVTO/webdev/randomPDF.pdf
This is a URI, but not exactly a URL—it’s a bit ambiguous because it could be called a URL if you consider it a locator for a file resource. However, it is common to use “file URI” to emphasize that it accesses a local file rather than a resource over HTTP/HTTPS.
By contrast,
https://search.brave.com/search?q=difference+between+.com+and+.dev&source=desktop&summary=1&conversation=1dd960092fc9678fb88e64
is definitely both a URI and a URL.
First, I want to "decompose" one illustrative URL - http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument to demonstrate all its functional parts, which can help in understanding how it works—this is a key moment:
_1.
http://is the scheme of the URL, indicating which protocol the browser must use
www.example.comis the host name of the URI, indicating which Web server is being requested. Here, we use a domain name. It is also possible to directly use an IP address, but because it is less convenient, it is rare to do so, unless the server doesn't have a registered domain name:80is the port of the URL, indicating the technical "gate" used to access the resources on the web server. It is usually omitted if the web server uses the standard ports of the HTTP protocol (80for HTTP and443for HTTPS) to grant access to its resources. Otherwise, it is mandatory./path/to/myfile.htmlis the path of the URL, indicating the location of the resource on the web server. In the early days of the Web, this was an actual directory path to a physical location on the web server. Nowadays, web servers usually abstract this to an arbitrary location.?key1=value1&key2=value2is the query of the URL, which are extra parameters provided to the web server. The parameters are a list of key/value pairs prefixed by the ? symbol, and separated with the & symbol. These can be used to provide additional context about the resource being requested._
Let's detangle it all one by one. I'm starting with the protocol.
In a URL, anything before :// is a protocol. When I was opening local files from my PC, I used the file:// protocol to access them. However, the most common and widespread protocol—and the one you'll 100% be dealing with—is HTTP(S). So it makes sense to explain it.
3. HTTP Protocol
HTTP: Hypertext Transfer Protocol (HTTP) is an application protocol that defines a language for clients and servers to speak to each other. This is like the language you use to order your goods. (MDN web docs: How the web works)
The browser acts a client, and it communicates with servers using the HTTP language (If it is indicated in the URL, i.e. when it starts with http(s)://). This language per se is a language of verbs—actions with self-explanatory names like GET, PUT, DELETE, POST, TRACE, and others. The browser sends one of these verbs to an address indicated in the URL (URL addresses I will cover later), and if that address is "valid", the server found on this address sends a response.
I want to clarify that, in this article, a server is simply a computational device—like the PC or notebook you’re using, but without a monitor or GUI. For simplicity, just think of it that way for now.
When (if) the server responds to the browser’s request, it does so using HTTP, as it was contacted via this protocol. If the request sent by browser got rejected by server for any reason, HTTP ensures that a client (browser) anyway receives a response. That’s very important (for your JS try catch blocks :D). HTTP responses are more complex than requests (verbs) — the status codes are a crucial part of any HTTP response.
_HTTP response status codes indicate whether a specific HTTP request has been successfully completed. Responses are grouped in five classes:
- Informational responses (100 – 199)
- Successful responses (200 – 299)
- Redirection messages (300 – 399)
- Client error responses (400 – 499)
- Server error responses (500 – 599) (MDN web docs: URIs)_
Now, let me show you some nerd fun that will help you to understand in deep how HTTP protocol works. Of course you can learn all the status codes, methods of HTTP language, but I think it is not enough if HTTP protocol remains a block box for you, especially when it comes to the debugging of your web apps.
The difficulty in understanding networking concepts is because it's kinda all happening under the hood – you don't see any of the communication statuses or responses in the raw format, until you get an error. This is true if you're a user; but if you're a dev, you will be intact even more with networking stuff. However, even if you're a dev and were avoiding networking by all means, I'll show you what's inside this black box.
Let's start with the fact that the HTTP protocol sits on top of another protocol, TCP.
The Transmission Control Protocol (TCP) is one of the main protocols of the Internet protocol suite. It originated in the initial network implementation in which it complemented the Internet Protocol (IP). Therefore, the entire suite is commonly referred to as TCP/IP. TCP provides reliable, ordered, and error-checked delivery of a stream of octets (bytes) between applications running on hosts communicating via an IP network (Wikipedia:TCP)
Here is the chain of protocols:
HTTP Protocol <-- TCP Protocol <-- IP Protocol
Let's start from the bottom up.
3.1 Internet Protocol and IP addresses
IP (Internet Protocol) has the task of delivering packets from the source host to the destination host solely based on the IP addresses in the packet headers. For this purpose, IP defines packet structures that encapsulate the data to be delivered. It also defines addressing methods that are used to label the datagram with source and destination information (Wikipedia:IP).
IP may be quite familiar to you, especially when it comes to the term "IP address". The device from which you're reading this article has an IP address, and my PC, from which I'm writing this article, also has an IP address. DEV.TO, as a portal, has an IP address as well. Even though your device and my PC do not communicate directly, both our devices are communicating with DEV.TO.
There are actually two versions of the IP protocol: IPv4 and IPv6. As stated in the Wikipedia quote above, the IP protocol is about communication between the source and destination.
Try to think of packets of data as envelopes with some info—Internet Protocol is mostly about the structure of addresses. Each envelope with a letter (data) inside has a to (destination) and a from (source).
Now, what about IP versions? Let's say that we lived in the old days when people resided in houses rather than apartments (one house=one household). The addressing system was quite different—just the street name, house number, city, and country. That system worked fine. But then, as time went on, globalization and urbanization began, and more people started living in cities. It can't be that only one family lives in a huge house, so houses started to be divided into apartments (one house=many households). Now, if a letter arrives with just the street, city, country, and house number, it will not find the correct Destinee. A new "addressing" mechanism had to be invented.

That's exactly what happened with IPv4 (Internet Protocol version 4). It was created when the Internet was a far less "global"—few had access to it—and it worked fine. But look at us in 2025: each of us usually has at least two devices that need to be connected to the Internet, and many of us don't live alone but with family, so the numbers multiply. Here’s the thing: IPv4 addresses are mathematically limited—the number of unique addresses available is around 4 billion. If you calculate only for private use and individuals, it is misleading because think also about all big companies with many servers that use unique IP addresses if they're connected to the global Internet.
So, a newer version of IP was born—IPv6 (Internet Protocol version 6). This version of the protocol completely changes the address structure and syntax, providing an enormous pool of unique addresses so that every server, every personal device can have its own unique address.
The problem is that IPv6 has not yet been widely adopted, and most of the Internet is still on IPv4.
So you may think there's a problem: network packets (the envelopes from the analogy above) are getting lost, because the addresses are "duplicated"... but that's not true. Various mechanisms somehow solve the issue of IPv4 addresses scarcity, and the core mechanism is NAT—Network Address Translation. I won't go into detail here, but if you genuinely want to advance your understandings in networking, you can read my other articles on networking: this, and this.
In the scope of this article, I just want to explain the key point of how NAT affects your devices and any web app you will ever develop and host. Your devices don't have unique IPv4 addresses when connecting to the internet. Firstly, you never connect directly to the internet from your devices unless you have a device directly attached to a fiber cable connected in a wired way to the global net. Yes, if you think the global internet is wireless, you're mistaken. The global internet is entirely wired, except for the internet provided by satellites. So, how do you access the internet from your devices? Mostly wirelessly, I imagine—you connect to a Wi-Fi router. And if you've ever handled internet provision at your home, you might have seen the operator arrive at your house with a thin cable, your to be Wi-Fi router and connecting it with a wire! Another alternative is using a SIM card in your router or mobile phone, which receives signals "wirelessly".
While cellular towers broadcast wireless signals to phones, themselves they rely on a wired or high-capacity link to connect to the rest of the carrier’s network. In the case of Wi-Fi routers, fiber cable is physically brought to your internet provider's establishment, which is connected by cable—first to the city, then to the country, and then to the rest of the world.
Anyway, that was just FYI. What's important for web development is this: at your home setup your Wi-Fi router has a unique IPv4 address*. (* stands for the fact that first, most probably, this unique ipv4 address is not as long lasting as the classical physical address of a building - it is constantly changing - usually much more than once a day; second, there is such a thing as CGNAT and I leave it for you to check what is it). Your devices connected to Wi-Fi router don't have unique IPv4 addresses each. If you check your PC's IP address, you'll see something like 192.168.x.x.
I see this this:
(If you're on Mac or Windows, check the web on how to find your IP address information.)
$ ip a
1: lo: mtu 65536 ....
...
inet 127.0.0.1/8 scope host lo
...
2: eno1: mtu 1500 ...
...
inet 192.168.8.9/24 brd 192.168.8.255
...
There are two things you see in my output: lo and eno1: 192.168.8.9
eno1 is the network interface—or the point of connection for my PC. It's the Ethernet cable connected to my Wi-Fi router, and that's its address. What is lo? It's the loopback interface. You probably know it well—it's the famous localhost - 127.0.0.1.
My Wi-Fi router has a public IPv4 address. Also, it is creating a local network (my home network; LAN - local area network) that spans as long as the signals of my router reach. Any device that can connect to my Wi-Fi router becomes a part of this network. This network is a default private network, and it uses IP addresses reserved for private usage. So, my PC has the IPv4 address 192.168.8.9, my phone - 192.168.8.10, my laptop - 192.168.8.5 and so on. This default local network can accommodate up to 254 devices simultaneously connected to my router. With the NAT mechanism, my Wi-Fi router translates all the requests and -responses sent to global net from each device connected to it, granting them access to the internet (e.g request: I go to google from my PC to find a picture of kitty and then I download it).
So, how is this all related to web dev?
- You cannot directly host anything you develop on a private IP address if you want to expose it to the global net.
- Anything!!! Absolutely anything you see on the web—any page you manage to open, any existing services, anything at all—resides/is stored on a "device" with an IP address.
- Whatever you visit on the web from a browser: A. exposes your external (e.g the router’s public IP) IP address (little remark: VPNs and proxies can mask your IP :-)) B. exposes its IP address to your browser.
- The alfa-numerical part following
http(s)://in a URL (roughly speaking, "the name" of a website) can be presented as an IP - e.g you can generally replacehttp(s)://example.comwithhttp(s)://and access the site that way, however, some sites have domain-specific configurations, so entering an IP might not always load the intended site, but the point is that a domain name ultimately resolves to an IP (on domains later on!!).
Okay, basta with IP. I introduced key information about IP addresses:

Next up: TCP.
3.2 Transmission Control Protocol (TCP)
In my analogy with envelopes and letters, the Transmission Control Protocol plays the role of a delivery service. Thanks to IP, envelopes (network packets with data) have a standardized addressing system, so if they're delivered responsibly, the data will arrive from sender to recipient. This is where TCP comes into picture: its job is to deliver envelopes (network packets with data) in a reliable way, ensuring they reach their destination.
TCP isn’t the only protocol on top of IP. There’s also UDP (User Datagram Protocol), but I’ll leave it aside for now. This meme fits well to explain the difference:

Anyway, since HTTP sits on top of TCP, let’s concentrate on TCP rather than on other protocols.
To illustrate TCP in action, as well as HTTP and HTTPS, I’ll share the results of some network packets capturing. By the way, continuing my envelope analogy: the HTTP protocol is like the language of the letter (data) inside the envelope (network packets). The sender writes the letter in a language, and the recipient responds in the same language.
When a letter (data) is sent in the HTTP "language", anyone nosy who intercepts the envelope can open it and read the letter (data) clearly, because it’s not encrypted. But if the letter (data) is written in HTTPS "language", this nosy someone will only see some general information and then abracadabra instead of the actual content.
HTTPS is a secure version of HTTP that stops bad people from reading your data while it is being transported. On the modern web, pretty much every server uses HTTPS, so if you don't include it explicitly, the browser assumes that is what you are using and adds it for you.
Anyway, I promised some nerd fun, and by that, I mean that I will capture network packets that travelling in and out of my PC to show you what is inside.
3.3 TCP/HTTP Network traffic
For HTTP network traffic, I’ll use this site: http://httpforever.com/.
For HTTPS traffic, I’ll use the URL of my DEV.TO profile as an example: https://dev.to/dev-charodeyka.
The tool I’ll use to capture network packets is Wireshark (it has a GUI). I could do the same with tcpdump, but for demonstration purposes, I want something visual.
I’ll also be using a software called curl:
curl - transfer a URL
curl is a tool for transferring data from or to a server. It supports HTTP and HTTPS protocols.
In this setup, curl will act as the client in the typical client–server relationship. In web dev a browser is usually the client in such a setup. The command I’ll use is curl with a verbosity flag (-v), so I can show you all the details.
Curl output
$ curl -v http://httpforever.com/
* Host httpforever.com:80 was resolved.
* IPv6: 2604:a880:4:1d0::1f1:2000
* IPv4: 146.190.62.39
* Trying [2604:a880:4:1d0::1f1:2000]:80...
* Immediate connect fail for 2604:a880:4:1d0::1f1:2000: Network is unreachable
* Trying 146.190.62.39:80...
* Connected to httpforever.com (146.190.62.39) port 80
* using HTTP/1.x
> GET / HTTP/1.1
> Host: httpforever.com
> User-Agent: curl/8.12.1
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 200 OK
< Server: nginx/1.18.0 (Ubuntu)
< Date: Mon, 17 Mar 2025 21:00:08 GMT
< Content-Type: text/html
< Content-Length: 5124
< Connection: keep-alive
< Referrer-Policy: strict-origin-when-cross-origin
< X-Content-Type-Options: nosniff
...
<
....
Back to explanation
Hear me out! What you’re seeing is exactly the same thing that happens under the hood when I visit this website from my browser. It might be confusing—like, how can the website (the "front end") also be about servers?
Well, that confusion arises because there’s a common understanding that "frontend" refers to something to be run in a browser (client-facing), and "backend" is the stuff on servers. But actually... everything runs on servers. Hard-to-swallow pill: if you want to self-host your future web apps and avoid paying for web hosting or PaaS, welcome to servers and the Linux world.
The backend and frontend parts of a web app can reside on the same physical machine (or the same cloud instance). However, on the software level, they are separated. Frontend is running on web servers (software, "server" comes from the fact that this software is serving something).
This line from curl output shows which web server the http://httpforever.com/’s frontend is running on:
< Server: nginx/1.18.0 (Ubuntu)
The physical server has Ubuntu OS and is running the Nginx. Physical server's IP is:
* IPv4: 146.190.62.39
default HTTP port is 80 so we see this:
* Trying 146.190.62.39:80...
3.4 Understanding Ports
Now, about ports (:80), even if it’s outside the main scope of this article, I’ll explain with an analogy so you understand what a port is.
Imagine you have a house. To enter, you have a door. If you remove the door, you can’t enter the house. If you don’t know where the door is, you also can’t get in. Let’s expand on that: maybe you have a door for you and your family, a little door for your cat, and a big door on the ground floor for your car. If you try to drive your car through the cat door, it won’t work, and if the cat goes through the garage door, it ends up somewhere it doesn’t need to be.

It’s the same concept with ports. HTTPS traffic uses port 443, and HTTP uses port 80 by default. You may face the need to open other ports on your PC/server, as many services have their own default ports—like databases. All these ports need to be open if you want external access for a given service. And it’s also about what requests or messages you’re pushing through a port. Returning to my analogy: the cat enters the house through its little door looking for food. If it walked into the garage, it wouldn’t find its feeder. Same idea with software. For example, Mongo DataBase’s default port is 27017. If you try to send curl requests there expecting an HTTP response, it won’t work, because MongoDB can’t respond in that way.
Before I move on to the same command for an HTTPS site, I want to explain the first line of the curl output:
Host httpforever.com:80 was resolved.
3.5 DNS
You can have a look again on the error that I encountered when I dropped in the browser's search bar an erroneous URL: https://differencebetween.com.and.dev/ DNS error
Basically, the browser displayed an error because I was trying to reach an abracadabra web address, differencebetween.com.and.dev, using the https protocol. The browser couldn’t find a server at that "address" because it simply doesn’t exist. But how did the browser figure that out? Where did the browser "look up" that "address"? Does your browser have some kind of "address book" containing all the existing "addresses" on the web? Of course not. Every browser indeed checks an "address book" of the entire Internet, but it does so via the network – it doesn’t store it locally.
Before I give a name to this "address book of the Internet", I want to explain what is in this book, gracefully connecting all the pieces of information I shared above. However, I guess you can already guess what a browser needs to find a server... an IP address, of course! Take another look at the curl output:
* Host httpforever.com:80 was resolved.
* IPv6: 2604:a880:4:1d0::1f1:2000
* IPv4: 146.190.62.39
* Trying [2604:a880:4:1d0::1f1:2000]:80...
* Immediate connect fail for 2604:a880:4:1d0::1f1:2000: Network is unreachable
* Trying 146.190.62.39:80...
* Connected to httpforever.com (146.190.62.39) port 80
First thing that happened after curl request was sent to http://httpforever.com was that this web address was resolved. Resolved de-facto means that the client (curl in this case, though the same is completely true for browsers) received the information that httpforever.com == 146.190.62.39 (IPv4) and httpforever.com == 2604:a880:4:1d0::1f1:2000 (IPv6). The browser immediately tried to send the HTTP request to the first IP it found, which was the IPv6 address. But as I mentioned, the Internet and many servers are still only on IPv4, so the connection failed... then it quickly started to send the request to the IPv4 address, and the connection was successful!
So, where do browsers get a "dictionary" that maps human-readable addresses to IP addresses? Browsers get it from DNS (Domain Name System).
The Domain Name System (DNS) is the phonebook of the Internet. Humans access information online through domain names, like nytimes.com or espn.com. Web browsers interact through Internet Protocol (IP) addresses. DNS translates domain names to IP addresses so browsers can load Internet resources. (Cloudflare: What is DNS?)
I won’t go into too much detail on DNS, it is simple per se in what it is for, but it is not that simple to configure from the standpoint of networking configuration. Here is the schematic representation on how your browser reaches Domain Name System:
URL example: https://www.cloudflare.com/learning/dns/what-is-dns/
[Browser] --> (Browser's internal DNS cache)
|
v
Found IP of www.cloudflare.com?
| |
No Yes ---> resolved, sending request...
|
v
[Operating System of PC/server] --> (Local DNS cache & configuration)
|
v
Found IP of www.cloudflare.com?
| |
No Yes ---> resolved, sending request...
|
v
[Router/Modem] -->Forwards DNS query
Forwards where? Depends on configuration..
│ OR |
v v
[ External Public DNS [Internet Service Provider's
(e.g. Google, 8.8.8.8)] (ISP) DNS]
| OR |
v v
Found IP of www.cloudflare.com?
| |
No Yes ---> resolved, sending request...
|
v
www.cloudflare.com does not exists.
The key takeaway is that a "human" address in a URL is just for people. Underneath, there’s always an IP address. And as a first step, browsers try to look up the "translation" of the provided address into an IP. If it fails, that’s the end of the query and results in an unavoidable error. Another takeaway is that you can't, just out of the blue, decide that your server with IP 123.124.135.5 (for example) will have a domain name like coolest-site.eu by specifying it in your server’s configurations. I hope that’s pretty obvious.
3.6 TCP in action: 3-way handshake
Anyway, here is the nerd fun!!! Haha, I called it nerd fun because once my colleague told me that I need to have a social life after I mentioned that I observed my home lab's network packets for hours to examine a peculiar network anomaly.
As I mentioned, I use Wireshark for monitoring network traffic on my PC and with this tool I can capture all the network packets that pass through it. If I start capturing everything, the output gets flooded in seconds, because any website I open in my browser ends up in the stats table. Currently, I have my PC connected to only one network, and I will capture packets traveling via this network. I will filter out only the packets for HTTP example site, http://httpforever.com, as I already know the IP after the first launch of curl I can use this network packets filter: ip.addr==146.190.62.39 and tcp.port==80. So I start capturing with an active packet filter in Wireshark, and then I just open http://httpforever.com in my browser.
Here is what I see:
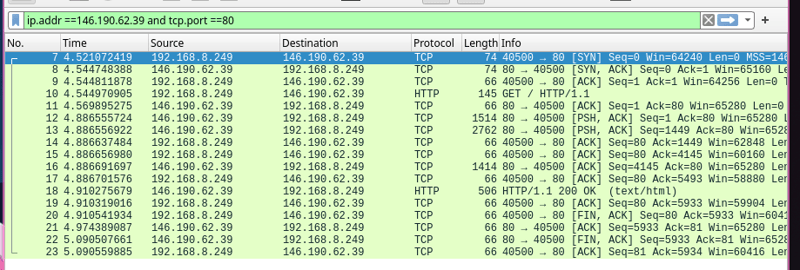
That’s just what happened under the hood for one simple action: I tried to load the landing page of http://httpforever.com.
Let’s decompose it. First, for each network packet (each row in the table above = network packet) there’s the source and destination. The source of the first packet is the private IP address of my PC, as the communication was started by my PC (specifically, by my browser). The destination of the first network packet is the IP of the site http://httpforever.com. In the Info column, as a first thing you see the ports 40500 → 80. Yes, 40500 is the port used on my PC during this communication - it’s an ephemeral port, which is basically a byproduct of NAT applied by my router. The first thing after ports in the first row, column Info (No. 7) you see is the abbreviature SYN — SYN (Synchronize) is the first step in making a handshake, so it’s like extending your hand to someone else to initiate a handshake.
Next, the server where http://httpforever.com's frontend runs, sees the handshake request from my browser and acknowledges it, which is the 2nd step of handshake - SYN-ACK (Synchronize-Acknowledge) (No. 8 line in the table above).
Next, my browser sends an ACK to confirm the server’s SYN-ACK, and that completes the handshake (No. 9 line in the table above). At this point, a reliable connection is established, and data transmission can begin.
As you can see, the row No. 10 in the table informs that the network packet with HTTP GET method request was sent - data exchange between my browser and the server of http://httpforever.com has started -after the handshake, my browser immediately requests what it needs. The server acknowledges the GET request and starts sending data (PSH) (rows No. 11 - 13 in the table above).
Notice there are more than one transfers of different lengths before the line No.18 that contains HTTP response 200 - OK, meaning, that first GET request from my browser was completed. That is because, servers servers over HTTP never send everything requested in one big mega data transfer. For example, if you wanted to download a 10 GB video, the website's server from which you are downloading it wouldn’t just dump the entire file at once—that would overwhelm your network connection. Instead, HTTP network packets are chunked, and the full content is split across those packets. How the data is spitted in network packets by size, is there some rule? There are limits on the server side and on your PC. In fact, without realizing it, you’ve already seen your PC’s limit per network packet if you connect your PC to the Internet via ethernet cable - by default it is 1500 bytes, and this value is called MTU - Maximum Transmission unit. Here is the recap of $ ip a command, output of which contains mtu value:
$ ip a
...
2: eno1: mtu 1500 ...
...
inet 192.168.8.249/24 brd 192.168.8.255
...
Some packets can for some reasons not arrive to client from the first attempt, however, TCP will do its best to ensure the delivery of everything, that's why it is considered as a reliable protocol. And that is why I called it in my analogy with envelopes and letters as a delivery service. 3 way handshakes, and reattempting of sending network packets if something goes wrong.
 Image source; this picture is used to stress out the fact that TCP acts as a "reliable delivery service" for network packets - not just dropping them "by the door", but requiring the "signature" as a confirmation of delivery
Image source; this picture is used to stress out the fact that TCP acts as a "reliable delivery service" for network packets - not just dropping them "by the door", but requiring the "signature" as a confirmation of delivery
NB! the Wireshark output may be a bit not accurate for visualizing how network packets are split up due to the fact that Wireshark takes data segments and reassembles them into the complete application-level message. However, I wanted to demonstrate that network traffic is more complex that it seems and it is segmented.
However, this is very important to know that data travels in chunks when requested—and never gets dumped all in one bulk. It is key for cases when you have to fetch/process huge amounts of data with your JavaScript/TypeScript code (for example, NDJSON). You can take advantage of streaming approaches instead of fetching an entire file at once without streaming and nuking your PC's RAM while trying to process it. Plus, all the "download status bars" are exactly about tracking the chunks of data that arrive and comparing how much is left to the total size of the data being downloaded.
So, I showed you nerd fun with HTTP network traffic - to help you understand how HTTP works, and what happens when you try to open a website from your browser. Now, what's left to discuss is HTTPS.
4. HTTPS
If you look again at the output of a request sent by curl to website via HTTP, the most important part is the last section (which I horribly shortened), but here is the point: after all the info about HTTP communication, there’s actual data in HTML format - all the elements that will be displayed in your browser after it will reconstruct and render DOM based on this html data.
Also, if you look at line No.18 in the Wireshark table from above, you can see that the content type sent over as HTML to my browser was (text/html).
Using Wireshark, I can actually follow each network packet. So, if I select the packet that was carrying the data, I can investigate it—and I see the content in plain text. Here it is:
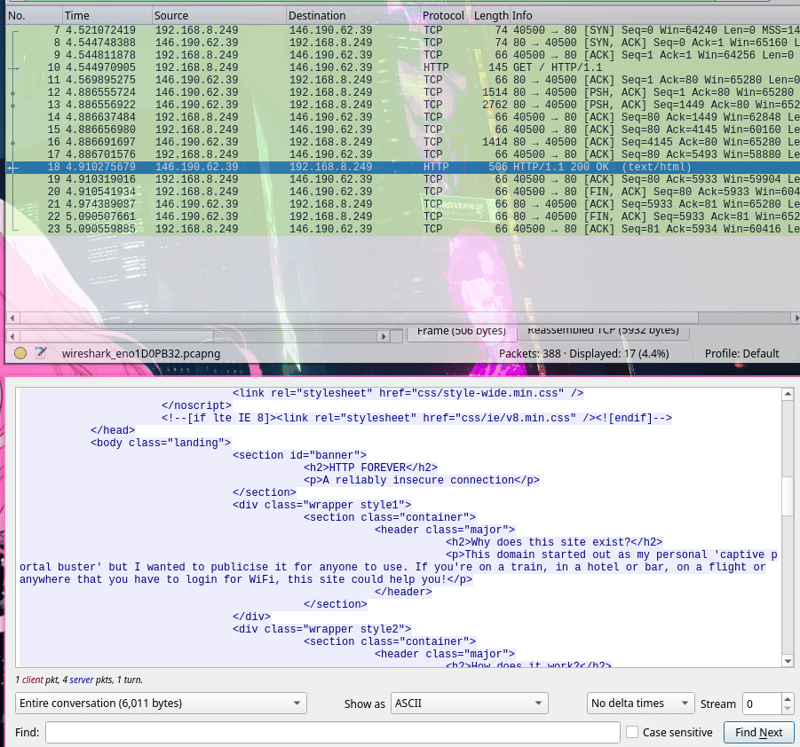
Getting ahead, here’s what I see if I capture network traffic for an HTTPS site: in Wireshark, I start tracking TCP port 443 and the IP of the DEV.TO website, start capturing packets, go to https://dev.to/dev-charodeyka in my browser, identify any packet with data in Wireshark table, and put my nose there, trying to see the data:
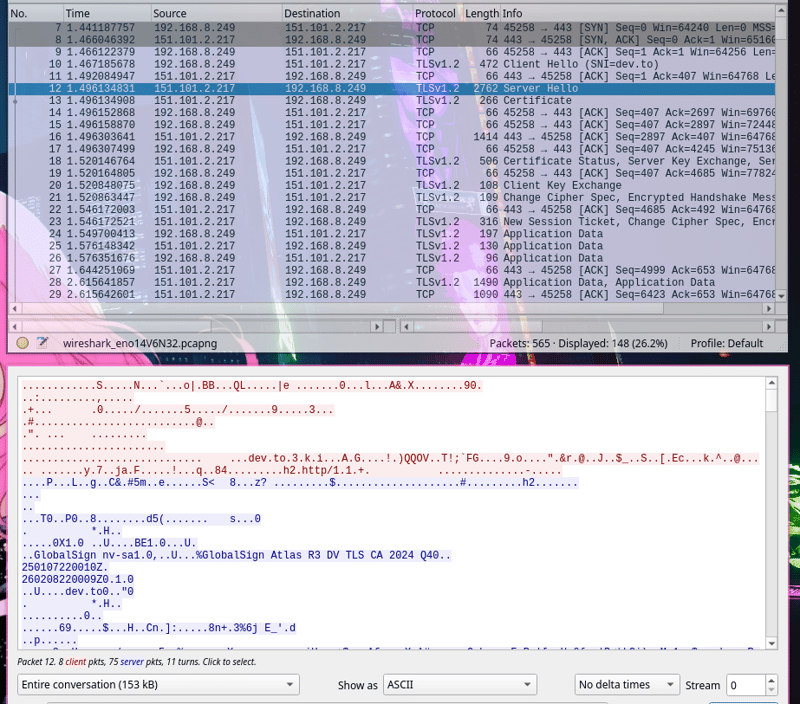
Abracadabra! The real content, html data is hidden. In the process of transfer, data transferred via HTTPS—and not HTTP—is encrypted. So if someone tries to capture it and sniff the content, they won’t understand what it is.
How is that possible? I’ll demonstrate by repeating the same procedure I did for the HTTP website—I’ll send a curl to the HTTPS site - https://dev.to/dev-charodeyka.
$ curl -v https://dev.to/dev-charodeyka
0* Host dev.to:443 was resolved.
* IPv6: (none)
* IPv4: 151.101.66.217, 151.101.2.217, 151.101.194.217, 151.101.130.217
0* Trying 151.101.66.217:443...
* GnuTLS ciphers: NORMAL:-ARCFOUR-128:-CTYPE-ALL:+CTYPE-X509:-VERS-SSL3.0
* ALPN: curl offers h2,http/1.1
* found 152 certificates in /etc/ssl/certs/ca-certificates.crt
* found 456 certificates in /etc/ssl/certs
* SSL connection using TLS1.2 / ECDHE_RSA_CHACHA20_POLY1305
* server certificate verification OK
* server certificate status verification SKIPPED
* common name: dev.to (matched)
* server certificate expiration date OK
* server certificate activation date OK
* certificate public key: RSA
* certificate version: #3
* subject: CN=dev.to
* start date: Tue, 07 Jan 2025 22:00:10 GMT
* expire date: Sun, 08 Feb 2026 22:00:09 GMT
* issuer: C=BE,O=GlobalSign nv-sa,CN=GlobalSign Atlas R3 DV TLS CA 2024 Q4
* ALPN: server accepted h2
* Connected to dev.to (151.101.66.217) port 443
* using HTTP/2
* [HTTP/2] [1] OPENED stream for https://dev.to/dev-charodeyka
* [HTTP/2] [1] [:method: GET]
* [HTTP/2] [1] [:scheme: https]
* [HTTP/2] [1] [:authority: dev.to]
* [HTTP/2] [1] [:path: /dev-charodeyka]
* [HTTP/2] [1] [user-agent: curl/8.12.1]
* [HTTP/2] [1] [accept: */*]
> GET /dev-charodeyka HTTP/2
> Host: dev.to
> User-Agent: curl/8.12.1
> Accept: */*
>
* Request completely sent off
< HTTP/2 200
< server: Cowboy
....
< strict-transport-security: max-age=31557600
< content-length: 145678
<
....
Again, same logic. Now, I hope you can read the output.
First, the dev.to address was resolved into an IP address:
Host dev.to:443 was resolved
* IPv4: 151.101.66.217, 151.101.2.217, 151.101.194.217, 151.101.130.217
However, not one, but many. Why?
4.1 Little extra info: multiple IP addresses horizontal scaling of web apps
Well, I told you networking stuff is cool, and now, dear reader, if you've read this far, you'll also learn about load balancing and horizontal/vertical scaling.
Small web applications that don’t have many visitors can run even on a Raspberry Pi (a tiny PC acting as a server). Indeed, they can even run on something like a phone or any device with limited computational power. However, when a website is pretty well-known - and it's not just a basic blog with zero interactivity, but more like an online shop or DEV.TO - one single server may not be enough to ensure that each user has nice smooth experience browsing it. And it's not only about server hardware specs like super-mega RAM or many many CPU cores; it's also about the network, haha. Network transmission speed does not multiply with number of cpu/ram.
There are two ways of dealing with the hardware resources deficit of a server where web app is running: horizontal and vertical scaling. Let’s say you created a web app and hosted it on a Raspberry Pi. Then you added some cool backend algorithms that do something for your users, so even though you only have a few users, the algorithms demand computational power. You upgrade your Raspberry Pi to something more powerful with more RAM and a better CPU. One important detail is that your website was coolest.site.eu, mapped to the IP 123.124.6.8 - the IP address of that Raspberry Pi. You replace the Raspberry Pi, move your app to the new device, and also bind the SAME IP to the new device. This is vertical scaling.
But what if your web app doesn’t do anything too computationally heavy, yet you have thousands of users accessing it simultaneously? Sure, you could replace your Raspberry Pi with a super-mega server, but that might not be the best use of resources. Instead, you could buy four more Raspberry Pi, duplicate your web app on 3 of them, and thus end up with four different IP addresses—because they can’t all share one IP. Then you’d take 4th Raspberry Pi, install any load balancing software on it (like Nginx), and use it as a "sorter" of requests sent by browsers of your website users when they try to access it. For example, if a thousand users try to reach your website, they won’t all slam into one single Raspberry Pi. Instead, their browsers’ requests land on Load balancer's Raspberry Pi first. It sees how busy each Raspberry Pi is and directs traffic to whichever Pi is least busy at that moment. That’s horizontal scaling, and what load balancer does is balance the load among all available servers.
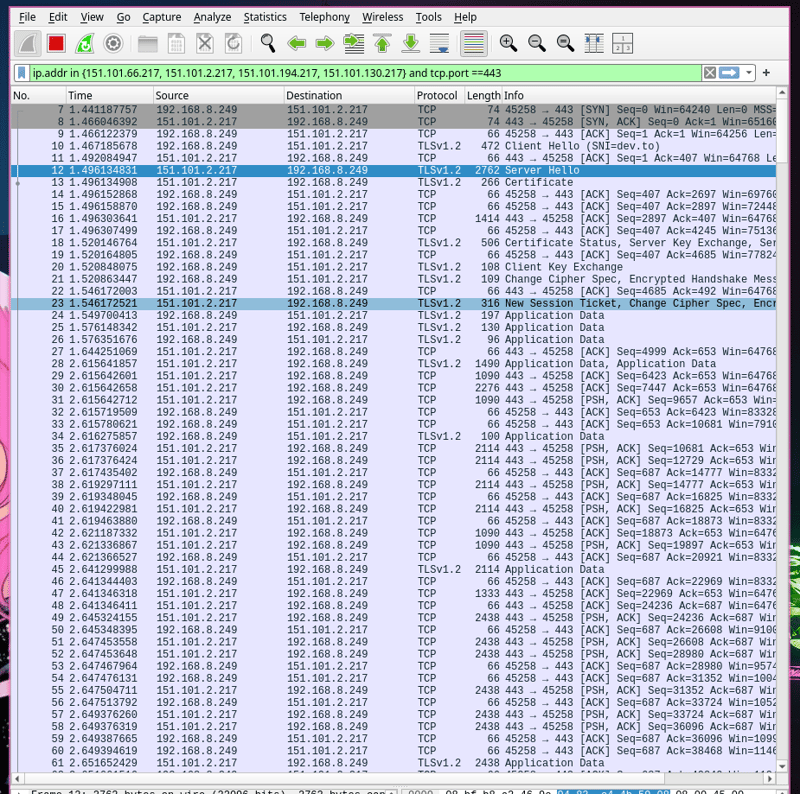
Okay, next. As I mentioned before, HTTPS is the secure version of the HTTP protocol. If you look at the end of the curl output I shared above, once again we see HTML data in plain text—but only after the browser successfully establishes communication with one of dev.to’s servers that hosts the frontend code. That’s why in the Wireshark screenshot, when I tried to put my nose in a HTTPS network packet, I saw weird symbols instead of plain HTML. It’s because the data was encrypted.
4.2 About encryption
If I send you the message 12334 145 672 849, like this, you won’t understand it—unless you know we have a decryption map such as 1=h, 2=e, 3=l, 4=o, 5=w, 6=a, 7=r, 8=y, 9=u, which transforms the message into "hello how are you". You can then respond using the same "encryption key". Of course, this is a very simplified example. In real encryption scenarios, there are usually two keys: public and private.
In my simple example, public key will be containing this info: 1 -> ?, 2 -> ?, 3 -> ?, etc. From public key you only get partial information about encryption—you know how to encrypt the message - turn letters into numbers.
Private key is the secret part that completes the map—only the holder of the private key can reliably invert the numbers into letters.
The public key is indeed public, and it helps a client figure out how data will be encrypted by server. And where is the public key stored when we talk about servers that run websites and exposes them via https protocol? In a small document called a certificate.
Returning to the curl output:
0* Trying 151.101.66.217:443...
* GnuTLS ciphers: NORMAL:-ARCFOUR-128:-CTYPE-ALL:+CTYPE-X509:-VERS-SSL3.0
* ALPN: curl offers h2,http/1.1
* found 152 certificates in /etc/ssl/certs/ca-certificates.crt
* found 456 certificates in /etc/ssl/certs
* SSL connection using TLS1.2 / ECDHE_RSA_CHACHA20_POLY1305
* server certificate verification OK
* server certificate status verification SKIPPED
* common name: dev.to (matched)
* server certificate expiration date OK
* server certificate activation date OK
* certificate public key: RSA
* certificate version: #3
* subject: CN=dev.to
* start date: Tue, 07 Jan 2025 22:00:10 GMT
* expire date: Sun, 08 Feb 2026 22:00:09 GMT
* issuer: C=BE,O=GlobalSign nv-sa,CN=GlobalSign Atlas R3 DV TLS CA 2024 Q4
* ALPN: server accepted h2
* Connected to dev.to (151.101.66.217) port 443
Here, you see a certificate verification step because client (curl, in this case, but the same is for browser) found certificates. Where do they come from, and how does the browser (or curl) verify them?
4.3 TLS/SSL certificates
Well, these certificates were created by dev.to’s server admins. First, two keys were generated on the server: a public and a private key. The certificate includes the server’s public key and some extra data (domain name, organization info, etc.). The dev.to admins sent this certificate to a Certificate Authority (CA) to have it signed. In dev.to’s case, I can see the certificate was signed by CA called GlobalSign:
* issuer: C=BE,O=GlobalSign nv-sa,CN=GlobalSign Atlas R3 DV TLS CA
That CA verified that dev.to actually owns the domain and then issued a signed certificate if everything was legitimate about this server and domain. The signed certificate is sent back to the dev.to server. After this, dev.to's server is equipped with its private key (secret) and its public key that got embedded in the signed certificate (this is not secret). This signed certificate is TLS/SSL certificate
When I try to access https://dev.to/dev-charodeyka via a browser:
I. My browser starts a connection via the Secure Socket Layer (SSL) protocol to the dev.to server:
* SSL connection using TLS1.2 / ECDHE_RSA_CHACHA20_POLY1305
II. The dev.to server sends its signed certificate (which contains the public key) to my browser.
III. My browser verifies the certificate (checks expiration, domain match, CA trust, etc.). You can see that checking process in the output:
* server certificate verification OK
* server certificate status verification SKIPPED
* common name: dev.to (matched)
* server certificate expiration date OK
* server certificate activation date OK
* certificate public key: RSA
* certificate version: #3
* subject: CN=dev.to
* start date: Tue, 07 Jan 2025 22:00:10 GMT
* expire date: Sun, 08 Feb 2026 22:00:09 GMT
* issuer: C=BE,O=GlobalSign nv-sa,CN=GlobalSign Atlas R3 DV TLS CA 2024 Q4
* ALPN: server accepted h2
IV. After the certificate is verified and approved by my browser, the dev.to server and my browser establish a secure channel. Think of it like going into a private room so nobody else can hear what you're discussing with another person. In digital communication, that means all messages are encrypted in such a way that only the sender and recipient can understand them.
4.4 Secure communication channel
To create this secure channel, both my browser and dev.to server need to agree on encryption and decryption keys:
1) They agree on the TLS (Transport Layer Security) version and cipher format:
* SSL connection using TLS1.2 / ECDHE_RSA_CHACHA20_POLY1305
2) The dev.to server and my browser each create "ephemeral" key pairs for this specific session that my browser initialized.
3) They exchange the public parts of these ephemeral keys (encrypted with or signed by the dev.to server’s private key to ensure authenticity).
4) A shared secret (the session key) is computed on both ends - my browser and dev.to server.
Now, my browser and the dev.to server each have the same session key. All the HTML, images, and everything else is encrypted with this session key—and it’s unique to this session.
Finally, once this secure channel is established, my browser sends encrypted HTTP requests and receives encrypted responses (like the HTML code for rendering my dev.to profile).
You can compare all these steps to the earlier HTTP Wireshark table—there, everything was visible in plain text. Under HTTPS, it’s all far not that clear. No one intercepting the packets from "outside" of the secured channel can read the data unless they managed to "steal" a secret key.
Well... I guess that’s all for networking fundamentals in the context of web development. This article got quite long.
The next (and concluding) part of this series will be mostly centered around the backend side of web development and JavaScript, but from a particular perspective - here is a teaser: can you use JavaScript the same you use Python?
Summarizing:
Don’t ignore the networking and servers. Even if you’re aiming to become a CSS/HTML/JS guru who can create amazing UIs, remember that understanding how servers and networking work is crucial. Otherwise, your frontend code could unintentionally breach security and expose sensitive data. Web dev isn’t just about pretty visuals; it’s also about safe and efficient communication between clients and servers.
HTTPS is more complex than HTTP; it’s not simply a "version 2" of HTTP. Developing on HTTP and localhost won’t behave exactly the same as when you switch to HTTPS in production. Secure cookies, CORS, and encrypted data transfers all tax your code once communication passes from HTTP to HTTPS.
Get familiar with how ports work and how to monitor them. You don’t want to open a bazillion ports in your web app by repeatedly opening up database clients or other services each on a new port.
Understanding URLs is vital for setting up routing in your web apps, especially when you deal with protected endpoints that require authorization.
Understanding IP addresses is just basic for any IT field. It will prevent you from sending your friend a URL to evaluate your cool web app that has as address your home network’s 192.168.x.x address.
A privacy-aware bonus that may encourage you to explore in-depth networking and DNS:
If you’re a privacy-obsessed and always use a VPN to surf the web like an untraceable ninja, ensure that DNS queries are never forwarded to your ISP’s DNS server. If they are, you are traceable ninja.