







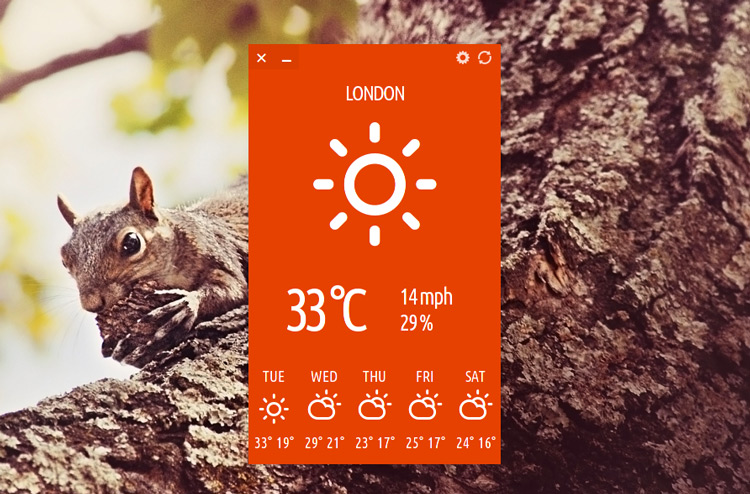














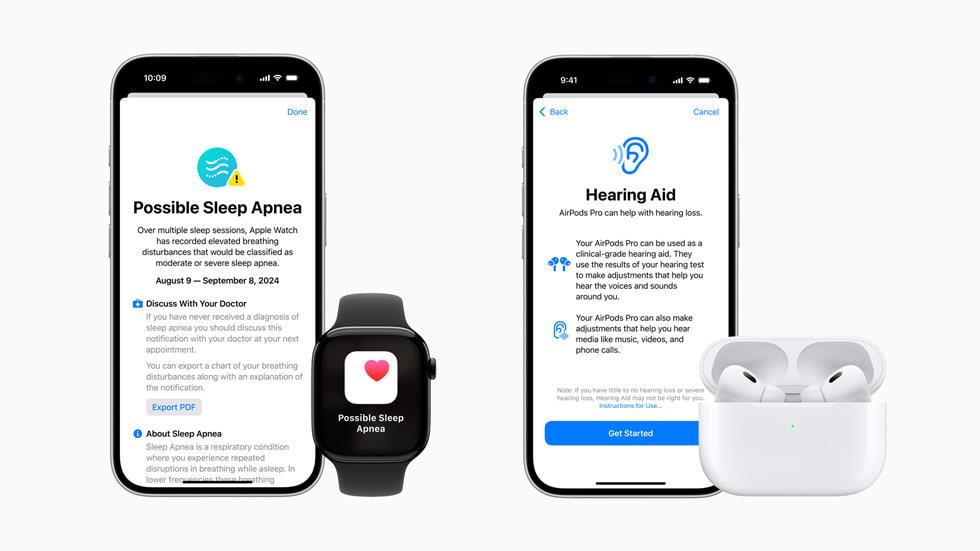
















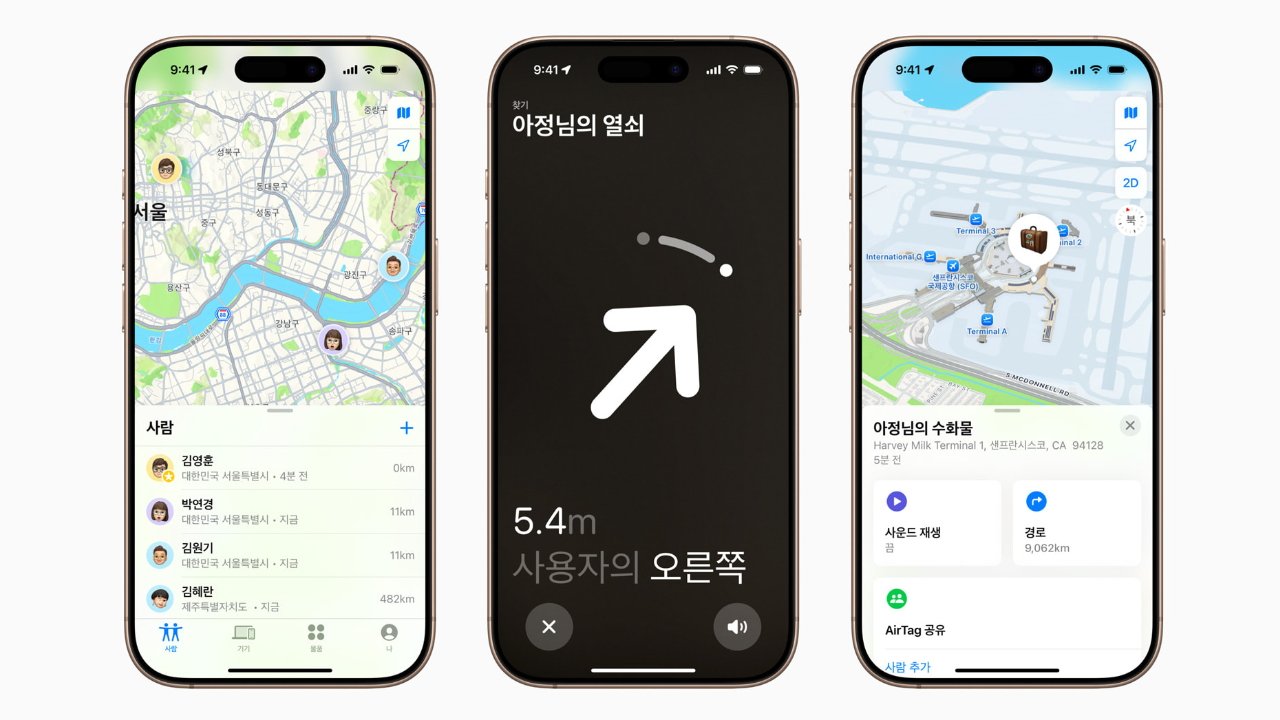
![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)

![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)












![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













-xl-xl.jpg)













































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)



















































































































![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)
![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

















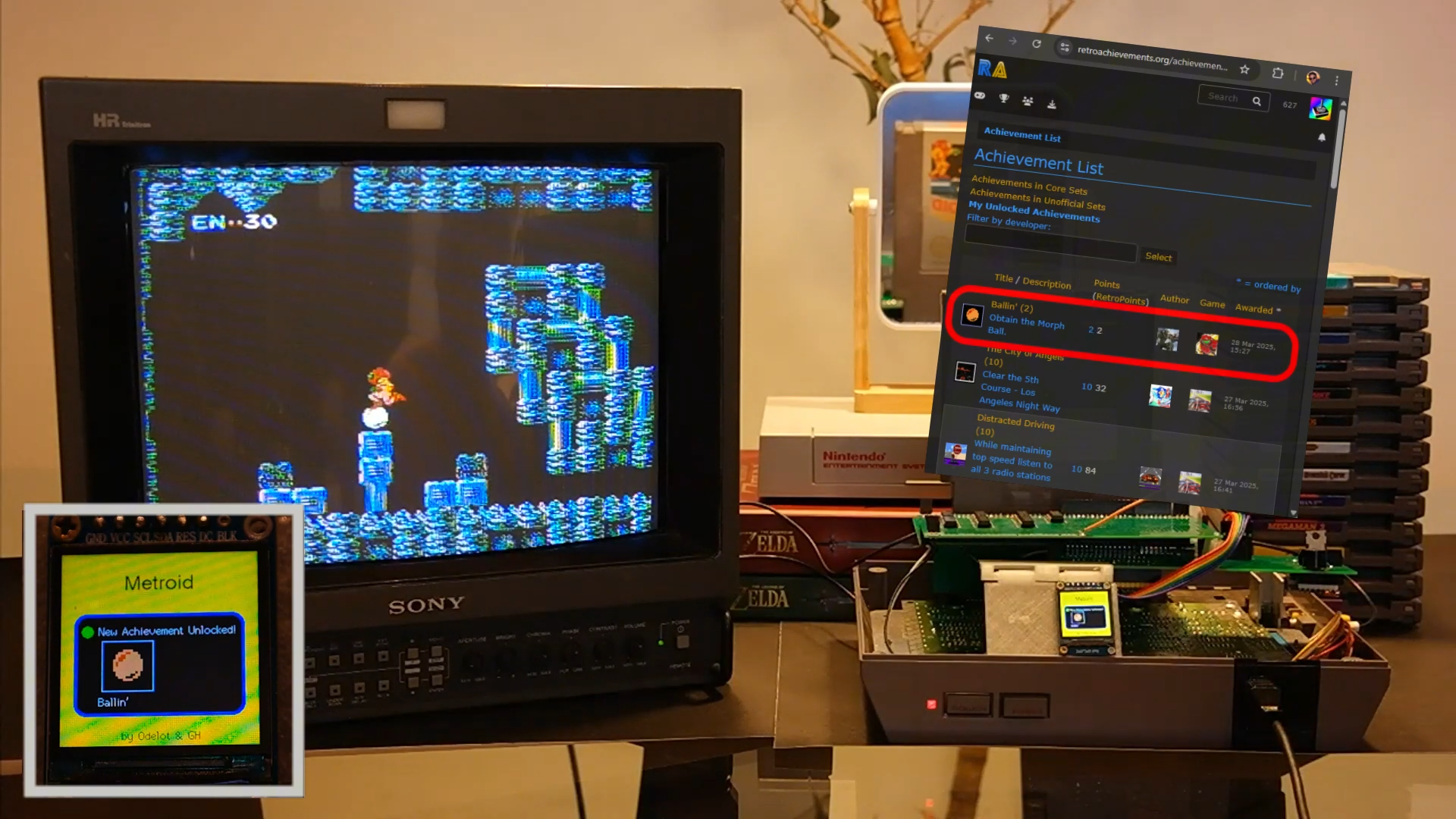
![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)































-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





















































Build an AI-Powered Chatbot with Amazon Lex, Bedrock, S3 and RAG
In this comprehensive tutorial, we’ll build a powerful AI chatbot that leverages AWS services to provide intelligent responses based on your organization’s documents. Using Retrieval Augmented Generation (RAG), we’ll create a system that not only understands questions but provides accurate answers from your specific documentation. Solution Architecture Let’s start by understanding the overall architecture of our solution: Core Components and Data Flow Amazon S3 Stores source PDF documents Provides secure, scalable document storage Acts as the foundation of our knowledge base Amazon Bedrock & Knowledge Base Orchestrates the RAG workflow Processes queries using Claude V2 Manages document retrieval and response generation Titan Embeddings Converts documents and queries into vector embeddings Enables semantic understanding of content Processes documents for vector representation Amazon OpenSearch Functions as our vector store Enables efficient similarity search Indexes processed document embeddings Amazon Lex Handles the conversational interface Manages natural language understanding Routes queries through appropriate intents IAM Roles Manages cross-service permissions Ensures secure communication Controls resource access Prerequisites Before we begin implementation, ensure you have: An AWS account (non-root user with admin privileges) Access to these Bedrock models: Titan Embeddings G1 Text Claude V2 Basic familiarity with AWS services ⚠️ Important Region Note: This implementation must be done in the US East (N. Virginia) us-east-1 region as some required Bedrock models may not be available in other regions. Make sure to switch to us-east-1 before starting the implementation. Cost Considerations Understanding the cost structure is crucial for planning: Amazon Bedrock: $0.08 per 1,000 input tokens (Claude V2) Amazon Lex: Free tier includes 10,000 text requests and 5,000 speech requests Amazon S3: Free tier eligible, then $0.023 per GB OpenSearch Serverless: Pricing based on OCU hours For development and testing, costs should remain minimal. Implementation Steps 1. Document Storage Setup (S3) Navigate to S3 console Create a new bucket Upload your PDF documents Note the bucket name for later use 2. Knowledge Base Configuration (Bedrock) Before creating our knowledge base, we need to ensure we have access to the required models in Bedrock. 2.1 Request Model Access Navigate to Amazon Bedrock in us-east-1 region Go to Model access in the left navigation Click “Manage model access” Request access to these models if you haven’t already: Anthropic Claude V2 (under Anthropic section) Titan Embeddings G1 — Text (under Amazon section) Select the models and click “Request model access” Wait for access to be granted (usually takes a few minutes) **Note: If you don’t have access to a model, you’ll see a message saying “This account doesn’t have access to this model” when you hover over it. Click the provided link to request access. 2.2 Create Knowledge Base In Bedrock console, go to Knowledge bases in the left navigation Click “Create knowledge base” Name Knowledge base or leave default For permissions: IAM permissions: Create and use a new service role 2.3 Configure Data Source In the data source section: Data source: Amazon S3 Source: This AWS account S3 bucket: Select your ‘ai-powered-bot’ bucket 2.4 Configure Embeddings and Vector Store Select embeddings model: Embeddings model: Titan Embeddings G1 — Text Provider: Amazon Configure vector database: Vector store creation: Quick create a new vector store (Recommended) 2.5 Review and Create Review all configurations Click “Create knowledge base” Wait for the knowledge base to be created (this may take a few minutes) 2.6 Sync Data Source Once the knowledge base is created, you’ll see a success message Click “Go to data sources” in the success message Select your data source Click “Sync” to start indexing your documents Wait for the sync to complete (time varies based on document size) **Important: The sync process converts your documents into embeddings and stores them in the vector database. This is crucial for enabling semantic search capabilities. 2.7 Verify Knowledge Base Status Check the status of your knowledge base: Go to Knowledge bases Look for your knowledge base Status should show “Available” Note your Knowledge base ID (you’ll need this for Lex configuration) Troubleshooting Common Issues Model Access Issues: Ensure you’re in us-east-1 region Verify model access status in Model access page Wait a few minutes after requesting access before retrying Data Source Sync Failed: Check IAM role permissions Verify S3 bucket accessibility Ensure documents are in supported format (PDF) Vector Store Creation Failed: Check service quo
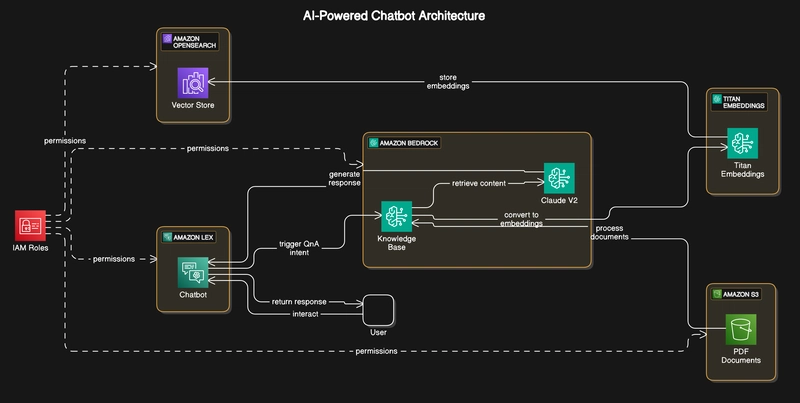
In this comprehensive tutorial, we’ll build a powerful AI chatbot that leverages AWS services to provide intelligent responses based on your organization’s documents. Using Retrieval Augmented Generation (RAG), we’ll create a system that not only understands questions but provides accurate answers from your specific documentation.
Solution Architecture
Let’s start by understanding the overall architecture of our solution:
Core Components and Data Flow
- Amazon S3
Stores source PDF documents
Provides secure, scalable document storage
Acts as the foundation of our knowledge base
- Amazon Bedrock & Knowledge Base
Orchestrates the RAG workflow
Processes queries using Claude V2
Manages document retrieval and response generation
- Titan Embeddings
Converts documents and queries into vector embeddings
Enables semantic understanding of content
Processes documents for vector representation
- Amazon OpenSearch
Functions as our vector store
Enables efficient similarity search
Indexes processed document embeddings
- Amazon Lex
Handles the conversational interface
Manages natural language understanding
Routes queries through appropriate intents
- IAM Roles
Manages cross-service permissions
Ensures secure communication
Controls resource access
Prerequisites
Before we begin implementation, ensure you have:
An AWS account (non-root user with admin privileges)
Access to these Bedrock models:
Titan Embeddings G1 Text
Claude V2
- Basic familiarity with AWS services
⚠️ Important Region Note: This implementation must be done in the US East (N. Virginia) us-east-1 region as some required Bedrock models may not be available in other regions. Make sure to switch to us-east-1 before starting the implementation.
Cost Considerations
Understanding the cost structure is crucial for planning:
Amazon Bedrock: $0.08 per 1,000 input tokens (Claude V2)
Amazon Lex: Free tier includes 10,000 text requests and 5,000 speech requests
Amazon S3: Free tier eligible, then $0.023 per GB
OpenSearch Serverless: Pricing based on OCU hours
For development and testing, costs should remain minimal.
Implementation Steps
1. Document Storage Setup (S3)
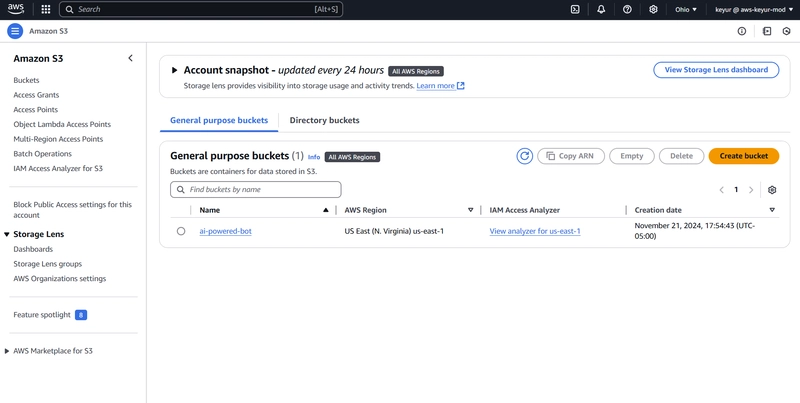
Navigate to S3 console
Create a new bucket
Upload your PDF documents
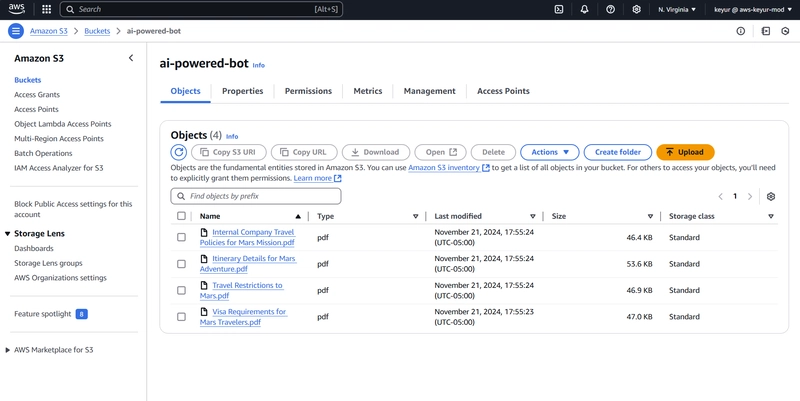
- Note the bucket name for later use
2. Knowledge Base Configuration (Bedrock)
Before creating our knowledge base, we need to ensure we have access to the required models in Bedrock.
2.1 Request Model Access
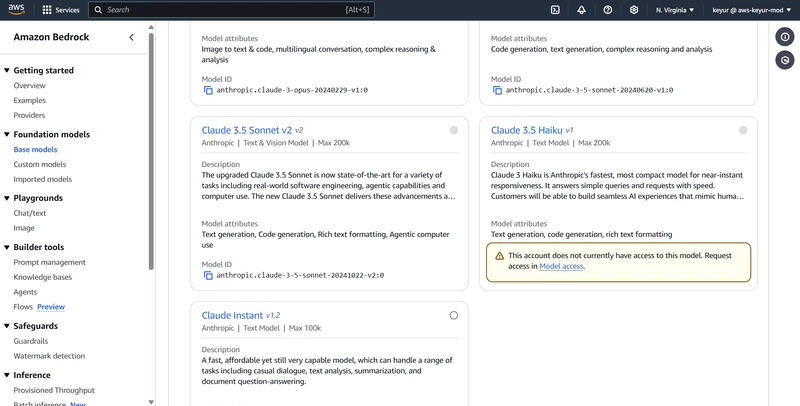
Navigate to Amazon Bedrock in us-east-1 region
Go to Model access in the left navigation
Click “Manage model access”
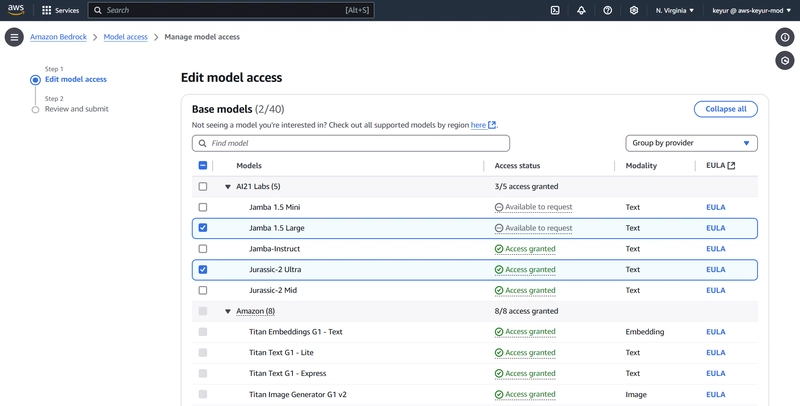
- Request access to these models if you haven’t already:
Anthropic Claude V2 (under Anthropic section)
Titan Embeddings G1 — Text (under Amazon section)
Select the models and click “Request model access”
-
Wait for access to be granted (usually takes a few minutes)
**Note: If you don’t have access to a model, you’ll see a message saying “This account doesn’t have access to this model” when you hover over it. Click the provided link to request access.
2.2 Create Knowledge Base
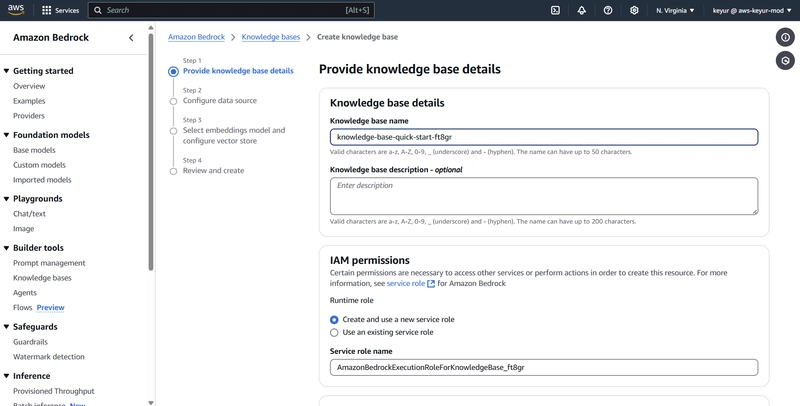
In Bedrock console, go to Knowledge bases in the left navigation
Click “Create knowledge base”
Name Knowledge base or leave default
For permissions:
IAM permissions: Create and use a new service role
2.3 Configure Data Source
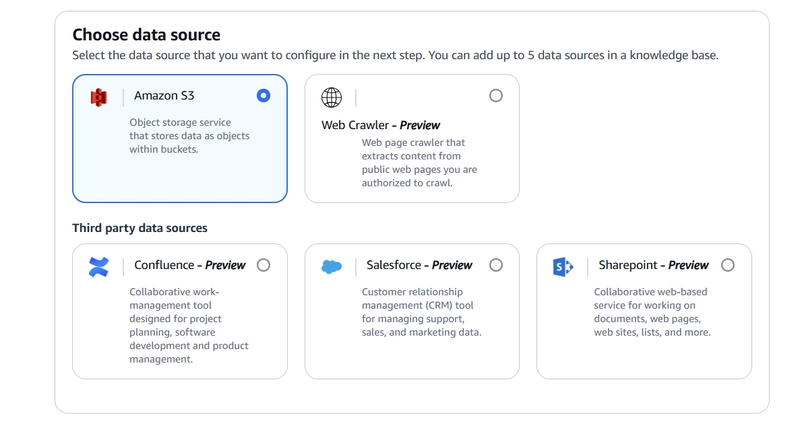
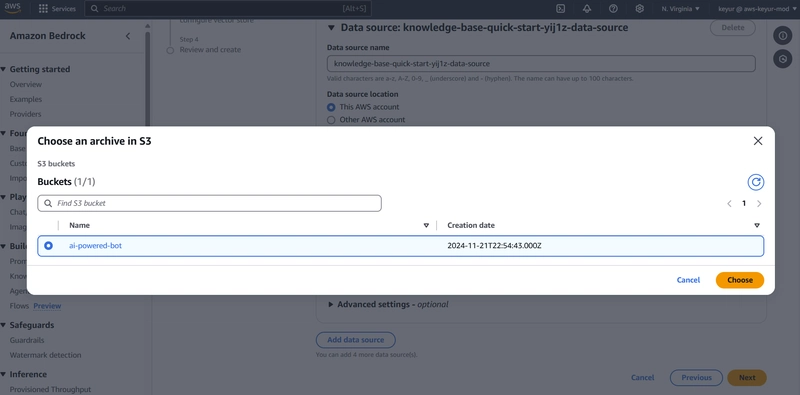
In the data source section:
Data source: Amazon S3
Source: This AWS account
S3 bucket: Select your ‘ai-powered-bot’ bucket
2.4 Configure Embeddings and Vector Store
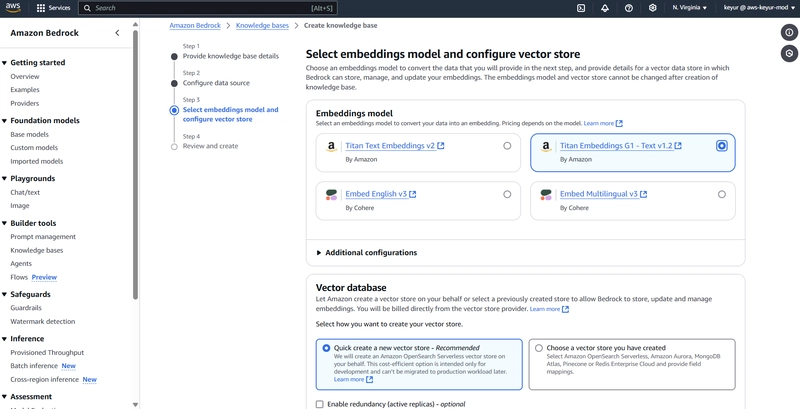
- Select embeddings model:
Embeddings model: Titan Embeddings G1 — Text
Provider: Amazon
- Configure vector database:
Vector store creation: Quick create a new vector store (Recommended)
2.5 Review and Create
Review all configurations
Click “Create knowledge base”
Wait for the knowledge base to be created (this may take a few minutes)
2.6 Sync Data Source
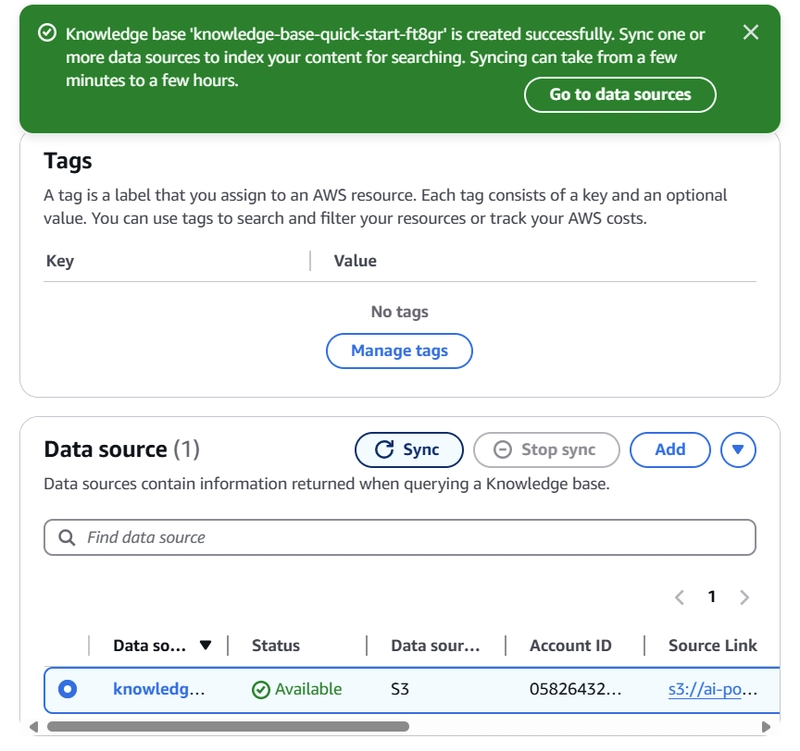
Once the knowledge base is created, you’ll see a success message
Click “Go to data sources” in the success message
Select your data source
Click “Sync” to start indexing your documents
-
Wait for the sync to complete (time varies based on document size)
**Important: The sync process converts your documents into embeddings and stores them in the vector database. This is crucial for enabling semantic search capabilities.
2.7 Verify Knowledge Base Status
- Check the status of your knowledge base:
Go to Knowledge bases
Look for your knowledge base
Status should show “Available”
- Note your Knowledge base ID (you’ll need this for Lex configuration)
Troubleshooting Common Issues
- Model Access Issues:
Ensure you’re in us-east-1 region
Verify model access status in Model access page
Wait a few minutes after requesting access before retrying
- Data Source Sync Failed:
Check IAM role permissions
Verify S3 bucket accessibility
Ensure documents are in supported format (PDF)
- Vector Store Creation Failed:
Check service quotas
Verify OpenSearch Serverless availability
Ensure IAM role has necessary permissions
3. Chatbot Implementation (Lex)
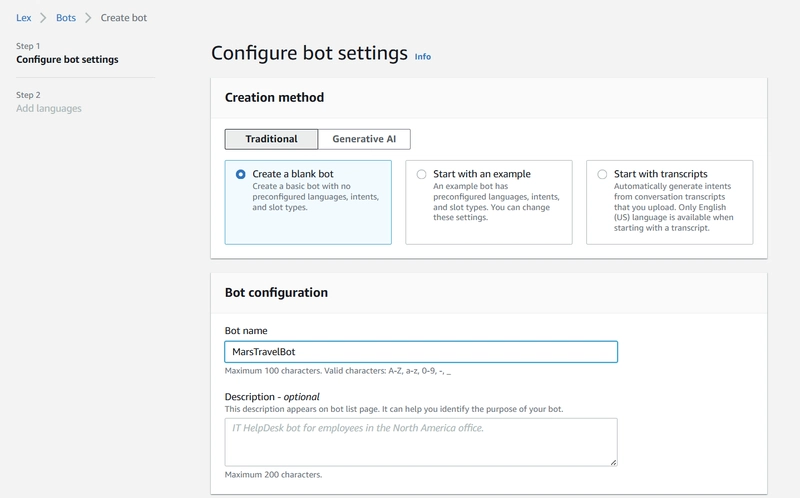
3.1 Initial Bot Creation
Navigate to Amazon Lex in us-east-1 region
Click “Create bot”
Creation method: Start with a blank bot (Traditional)
Runtime role: Create new role
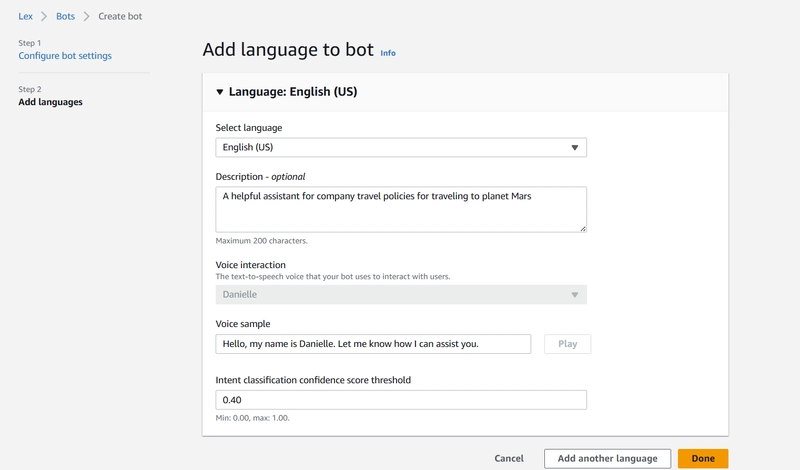
3.2 Language Configuration
3.3 Configure Welcome Intent
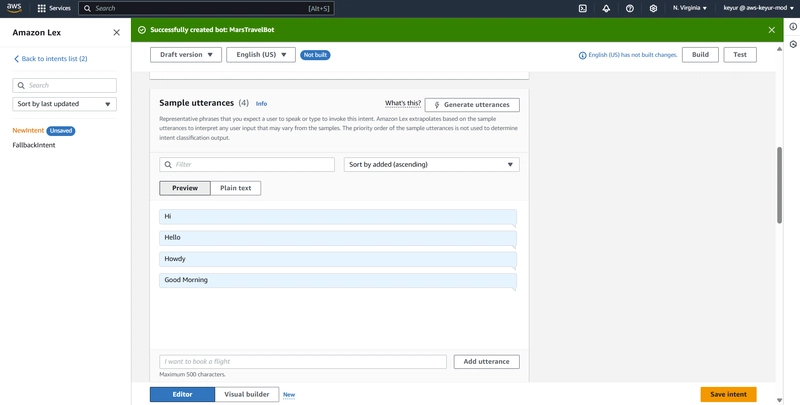
Create a new intent
Add sample utterances:
Click “+” to add each utterance
- Configure initial response
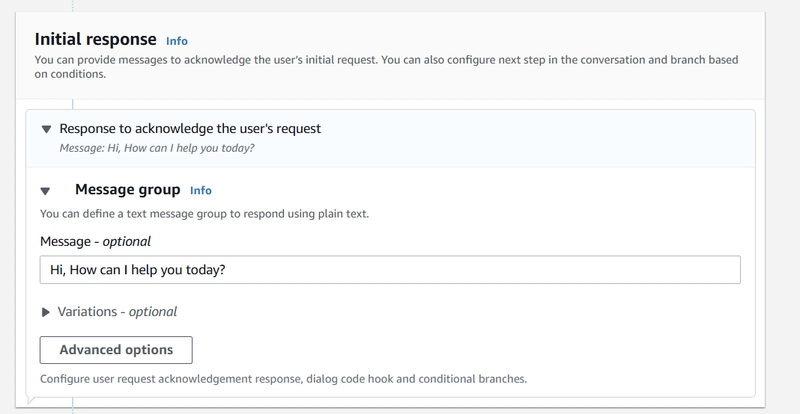
- Configure conversation flow:
Wait for user response: Enable
- Click “Save intent”
3.4 Configure QnA Intent
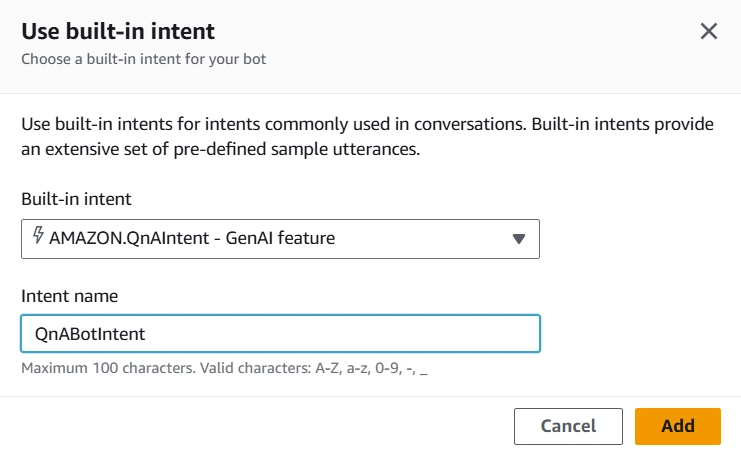
Configure QnA settings:
Select model:
Provider: Anthropic
Model: Claude V2
Knowledge store:
Type: Knowledge base for Amazon Bedrock
Knowledge base ID: [Your Bedrock knowledge base ID]
4. Testing and Validation
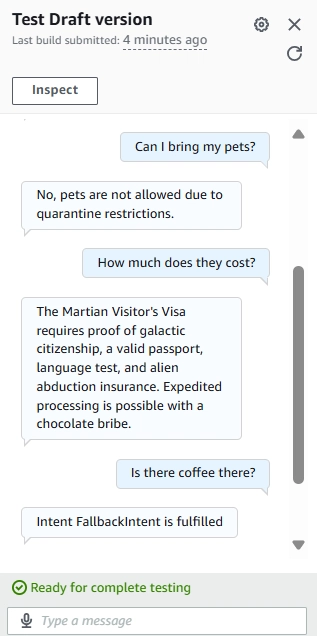
Click “Build” to compile your bot configuration
Once built, click “Test” to open the test console
RAG Implementation Details
Our implementation uses RAG to provide accurate, document-based responses:
- Document Processing
Documents uploaded to S3
Titan Embeddings creates vector representations
Vectors stored in OpenSearch
- Query Processing
User query received by Lex
Query converted to embeddings
Similar content retrieved from vector store
Claude V2 generates contextual response
- Response Generation
Combines retrieved content with language model capabilities
Ensures responses are grounded in your documents
Maintains accuracy while providing natural responses
Best Practices
Document Management
Keep documents well-structured
Regular content updates
Consistent formatting
Clear section headers
Performance Optimization
Regular knowledge base syncs
Monitor response times
Track usage patterns
Adjust confidence thresholds
Security Considerations
Implement least-privilege IAM roles
Regular security audits
Monitor access patterns
Encrypt sensitive data
Cleanup Process
To avoid ongoing charges:
Delete Bedrock knowledge base
Remove S3 bucket and contents
Delete Lex bot configuration
Delete associated IAM roles
Future Enhancements
Consider these potential improvements:
Multi-language support
Custom response templates
Integration with existing systems
Advanced analytics and monitoring
A/B testing for responses
Conversation history management
Conclusion
By combining Amazon Lex, Bedrock, and S3 with RAG architecture, we’ve created a powerful, intelligent chatbot that can accurately answer questions based on your documentation. This implementation demonstrates the potential of AI-powered document interaction while maintaining control over the knowledge base.
The architecture allows for scalability and customization, making it suitable for various use cases from internal documentation to customer support.