


























































![Apple to Source More iPhones From India to Offset China Tariff Costs [Report]](https://www.iclarified.com/images/news/96954/96954/96954-640.jpg)
![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)

































































































.webp?#)
.webp?#)
.webp?#)




_NicoElNino_Alamy.png?#)












































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)






































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)































(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)







.png?#)



















































สร้าง Anomaly Detection Model ด้วย OneClassSVM เเละ Isolation Forest
ในไม่กี่ปีที่ผ่านมาแอปจำนวนมากของเราขับเคลื่อนด้วยข้อมูลมหาศาล หนึ่งในมุมที่สำคัญของการจัดการข้อมูลจำนวนมากเช่นนี้คือ "Anomaly Detection" - กระบวนการที่ช่วยให้เราสามารถระบุค่าผิดปกติ ข้อมูลที่อยู่นอกขอบเขตของความคาดหวังหรือพฤติกรรมที่ผิดปกติ นอกจากนี้อาจนำไปสู่การค้นพบใหม่ๆ ได้ด้วย ในบทความนี้เราจะมาดูการทำ "Anomaly Detection" ด้วย OneClassSVM เเละ Isolation Forest ใน Python ซึ่งเป็นส่วนของ scikit-learn เราจะใช้ Google Colab ในการรัน Code นี้ เราจะใช้ Dataset ตัวอย่างที่ชื่อว่า "Hive17" เอามาจาก Github นี้ ซึ่งเป็นข้อมูลของรังผึ้งโดยตั้งสมมติฐานว่าผึ้งจะรักษาสภาพแวดล้อมภายในรังให้คงที่และน่าอยู่เเละเราจะหาว่ามีช่วงเวลาใดบ้างที่รังผึ้งประสบกับระดับอุณหภูมิและความชื้นที่ผิดปกติโดยเราจะใช้เทคนิคเเรกที่ชื่อว่า OneClassSVM หรือ Isolation Forest เพื่อจะดู Decision Boundary บน Scatter Plot Dataset นี้จะประกอบไปด้วย 1847 เเถว เเต่ละเเถวเเสดงถึงค่าต่างๆที่เกิดขึ้นในเเต่ละชั่วโมง ข้อมูลประกอบด้วย 10 Column นี้: [1] Hour ชั่วโมงที่ทำการวัด [2] DateTime วันที่และเวลาที่ทำการวัด [3] T17 อุณหภูมิภายในรังผึ้ง (องศาเซลเซียส) [4] RH17 ความชื้นสัมพัทธ์ภายในรังผึ้ง (เปอร์เซ็นต์) [5] AT17 อุณหภูมิที่รู้สึกได้ภายในรังผึ้ง (Apparent Temperature, องศาเซลเซียส) [6] Tamb อุณหภูมิภายนอกรังผึ้ง (Ambient Temperature, องศาเซลเซียส) [7] RHamb ความชื้นสัมพัทธ์ภายนอกรังผึ้ง (Ambient Relative Humidity, เปอร์เซ็นต์) [8] ATamb อุณหภูมิที่รู้สึกได้ภายนอกรังผึ้ง (Ambient Apparent Temperature, องศาเซลเซียส) [9] T17-Tamb ผลต่างระหว่างอุณหภูมิภายในรังผึ้งและอุณหภูมิภายนอกรังผึ้ง (องศาเซลเซียส) [10] AT17-ATamb ผลต่างระหว่างอุณหภูมิที่รู้สึกได้ภายในรังผึ้งและอุณหภูมิที่รู้สึกได้ภายนอกรังผึ้ง (องศาเซลเซียส)" ขั้นตอนที่ 1: นำข้อมูล Hive17 เข้า ตัวอย่างข้อมูล โหลดตามนี้ได้เลย import pandas as pd url = "https://raw.githubusercontent.com/Cheukting/anomaly-detection/refs/heads/main/data/Hive17.csv" df = pd.read_csv(url, sep = ";") df = df.dropna() print(df.head()) ตัวอย่างผมที่ได้จากการ run ขั้นตอนที่ 2: เริ่มจาก OneClassSVM เราจะต้องจัดข้อมูลที่จะลองเทียบดู ตอนนี้จะลองเทียบ T17 เเละ RH17 from sklearn.svm import OneClassSVM from sklearn.inspection import DecisionBoundaryDisplay import matplotlib.pyplot as plt X = df[["T17", "RH17"]].values ขั้นตอนที่ 3: สร้างเเละ fit ข้อมูลเข้าไปใน model จะสร้าง variable ชื่อว่า estimator estimator = OneClassSVM().fit(X) ขั้นตอนที่ 4: สร้าง graph เพื่อดู Decision Boundary เราลองสร้าง Graph เพื่อที่จะดู Decision Boundary disp = DecisionBoundaryDisplay.from_estimator( estimator, X, response_method="decision_function", plot_method="contour", xlabel="Temperature", ylabel="Humidity", levels=[0], ) disp.ax_.scatter(X[:, 0], X[:, 1]) plt.show() จาก Graph ที่ได้จะเห็นเลยว่าค่าของ Decision Boundary ไม่ค่อยเข้ากับ Data Point ของพวกเราเลย Decision Boundary ไม่ควรเป็นวงรี เพราะว่า Data Point ของพวกเราเป็นรูปร่างที่ไม่เเน่นอน เราก็เลยจำเป็นที่จะปรับ Parameter ของ model เราให้ดีขึ้นโดยใช้ "nu" เเละ "gamma" หลังจากทดลองหลายครั้ง ก็ได้พบว่าใช้ "nu=0.1, gamma=0.05" ให้ผลที่ดีสุด ขั้นตอนที่ 5: ปรับปรุง estimator = OneClassSVM(nu=0.1, gamma=0.05).fit(X) disp = DecisionBoundaryDisplay.from_estimator( estimator, X, response_method="decision_function", plot_method="contour", xlabel="Temperature", ylabel="Humidity", levels=[0], ) disp.ax_.scatter(X[:, 0], X[:, 1]) plt.show() จะได้เป็น Graph นี้ จากตัวอย่างนี้ เราจะได้ Graph ออกมาที่สามารถดูเเละทำ Anomaly Detection ได้โดยการดูใน Graph Data ที่มีค่าอยู่นอก Decision Boundary จะถือว่าไม่ปกตินี่เอง ขั้นตอนที่ 6: Isolation Forest เราสามารถที่จะทำ Anomaly Detection ได้ในอีกวิธีนึง นั้นคือการใช้ Isolation Forest from sklearn.ensemble import IsolationForest estimator2 = IsolationForest(n_estimators=100).fit(X) เราลองสร้าง Graph อีกรอบ เเต่ใช้ Isolation Forest เเทน disp = DecisionBoundaryDisplay.from_estimator( estimator2, X, response_method="decision_function", plot_method="contour", xlabel="Temperature", ylabel="Humidity", levels=[0], ) disp.ax_.scatter(X[:, 0], X[:, 1]) plt.show() จะได้ Graph นี้ เราก็จะเห็นสองเเนวทางที่มีผลเเตกต่างกัน ทั้งสองวิธีมีผลที่ถูกต้อง ทั้งคู่นำไปใช้เปรียบเทียบเพื่อค้นหา anomalies ได้เลย ตัวอย่างเพิ่มเติม เราจะลองใช้ตัวอย่างอื่นบ้าง จะลองสร้างข้อมูลใหม่ขึ้นมา จะสมมุติ Data ของ Website การขายของ E-Commerce ออกมาที่หนึ่ง ข้อมูลจะออกมาเป็นอย่างนี้: Session Duration,Pages Visited,Items in Cart,Total Purchase Value,Product Views 5,10,2,25.99,15 8,15,1,12.50,22 12,25,5,78.00,35 3,7,0,0.00,9 10,20,3,45.75,28 6,12,1,9.99,18 7,14,2,32.50,20 9,18,4,62.20,25 4,9,0,0.00,11 11,22,3,51.00,30 0.5,1,0,0.00,1 60,5,0,0.00,3 7,50,1,15.00,45 0,0,0,0.00,0 15,28,10,150.00,40 2,3,0,0.00,5 9,16,2,28.75,23 13,26,6,92.10,38 4,8,1,17.99,10 10,19,3,41.50,27 ใน Dataset นี้จะประกอบไปด้วย 20 เเถว เเต่ละเเถวจะเเสดงถึงกิจกรรมของผู้ใช้ใน Session ข้อมูลประกอบไปด้วย 5 Column ดังนี้: [1] Session Duration ระยะเวลาที่ผู้ใช้เข้าชมเว็บไซต์ในหนึ่ง Session (เป็นนาที) [2] Pages Visited จำ
ในไม่กี่ปีที่ผ่านมาแอปจำนวนมากของเราขับเคลื่อนด้วยข้อมูลมหาศาล หนึ่งในมุมที่สำคัญของการจัดการข้อมูลจำนวนมากเช่นนี้คือ "Anomaly Detection" - กระบวนการที่ช่วยให้เราสามารถระบุค่าผิดปกติ ข้อมูลที่อยู่นอกขอบเขตของความคาดหวังหรือพฤติกรรมที่ผิดปกติ นอกจากนี้อาจนำไปสู่การค้นพบใหม่ๆ ได้ด้วย
ในบทความนี้เราจะมาดูการทำ "Anomaly Detection" ด้วย OneClassSVM เเละ Isolation Forest ใน Python ซึ่งเป็นส่วนของ scikit-learn เราจะใช้ Google Colab ในการรัน Code นี้
เราจะใช้ Dataset ตัวอย่างที่ชื่อว่า "Hive17" เอามาจาก Github นี้ ซึ่งเป็นข้อมูลของรังผึ้งโดยตั้งสมมติฐานว่าผึ้งจะรักษาสภาพแวดล้อมภายในรังให้คงที่และน่าอยู่เเละเราจะหาว่ามีช่วงเวลาใดบ้างที่รังผึ้งประสบกับระดับอุณหภูมิและความชื้นที่ผิดปกติโดยเราจะใช้เทคนิคเเรกที่ชื่อว่า OneClassSVM หรือ Isolation Forest เพื่อจะดู Decision Boundary บน Scatter Plot
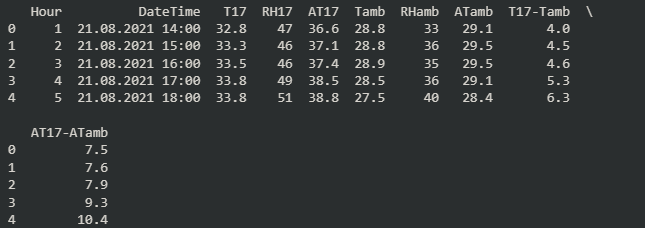
Dataset นี้จะประกอบไปด้วย 1847 เเถว เเต่ละเเถวเเสดงถึงค่าต่างๆที่เกิดขึ้นในเเต่ละชั่วโมง
ข้อมูลประกอบด้วย 10 Column นี้:
[1] Hour ชั่วโมงที่ทำการวัด
[2] DateTime วันที่และเวลาที่ทำการวัด
[3] T17 อุณหภูมิภายในรังผึ้ง (องศาเซลเซียส)
[4] RH17 ความชื้นสัมพัทธ์ภายในรังผึ้ง (เปอร์เซ็นต์)
[5] AT17 อุณหภูมิที่รู้สึกได้ภายในรังผึ้ง (Apparent Temperature, องศาเซลเซียส)
[6] Tamb อุณหภูมิภายนอกรังผึ้ง (Ambient Temperature, องศาเซลเซียส)
[7] RHamb ความชื้นสัมพัทธ์ภายนอกรังผึ้ง (Ambient Relative Humidity, เปอร์เซ็นต์)
[8] ATamb อุณหภูมิที่รู้สึกได้ภายนอกรังผึ้ง (Ambient Apparent Temperature, องศาเซลเซียส)
[9] T17-Tamb ผลต่างระหว่างอุณหภูมิภายในรังผึ้งและอุณหภูมิภายนอกรังผึ้ง (องศาเซลเซียส)
[10] AT17-ATamb ผลต่างระหว่างอุณหภูมิที่รู้สึกได้ภายในรังผึ้งและอุณหภูมิที่รู้สึกได้ภายนอกรังผึ้ง (องศาเซลเซียส)"
ขั้นตอนที่ 1: นำข้อมูล Hive17 เข้า
ตัวอย่างข้อมูล โหลดตามนี้ได้เลย
import pandas as pd
url = "https://raw.githubusercontent.com/Cheukting/anomaly-detection/refs/heads/main/data/Hive17.csv"
df = pd.read_csv(url, sep = ";")
df = df.dropna()
print(df.head())
ตัวอย่างผมที่ได้จากการ run
ขั้นตอนที่ 2: เริ่มจาก OneClassSVM เราจะต้องจัดข้อมูลที่จะลองเทียบดู
ตอนนี้จะลองเทียบ T17 เเละ RH17
from sklearn.svm import OneClassSVM
from sklearn.inspection import DecisionBoundaryDisplay
import matplotlib.pyplot as plt
X = df[["T17", "RH17"]].values
ขั้นตอนที่ 3: สร้างเเละ fit ข้อมูลเข้าไปใน model
จะสร้าง variable ชื่อว่า estimator
estimator = OneClassSVM().fit(X)
ขั้นตอนที่ 4: สร้าง graph เพื่อดู Decision Boundary
เราลองสร้าง Graph เพื่อที่จะดู Decision Boundary
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
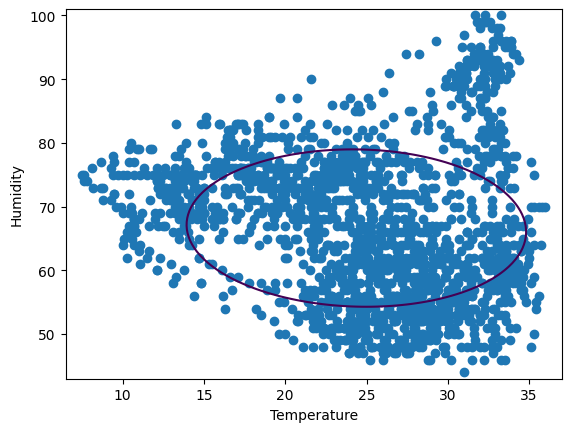
จาก Graph ที่ได้จะเห็นเลยว่าค่าของ Decision Boundary ไม่ค่อยเข้ากับ Data Point ของพวกเราเลย
Decision Boundary ไม่ควรเป็นวงรี เพราะว่า Data Point ของพวกเราเป็นรูปร่างที่ไม่เเน่นอน เราก็เลยจำเป็นที่จะปรับ Parameter ของ model เราให้ดีขึ้นโดยใช้ "nu" เเละ "gamma"
หลังจากทดลองหลายครั้ง ก็ได้พบว่าใช้ "nu=0.1, gamma=0.05" ให้ผลที่ดีสุด
ขั้นตอนที่ 5: ปรับปรุง
estimator = OneClassSVM(nu=0.1, gamma=0.05).fit(X)
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
จะได้เป็น Graph นี้
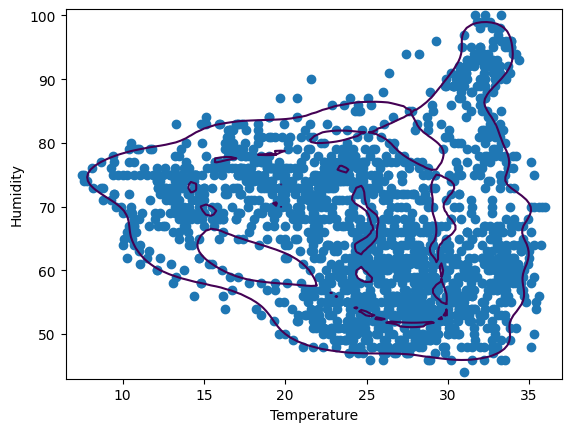
จากตัวอย่างนี้ เราจะได้ Graph ออกมาที่สามารถดูเเละทำ Anomaly Detection ได้โดยการดูใน Graph
Data ที่มีค่าอยู่นอก Decision Boundary จะถือว่าไม่ปกตินี่เอง
ขั้นตอนที่ 6: Isolation Forest
เราสามารถที่จะทำ Anomaly Detection ได้ในอีกวิธีนึง นั้นคือการใช้ Isolation Forest
from sklearn.ensemble import IsolationForest
estimator2 = IsolationForest(n_estimators=100).fit(X)
เราลองสร้าง Graph อีกรอบ เเต่ใช้ Isolation Forest เเทน
disp = DecisionBoundaryDisplay.from_estimator(
estimator2,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Temperature", ylabel="Humidity",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
จะได้ Graph นี้
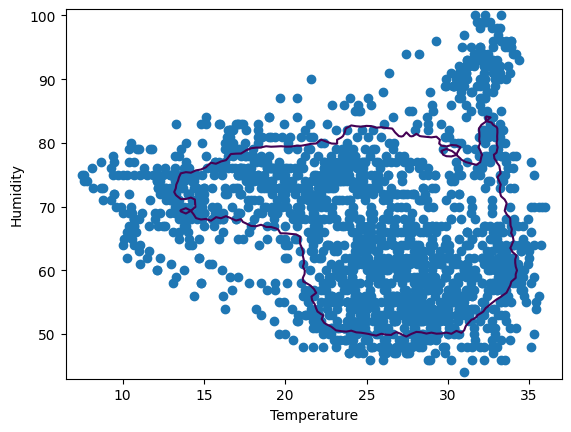
เราก็จะเห็นสองเเนวทางที่มีผลเเตกต่างกัน ทั้งสองวิธีมีผลที่ถูกต้อง ทั้งคู่นำไปใช้เปรียบเทียบเพื่อค้นหา anomalies ได้เลย
ตัวอย่างเพิ่มเติม
เราจะลองใช้ตัวอย่างอื่นบ้าง จะลองสร้างข้อมูลใหม่ขึ้นมา
จะสมมุติ Data ของ Website การขายของ E-Commerce ออกมาที่หนึ่ง
ข้อมูลจะออกมาเป็นอย่างนี้:
Session Duration,Pages Visited,Items in Cart,Total Purchase Value,Product Views
5,10,2,25.99,15
8,15,1,12.50,22
12,25,5,78.00,35
3,7,0,0.00,9
10,20,3,45.75,28
6,12,1,9.99,18
7,14,2,32.50,20
9,18,4,62.20,25
4,9,0,0.00,11
11,22,3,51.00,30
0.5,1,0,0.00,1
60,5,0,0.00,3
7,50,1,15.00,45
0,0,0,0.00,0
15,28,10,150.00,40
2,3,0,0.00,5
9,16,2,28.75,23
13,26,6,92.10,38
4,8,1,17.99,10
10,19,3,41.50,27
ใน Dataset นี้จะประกอบไปด้วย 20 เเถว เเต่ละเเถวจะเเสดงถึงกิจกรรมของผู้ใช้ใน Session
ข้อมูลประกอบไปด้วย 5 Column ดังนี้:
[1] Session Duration ระยะเวลาที่ผู้ใช้เข้าชมเว็บไซต์ในหนึ่ง Session (เป็นนาที)
[2] Pages Visited จำนวนหน้าที่ผู้ใช้เข้าชมในระหว่าง Session นั้น
[3] Items in Cart จำนวนสินค้าที่ผู้ใช้เพิ่มลงในตะกร้าสินค้าในระหว่าง Session
[4] Total Purchase Value มูลค่ารวมของสินค้าที่ผู้ใช้ซื้อในระหว่าง Session (เป็น Dollar สหรัฐ)
[5] Product Views จำนวนหน้ารายละเอียดสินค้าที่ผู้ใช้เข้าชม
ขั้นตอนที่ 1: เอาข้อมูลเข้า
ตัวอย่างข้อมูล โหลดตามนี้ได้เลย
import pandas as pd
url = "https://raw.githubusercontent.com/stoneman2/dummy_data/refs/heads/main/ecommerce.csv"
df = pd.read_csv(url, sep = ",")
df = df.dropna()
print(df.head())
ตัวอย่างผมที่ได้จากการ run
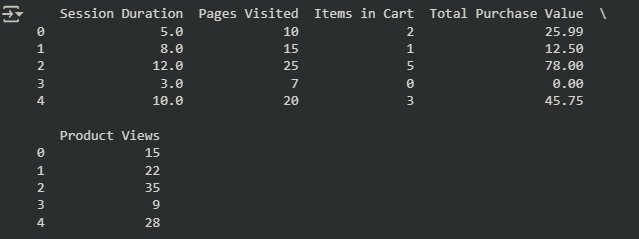
ขั้นตอนที่ 2: เริ่มจาก OneClassSVM เราจะต้องจัดข้อมูลที่จะลองเทียบดู
ตอนนี้จะลองเทียบ Session Duration เเละ Pages Visited
from sklearn.svm import OneClassSVM
from sklearn.inspection import DecisionBoundaryDisplay
import matplotlib.pyplot as plt
X = df[["Session Duration", "Pages Visited"]].values
ขั้นตอนที่ 3: สร้างเเละ fit ข้อมูลเข้าไปใน model
จะสร้าง variable ชื่อว่า estimator
estimator = OneClassSVM().fit(X)
ขั้นตอนที่ 4: สร้าง graph เพื่อดู Decision Boundary
เราลองสร้าง Graph เพื่อที่จะดู Decision Boundary
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Session Duration", ylabel="Pages Visited",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
จะได้ Graph นี้
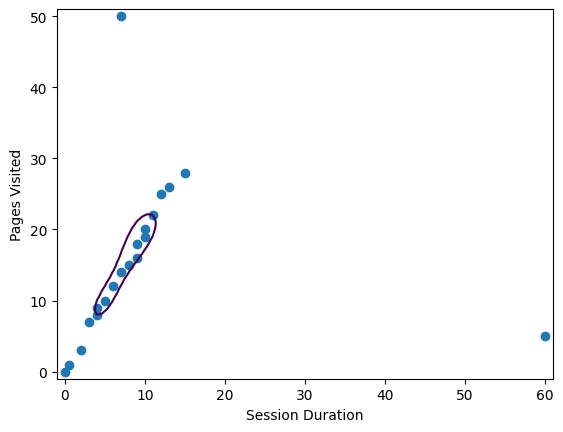
เราสามารถใช้ Graph นี้เพื่อที่จะดูได้ว่ามีผู้ใช้ที่เเปลกบ้างไหม เเล้วเราก็สามารถที่จะปรับตัว model ได้อีก
ขั้นตอนที่ 5: ปรับปรุง
estimator = OneClassSVM(nu=0.1, gamma=0.01).fit(X)
disp = DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Session Duration", ylabel="Pages Visited",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
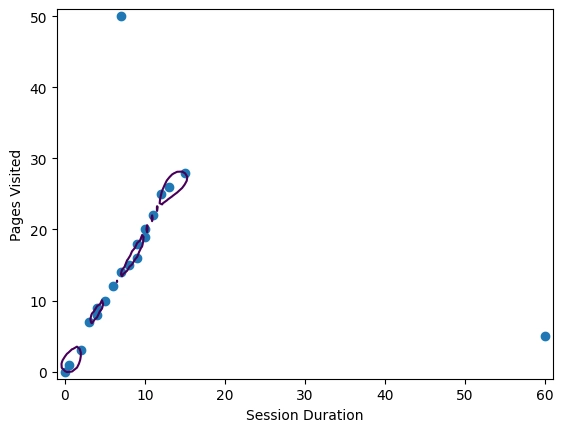
จะได้เป็น Graph นี้ เราจะเห็นว่า ค่า Decision Boundary มีเหตุผลมากขึ้น
ขั้นตอนที่ 6: Isolation Forest
เราสามารถที่จะทำ Anomaly Detection ได้ในอีกวิธีนึง นั้นคือการใช้ Isolation Forest
from sklearn.ensemble import IsolationForest
estimator2 = IsolationForest(n_estimators=100).fit(X)
เราลองสร้าง Graph อีกรอบ เเต่ใช้ Isolation Forest เเทน
disp = DecisionBoundaryDisplay.from_estimator(
estimator2,
X,
response_method="decision_function",
plot_method="contour",
xlabel="Session Duration", ylabel="Pages Visited",
levels=[0],
)
disp.ax_.scatter(X[:, 0], X[:, 1])
plt.show()
จะได้ Graph นี้
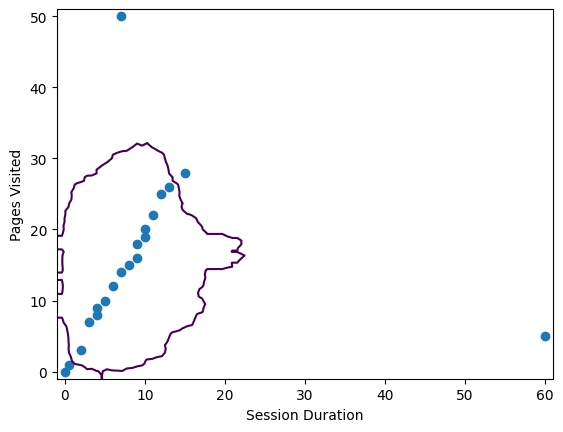
เราจะเห็นว่ามีข้อมูลที่ผิดปกติบ้าง เช่นมีคนที่เข้า Page มากกว่าปกติหรือมีคนที่ไม่เข้า Page เลยเเต่มี Session Duration ที่นานเกินปกติ จะสามารถเห็นถึงว่าคนนั้นเป็น bot หรือมี error อะไรก็เป็นได้
สรุปผล
ในบทความนี้ เราสามารถเเสดงตัวอย่างการทำ Anomaly Detection ได้โดยการใช้สองวิธี นั่นคือ OneClassSVM เเละ Isolation Forest
ลองนำเเนวทางนี้ไปปรับกับข้อมูลอื่นๆได้ง่ายมาก เพื่อการหา Anomaly ที่สนใจได้เลย
References:
Hive17 Github:
https://github.com/Cheukting/anomaly-detection/blob/main/data/Hive17.csv
E-Commerce (สร้างเอง ใส่ไว้ใน Github ผมเอง): https://github.com/stoneman2/dummy_data/blob/main/ecommerce.csv
Anomaly Detection in Machine Learning Using Python:
https://blog.jetbrains.com/pycharm/2025/01/anomaly-detection-in-machine-learning/







