































































![Apple Shares Official Trailer for 'Fountain of Youth' Starring John Krasinski, Natalie Portman [Video]](https://www.iclarified.com/images/news/96902/96902/96902-1280.jpg)
![Apple is Still Working on Solid State iPhone Buttons [Rumor]](https://www.iclarified.com/images/news/96904/96904/96904-640.jpg)
![Nomad Goods Launches 15% Sitewide Sale for 48 Hours Only [Deal]](https://www.iclarified.com/images/news/96899/96899/96899-640.jpg)

















































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)


















































































































![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)



















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)























































































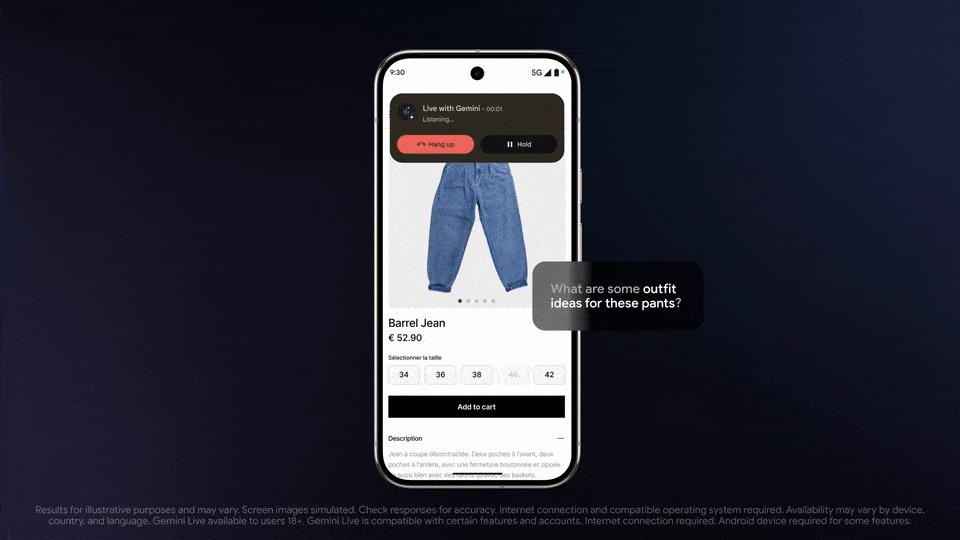
Retrieval Augmented Generation (RAG) from Scratch — Tutorial For Dummies
Ever wondered how AI tools like ChatGPT can answer questions based on specific documents they've never seen before? This guide breaks down Retrieval Augmented Generation (RAG) in the simplest possible way with minimal code implementation! Have you ever asked an AI a question about your personal documents and received a completely made-up answer? Or maybe you've been frustrated when chatbots provide outdated information? These are common problems with traditional LLMs (Large Language Models), but there's a solution: Retrieval Augmented Generation (RAG). In this beginner-friendly tutorial, you'll learn: The key concepts behind RAG systems in plain language How to build a working RAG system step-by-step Why RAG dramatically improves AI responses for your specific documents We'll use PocketFlow - a simple 100-line framework that strips away complexity. Unlike other frameworks with convoluted abstractions, PocketFlow lets you see the entire system at once, giving you the fundamentals to build your understanding from the ground up. What's RAG (In Human Terms)? Imagine RAG is like giving an AI its own personal research librarian before it answers your questions. Here's how the magic happens: Document Collection: You provide your documents (company manuals, articles, books) to the system, just like books being added to a library. Chunking: The system breaks these down into bite-sized, digestible pieces - like librarians dividing books into chapters and sections rather than working with entire volumes. Embedding: Each chunk gets converted into a special numerical format (vector) that captures its meaning - similar to creating detailed index cards that understand concepts, not just keywords. Indexing: These vectors are organized in a searchable database - like a magical card catalog that understands the relationships between different topics. Retrieval: When you ask a question, the system consults its index to find the most relevant chunks related to your query. Generation: The AI crafts an answer using both your question AND these helpful references, producing a much better response than if it relied solely on its pre-trained knowledge. The result? Instead of making things up or giving outdated information, the AI grounds its answers in your specific documents, providing accurate, relevant responses tailored to your information. Chunking: Breaking Documents into Manageable Pieces Before our RAG system can work effectively, we need to break our documents into smaller, digestible pieces. Think of chunking like preparing a meal for guests - you wouldn't serve a whole turkey without carving it first! Why Chunking Matters The size of your chunks directly impacts the quality of your RAG system: Too large chunks: Your system retrieves too much irrelevant information (like serving entire turkeys) Too small chunks: You lose important context (like serving single peas) Just right chunks: Your system finds precisely what it needs (perfect portions!) Let's explore some practical chunking methods: 1. Fixed-Size Chunking: Simple but Imperfect The simplest approach divides text into equal-sized pieces, regardless of content: def fixed_size_chunk(text, chunk_size=50): chunks = [] for i in range(0, len(text), chunk_size): chunks.append(text[i:i+chunk_size]) return chunks This code loops through text, taking 50 characters at a time. Let's see how it works on a sample paragraph: Input Text: The quick brown fox jumps over the lazy dog. Artificial intelligence has revolutionized many industries. Today's weather is sunny with a chance of rain. Many researchers work on RAG systems to improve information retrieval. Output Chunks: Chunk 1: "The quick brown fox jumps over the lazy dog. Arti" Chunk 2: "ficial intelligence has revolutionized many indus" Chunk 3: "tries. Today's weather is sunny with a chance of " Chunk 4: "rain. Many researchers work on RAG systems to imp" Chunk 5: "rove information retrieval." Notice the problem? The word "Artificial" is split between chunks 1 and 2. "Industries" is split between chunks 2 and 3. This makes it hard for our system to understand the content properly. 2. Sentence-Based Chunking: Respecting Natural Boundaries A smarter approach is to chunk by complete sentences: import nltk # Natural Language Toolkit library def sentence_based_chunk(text, max_sentences=1) sentences = nltk.sent_tokenize(text) chunks = [] # Group sentences, 1 at a time for i in range(0, len(sentences), max_sentences): chunks.append(" ".join(sentences[i:i+max_sentences])) return chunks This method first identifies complete sentences, then groups them one at a time: Output Chunks: Chunk 1: "The quick brown fox jumps over the lazy dog." Chunk 2: "Artificial intelligence has revolutionized many industries." Chunk 3: "Today's weather is sunny with a chance of rain." Chun
Ever wondered how AI tools like ChatGPT can answer questions based on specific documents they've never seen before? This guide breaks down Retrieval Augmented Generation (RAG) in the simplest possible way with minimal code implementation!
Have you ever asked an AI a question about your personal documents and received a completely made-up answer? Or maybe you've been frustrated when chatbots provide outdated information? These are common problems with traditional LLMs (Large Language Models), but there's a solution: Retrieval Augmented Generation (RAG).
In this beginner-friendly tutorial, you'll learn:
- The key concepts behind RAG systems in plain language
- How to build a working RAG system step-by-step
- Why RAG dramatically improves AI responses for your specific documents
We'll use PocketFlow - a simple 100-line framework that strips away complexity. Unlike other frameworks with convoluted abstractions, PocketFlow lets you see the entire system at once, giving you the fundamentals to build your understanding from the ground up.
What's RAG (In Human Terms)?
Imagine RAG is like giving an AI its own personal research librarian before it answers your questions. Here's how the magic happens:
Document Collection: You provide your documents (company manuals, articles, books) to the system, just like books being added to a library.
Chunking: The system breaks these down into bite-sized, digestible pieces - like librarians dividing books into chapters and sections rather than working with entire volumes.
Embedding: Each chunk gets converted into a special numerical format (vector) that captures its meaning - similar to creating detailed index cards that understand concepts, not just keywords.
Indexing: These vectors are organized in a searchable database - like a magical card catalog that understands the relationships between different topics.
Retrieval: When you ask a question, the system consults its index to find the most relevant chunks related to your query.
Generation: The AI crafts an answer using both your question AND these helpful references, producing a much better response than if it relied solely on its pre-trained knowledge.
The result? Instead of making things up or giving outdated information, the AI grounds its answers in your specific documents, providing accurate, relevant responses tailored to your information.
Chunking: Breaking Documents into Manageable Pieces
Before our RAG system can work effectively, we need to break our documents into smaller, digestible pieces. Think of chunking like preparing a meal for guests - you wouldn't serve a whole turkey without carving it first!
Why Chunking Matters
The size of your chunks directly impacts the quality of your RAG system:
- Too large chunks: Your system retrieves too much irrelevant information (like serving entire turkeys)
- Too small chunks: You lose important context (like serving single peas)
- Just right chunks: Your system finds precisely what it needs (perfect portions!)
Let's explore some practical chunking methods:
1. Fixed-Size Chunking: Simple but Imperfect
The simplest approach divides text into equal-sized pieces, regardless of content:
def fixed_size_chunk(text, chunk_size=50):
chunks = []
for i in range(0, len(text), chunk_size):
chunks.append(text[i:i+chunk_size])
return chunks
This code loops through text, taking 50 characters at a time. Let's see how it works on a sample paragraph:
Input Text:
The quick brown fox jumps over the lazy dog. Artificial intelligence has revolutionized many industries. Today's weather is sunny with a chance of rain. Many researchers work on RAG systems to improve information retrieval.
Output Chunks:
Chunk 1: "The quick brown fox jumps over the lazy dog. Arti"
Chunk 2: "ficial intelligence has revolutionized many indus"
Chunk 3: "tries. Today's weather is sunny with a chance of "
Chunk 4: "rain. Many researchers work on RAG systems to imp"
Chunk 5: "rove information retrieval."
Notice the problem? The word "Artificial" is split between chunks 1 and 2. "Industries" is split between chunks 2 and 3. This makes it hard for our system to understand the content properly.
2. Sentence-Based Chunking: Respecting Natural Boundaries
A smarter approach is to chunk by complete sentences:
import nltk # Natural Language Toolkit library
def sentence_based_chunk(text, max_sentences=1)
sentences = nltk.sent_tokenize(text)
chunks = []
# Group sentences, 1 at a time
for i in range(0, len(sentences), max_sentences):
chunks.append(" ".join(sentences[i:i+max_sentences]))
return chunks
This method first identifies complete sentences, then groups them one at a time:
Output Chunks:
Chunk 1: "The quick brown fox jumps over the lazy dog."
Chunk 2: "Artificial intelligence has revolutionized many industries."
Chunk 3: "Today's weather is sunny with a chance of rain."
Chunk 4: "Many researchers work on RAG systems to improve information retrieval."
Much better! Each chunk now contains a complete sentence with its full meaning intact.
3. Additional Chunking Strategies
Depending on your documents, these approaches might also work well:
- Paragraph-Based: Split text at paragraph breaks (usually marked by newlines)
- Semantic Chunking: Group text by topics or meaning (often requires AI assistance)
- Hybrid Approaches: Combine multiple strategies for optimal results
Choosing the Right Approach
While many sophisticated chunking methods exist, for most practical applications, the "Keep It Simple, Stupid" (KISS) principle applies. Starting with Fixed-Size Chunking of around 1,000 characters per chunk is often sufficient and avoids overcomplicating your system.
The best chunking approach ultimately depends on your specific documents and use case - just like a chef adjusts portions based on the meal and guests!
Embeddings: Making Retrieval Possible
Now that we've chopped up our documents, how does the system find the most relevant chunks for our questions? This is where embeddings come in! Embeddings are the magic that powers our retrieval system. Without them, we couldn't find the right information for our questions!
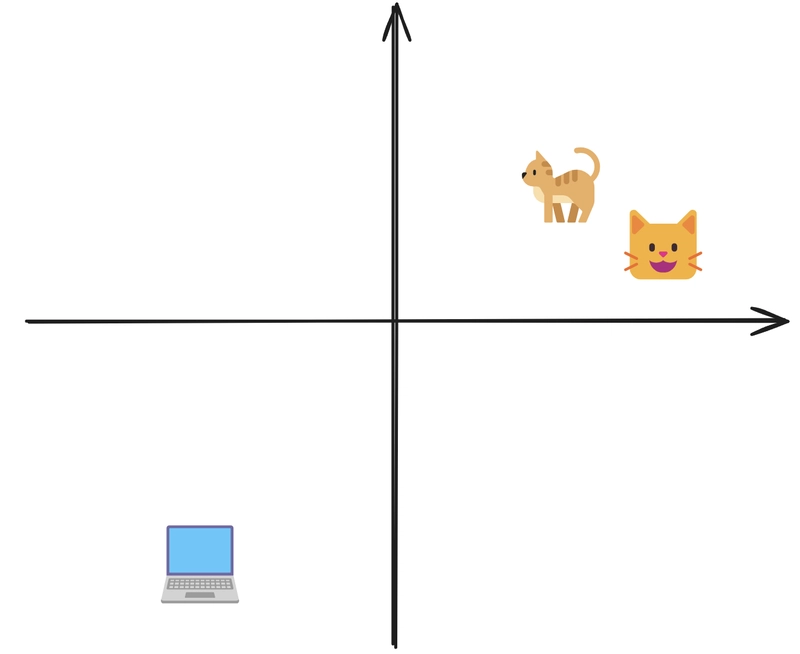
What Are Embeddings?
An embedding transforms text into a list of numbers (a vector) that captures its meaning. Think of it as creating a special "location" in a meaning-space where similar ideas are positioned close together.
For example, if we take these three sentences:
- "The cat sat on the mat."







