




















![Some T-Mobile customers can track real-time location of other users and random kids without permission [UPDATED]](https://m-cdn.phonearena.com/images/article/169135-two/Some-T-Mobile-customers-can-track-real-time-location-of-other-users-and-random-kids-without-permission-UPDATED.jpg?#)







































![Apple Releases macOS Sequoia 15.5 Beta to Developers [Download]](https://www.iclarified.com/images/news/96915/96915/96915-640.jpg)
![Amazon Makes Last-Minute Bid for TikTok [Report]](https://www.iclarified.com/images/news/96917/96917/96917-640.jpg)
![Apple Releases iOS 18.5 Beta and iPadOS 18.5 Beta [Download]](https://www.iclarified.com/images/news/96907/96907/96907-640.jpg)
![Apple Seeds watchOS 11.5 to Developers [Download]](https://www.iclarified.com/images/news/96909/96909/96909-640.jpg)
















































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)




























































































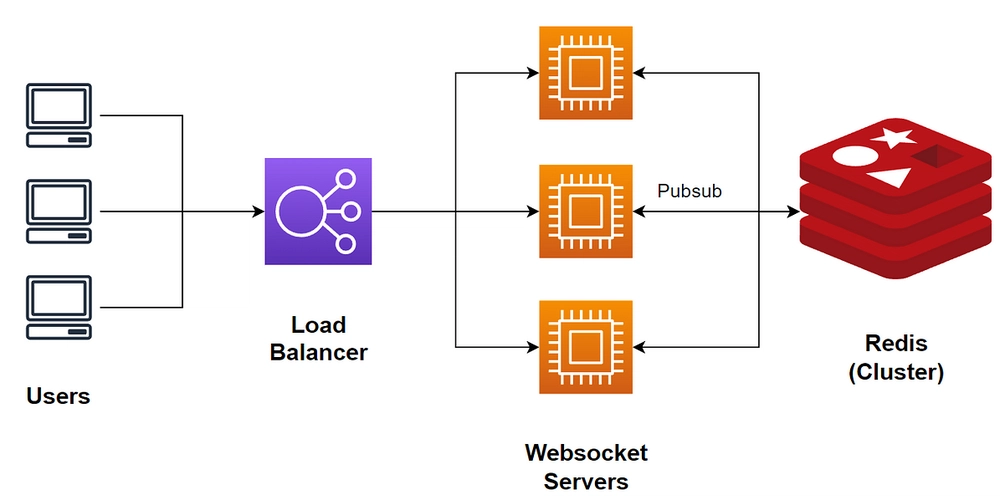























![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)









































































































This AI Paper from ByteDance Introduces a Hybrid Reward System Combining Reasoning Task Verifiers (RTV) and a Generative Reward Model (GenRM) to Mitigate Reward Hacking
Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning LLMs with human values and preferences. Despite introducing non-RL alternatives like DPO, industry-leading models such as ChatGPT/GPT-4, Claude, and Gemini continue to rely on RL algorithms like PPO for policy optimization. Recent research focuses on algorithmic improvements, including eliminating critic models to reduce computational costs, […] The post This AI Paper from ByteDance Introduces a Hybrid Reward System Combining Reasoning Task Verifiers (RTV) and a Generative Reward Model (GenRM) to Mitigate Reward Hacking appeared first on MarkTechPost.

Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning LLMs with human values and preferences. Despite introducing non-RL alternatives like DPO, industry-leading models such as ChatGPT/GPT-4, Claude, and Gemini continue to rely on RL algorithms like PPO for policy optimization. Recent research focuses on algorithmic improvements, including eliminating critic models to reduce computational costs, filtering noisy samples during PPO sampling, and enhancing reward models to mitigate reward hacking problems. However, only a few studies focus on RLHF data construction (i.e., training prompts) and its performance scaling based on these training prompts.
The success of RLHF heavily depends on reward model quality, which faces three challenges: mis-specified reward modeling in representing human preferences, incorrect and ambiguous preferences in training datasets, and poor generalization ability. To address these issues, GenRM was introduced to validate model predictions against ground-truth responses, showing good resistance to reward hacking and gaining adoption in advanced LLMs like DeepSeekV3. Methods like principled data selection that filter overly challenging instances during training and strategic selection methods identify key training prompts to achieve comparable performance with reduced data. Performance scale analysis reveals that RLHF shows superior generalization compared to SFT on novel inputs but significantly reduces output diversity.
Researchers from ByteDance Seed address a critical gap in RLHF research where the role of prompt-data construction and its scalability has received less attention. They explore data-driven bottlenecks that limit RLHF performance scaling, focusing on reward hacking and decreasing response diversity challenges. A hybrid reward system is introduced by combining reasoning task verifiers (RTV) and a generative reward model (GenRM) that shows stronger resistance to reward hacking and enables a more accurate assessment of responses against ground-truth solutions. Moreover, a novel prompt-selection method called Pre-PPO is introduced to identify inherently challenging training prompts less susceptible to reward hacking.

The experimental setup employs two pre-trained language models of different scales: a smaller model with 25B parameters and a larger model with 150B parameters. The training dataset contains one million prompts from diverse domains, including mathematics, coding, instruction-following, creative writing, and logical reasoning. Moreover, the researchers constructed a detailed evaluation framework covering multiple skill areas: logical reasoning, instruction-following, STEM tasks, coding, natural language processing, knowledge, contextual understanding, and out-of-distribution generalization. The evaluation framework includes two versions (V1.0 and V2.0) with overlapping prompts, though V2.0 features more challenging prompts.
The experimental results show that the proposed approach combining Pre-PPO with prioritized mathematical and coding tasks consistently outperforms the baseline method across model sizes and evaluation datasets. The approach shows an improvement of +1.1 over the baseline when evaluated at 100-step intervals using TestSet V1.0. When tested on the more challenging TestSet V2.0, the performance improvement increases to +1.4. The most substantial gains appear in mathematics-intensive and coding tasks, with an improvement of +3.9 points in STEM and +3.2 points in coding. These improvements are attributed to the strategic prioritization of mathematical reasoning and coding tasks during early RLHF training phases.
In conclusion, this paper addresses critical bottlenecks in RLHF data scaling, specifically identifying reward hacking and reduced response diversity as significant challenges. The researchers proposed a combined approach featuring strategic prompt construction and early-stage training prioritization to solve this issue. The method uses RTV and GenRM to combat reward hacking alongside the novel Pre-PPO prompt selection strategy that identifies and prioritizes challenging training prompts. Analysis reveals that RTV supervision shows the strongest resistance to reward hacking, followed by GenRM with ground-truth labels and then the BT Reward Model. The research establishes a foundation for optimizing RLHF data construction and developing more principle methods to reward hacking and model alignment.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.








