





















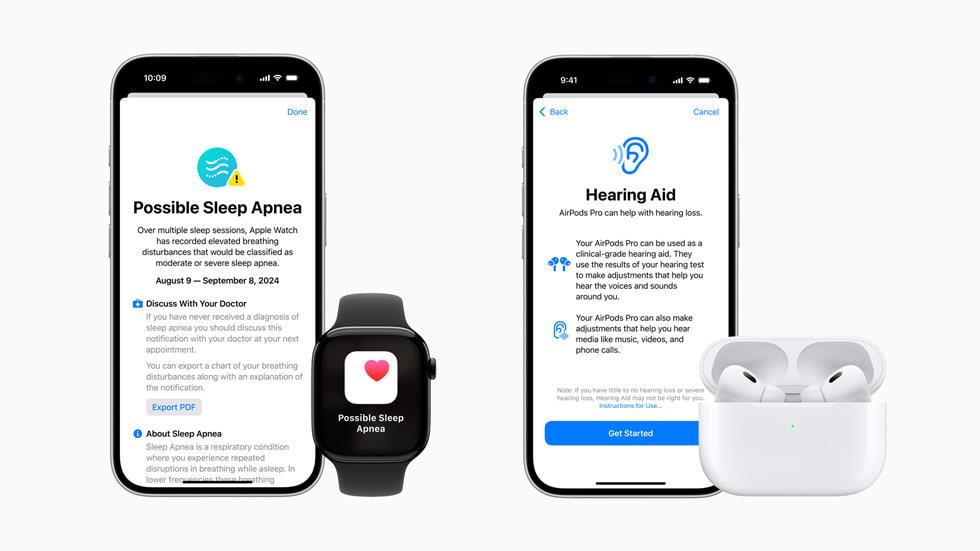
















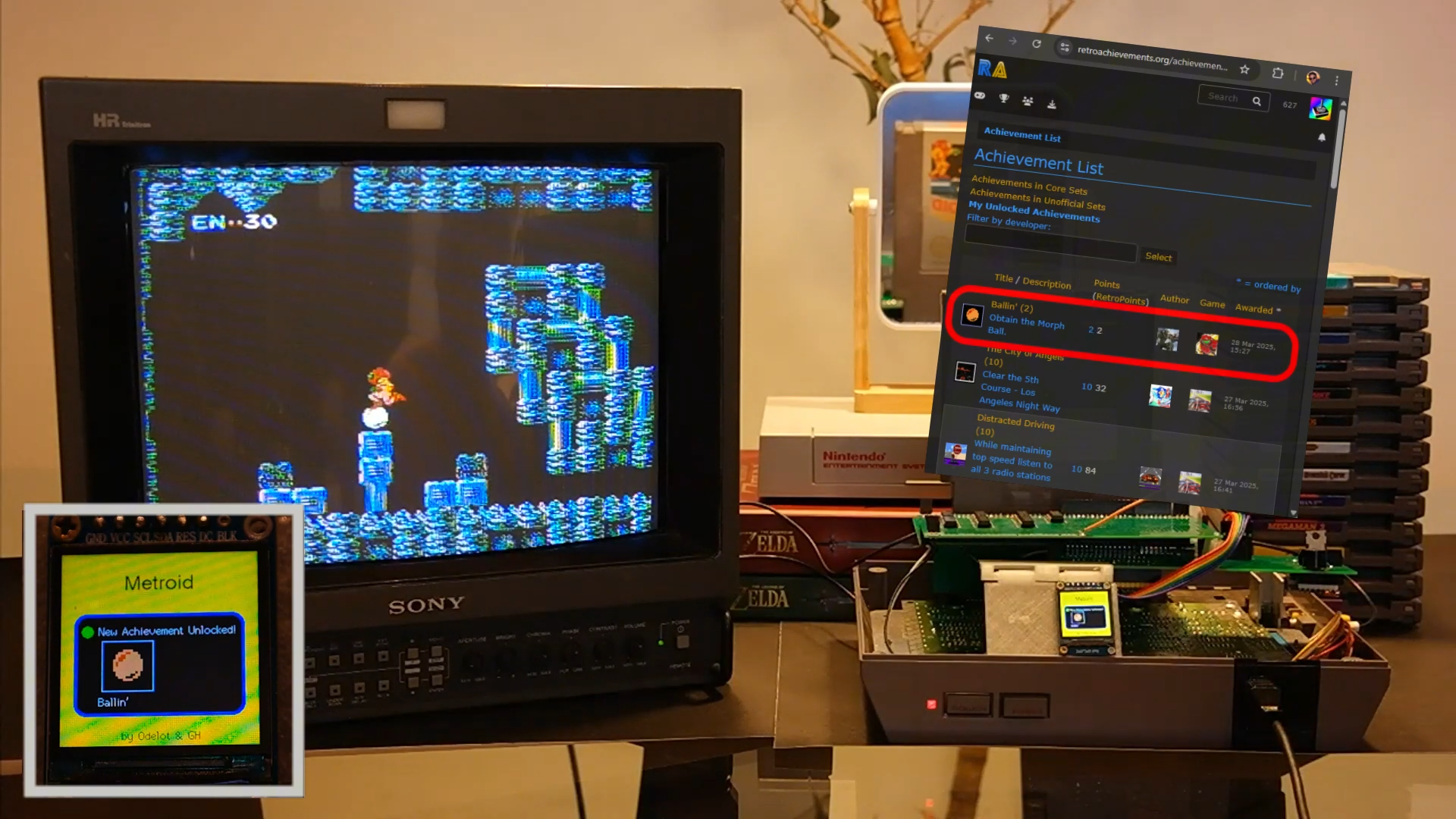
![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)

![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)












![What’s new in Android’s March 2025 Google System Updates [U: 3/31]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













-xl-xl.jpg)













































































































































![[The AI Show Episode 141]: Road to AGI (and Beyond) #1 — The AI Timeline is Accelerating](https://www.marketingaiinstitute.com/hubfs/ep%20141.1.png)
![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)



















































































































![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)
![Best practices for database design when storing AI/LLM conversations with tool/function calls? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)































-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





















































Understanding Math Behind RRF and DBSF with Examples
In Qdrant - a vector database used in machine learning applications - there are two primary strategies for combining (or "fusing") query results so that consistently strong performers are prioritized. I have already written a medium story about RRF and DBSF, giving a high level explanation on them. so you can read it here. in this article, focus is more on math behind these methods. let's get started! 1- Reciprocal Rank Fusion (RRF) How it Works: RRF is a rank-based method. It looks at where each result is positioned in every query's list. What It Does: If a particular result appears near the top in multiple queries, RRF boosts its overall ranking. The key idea is that results which are consistently ranked high across different queries are more likely to be relevant. Reciprocal Rank Fusion (RRF) is a method that combines search results by focusing solely on the positions (or ranks) where they appear in each query’s result list. Instead of relying on the raw scores assigned to each result, RRF rewards results that consistently appear higher up in the rankings. Here’s how it works with formulas and an example: 1-1 The RRF Formula For a given result (r)( r ) (r) that appears across multiple queries, the RRF score is calculated using the formula: RRF(r)=∑i=1N1k+ri(r) \text{RRF}(r) = \sum_{i=1}^{N} \frac{1}{k + r_i(r)} RRF(r)=i=1∑Nk+ri(r)1 where: (N)( N ) (N) is the number of queries. (ri(r))( r_i(r) ) (ri(r)) is the rank (position) of result (r)( r ) (r) in the (i)( i ) (i) -th query (with the best rank being 1). (k)( k ) (k) is a constant (often set to around 60) used to dampen the effect of very high rankings and ensure that the contribution of lower-ranked results is reduced. This formula means that a result that appears at a higher rank (i.e., with a smaller rank number) in a query will contribute a larger amount to the overall RRF score. 1-2 How It Boosts Results Rank Impact: If a result is ranked first in a query, its contribution is (1k+1)( \frac{1}{k+1} ) (k+11) . If it ranks second, the contribution is (1k+2)( \frac{1}{k+2} )(k+21) , and so on. Therefore, being ranked high (e.g., first or second) gives a notably higher contribution than being lower down. Cumulative Effect: When a result appears in multiple queries with high ranks, the contributions add up, boosting its overall score. Conversely, if a result is ranked poorly in several queries, its cumulative contribution will be relatively small. 1-3 Example Assume we have two queries and we use (k=60)( k = 60 )(k=60) . Query 1: The result (R)( R )(R) is ranked 1st. Query 2: The same result (R)( R )(R) is ranked 3rd. We will calculate the RRF score for (R)( R )(R) . From Query 1: Contribution1=160+1=161≈0.01639\text{Contribution}_1 = \frac{1}{60 + 1} = \frac{1}{61} \approx 0.01639 Contribution1=60+11=611≈0.01639 From Query 2: Contribution2=160+3=163≈0.01587\text{Contribution}_2 = \frac{1}{60 + 3} = \frac{1}{63} \approx 0.01587 Contribution2=60+31=631≈0.01587 Overall RRF Score: RRF(R)=0.01639+0.01587≈0.03226\text{RRF}(R) = 0.01639 + 0.01587 \approx 0.03226 RRF(R)=0.01639+0.01587≈0.03226 Now, compare this with another document, say (S)( S )(S) , with ranks 5 in both queries: Query 1: (rS(1)=5)( r_S(1) = 5 )(rS(1)=5) Contribution1=160+5=165≈0.01538\text{Contribution}_1 = \frac{1}{60 + 5} = \frac{1}{65} \approx 0.01538 Contribution1=60+51=651≈0.01538 Query 2: (rS(2)=5)( r_S(2) = 5 )(rS(2)=5) Contribution2=160+5=165≈0.01538\text{Contribution}_2 = \frac{1}{60 + 5} = \frac{1}{65} \approx 0.01538 Contribution2=60+51=651≈0.01538 Overall RRF Score: RRF(S)=0.01538+0.01538≈0.03076\text{RRF}(S) = 0.01538 + 0.01538 \approx 0.03076 RRF(S)=0.01538+0.01538≈0.03076 In this example, document (R)( R )(R) receives a slightly higher RRF score than document (S)( S )(S) because its ranks (1st and 3rd) indicate more consistent high performance across queries. 2- Distribution-Based Score Fusion (DBSF) How it Works: DBSF takes a different approach by working with the actual scores assigned to each result. What It Does: For each query, it normalizes the scores by using a statistical approach—employing the mean and the third standard deviation as limits. This normalization makes each query’s scores comparable to the others. Then, it sums up the normalized scores for the same result across different queries, yielding a final composite score that reflects the overall relevance. Let's break down the explanation with an example and formulas step by step. 2-1 Step 1: Normalizing the Scores for a Single Query For each query, assume you have several scores. To bring them to a common scale (0 to 1), we use the following approach: Calculate the Mean and Standard Deviation. Let: (μ)( \mu )(μ) be the mean (average)

In Qdrant - a vector database used in machine learning applications - there are two primary strategies for combining (or "fusing") query results so that consistently strong performers are prioritized.
I have already written a medium story about RRF and DBSF, giving a high level explanation on them. so you can read it here. in this article, focus is more on math
behind these methods. let's get started!
1- Reciprocal Rank Fusion (RRF)
How it Works: RRF is a rank-based method. It looks at where each result is positioned in every query's list.
What It Does: If a particular result appears near the top in multiple queries, RRF boosts its overall ranking. The key idea is that results which are consistently ranked high across different queries are more likely to be relevant.
Reciprocal Rank Fusion (RRF) is a method that combines search results by focusing solely on the positions (or ranks) where they appear in each query’s result list. Instead of relying on the raw scores assigned to each result, RRF rewards results that consistently appear higher up in the rankings. Here’s how it works with formulas and an example:
1-1 The RRF Formula
For a given result
(r)( r ) (r)
that appears across multiple queries, the RRF score is calculated using the formula:
where:
- (N)( N ) (N) is the number of queries.
- (ri(r))( r_i(r) ) (ri(r)) is the rank (position) of result (r)( r ) (r) in the (i)( i ) (i) -th query (with the best rank being 1).
- (k)( k ) (k) is a constant (often set to around 60) used to dampen the effect of very high rankings and ensure that the contribution of lower-ranked results is reduced.
This formula means that a result that appears at a higher rank (i.e., with a smaller rank number) in a query will contribute a larger amount to the overall RRF score.
1-2 How It Boosts Results
- Rank Impact: If a result is ranked first in a query, its contribution is (1k+1)( \frac{1}{k+1} ) (k+11) . If it ranks second, the contribution is (1k+2)( \frac{1}{k+2} )(k+21) , and so on. Therefore, being ranked high (e.g., first or second) gives a notably higher contribution than being lower down.
- Cumulative Effect: When a result appears in multiple queries with high ranks, the contributions add up, boosting its overall score. Conversely, if a result is ranked poorly in several queries, its cumulative contribution will be relatively small.
1-3 Example
Assume we have two queries and we use (k=60)( k = 60 )(k=60) .
- Query 1: The result (R)( R )(R) is ranked 1st.
- Query 2: The same result (R)( R )(R) is ranked 3rd.
We will calculate the RRF score for (R)( R )(R) .
-
From Query 1:
Contribution1=160+1=161≈0.01639\text{Contribution}_1 = \frac{1}{60 + 1} = \frac{1}{61} \approx 0.01639 Contribution1=60+11=611≈0.01639
-
From Query 2:
Contribution2=160+3=163≈0.01587\text{Contribution}_2 = \frac{1}{60 + 3} = \frac{1}{63} \approx 0.01587 Contribution2=60+31=631≈0.01587
-
Overall RRF Score:
RRF(R)=0.01639+0.01587≈0.03226\text{RRF}(R) = 0.01639 + 0.01587 \approx 0.03226 RRF(R)=0.01639+0.01587≈0.03226
Now, compare this with another document, say (S)( S )(S) , with ranks 5 in both queries:
-
Query 1:
(rS(1)=5)( r_S(1) = 5 )(rS(1)=5)
Contribution1=160+5=165≈0.01538\text{Contribution}_1 = \frac{1}{60 + 5} = \frac{1}{65} \approx 0.01538 Contribution1=60+51=651≈0.01538
-
Query 2:
(rS(2)=5)( r_S(2) = 5 )(rS(2)=5)
Contribution2=160+5=165≈0.01538\text{Contribution}_2 = \frac{1}{60 + 5} = \frac{1}{65} \approx 0.01538 Contribution2=60+51=651≈0.01538
-
Overall RRF Score:
RRF(S)=0.01538+0.01538≈0.03076\text{RRF}(S) = 0.01538 + 0.01538 \approx 0.03076 RRF(S)=0.01538+0.01538≈0.03076
In this example, document (R)( R )(R) receives a slightly higher RRF score than document (S)( S )(S) because its ranks (1st and 3rd) indicate more consistent high performance across queries.
2- Distribution-Based Score Fusion (DBSF)
How it Works: DBSF takes a different approach by working with the actual scores assigned to each result.
What It Does: For each query, it normalizes the scores by using a statistical approach—employing the mean and the third standard deviation as limits. This normalization makes each query’s scores comparable to the others. Then, it sums up the normalized scores for the same result across different queries, yielding a final composite score that reflects the overall relevance.
Let's break down the explanation with an example and formulas step by step.
2-1 Step 1: Normalizing the Scores for a Single Query
For each query, assume you have several scores. To bring them to a common scale (0 to 1), we use the following approach:
-
Calculate the Mean and Standard Deviation.
Let:- (μ)( \mu )(μ) be the mean (average) of all scores in that query.
- (σ)( \sigma )(σ) be the standard deviation of these scores.
-
Determine the Limits.
We set limits for normalization based on three standard deviations from the mean:- Lower Limit: (L=μ−3σ)( L = \mu - 3\sigma )(L=μ−3σ)
- Upper Limit: (U=μ+3σ)( U = \mu + 3\sigma )(U=μ+3σ)
-
Apply Min–Max Normalization.
For a given result with an original score (s)( s )(s) , the normalized score (n)( n )(n) is computed as:
n=s−LU−L=s−(μ−3σ)6σ n = \frac{s - L}{U - L} = \frac{s - (\mu - 3\sigma)}{6\sigma} n=U−Ls−L=6σs−(μ−3σ)However, to ensure the normalized value stays between 0 and 1, we “clamp” it:n={0,if s
This process helps standardize the scores from each query, making them directly comparable even if their original scales differ.
2-2 Step 2: Aggregating Scores Across Multiple Queries
Once each query has produced normalized scores for its results, we want to combine the strength of a result that appears in several queries. This is done by simply summing the normalized scores for that result across all queries. That is, if a result appears in (Q)( Q )(Q) different queries and obtains normalized scores (n1,n2,…,nQ)( n_1, n_2, \ldots, n_Q )(n1,n2,…,nQ) , its final composite score (Sfinal)( S_{\text{final}} )(Sfinal) is given by:
2-3 Example
Imagine we have two queries, Query A and Query B, and a specific result (R)( R )(R) appears in both queries.
-
For Query A:
-
Given:
- Mean (μA=15)( \mu_A = 15 )(μA=15) and StandardDeviation (σA=3)( \sigma_A = 3 )(σA=3)
- Thus, the lower limit is (LA=15−3×3=6)( L_A = 15 - 3 \times 3 = 6 )(LA=15−3×3=6)
- And the upper limit is (UA=15+3×3=24)( U_A = 15 + 3 \times 3 = 24 )(UA=15+3×3=24)
- Result (R)( R )(R) Score: (sA=18)( s_A = 18 )(sA=18)
-
Normalized Score Calculation:
nA=18−624−6=1218≈0.667n_A = \frac{18 - 6}{24 - 6} = \frac{12}{18} \approx 0.667 nA=24−618−6=1812≈0.667
-
Given:
For Query B:
-
Given:
- Mean (μB=35)( \mu_B = 35 )(μB=35) and Standard Deviation (σB=5)( \sigma_B = 5 )(σB=5)
- The lower limit is (LB=35−3×5=20)( L_B = 35 - 3 \times 5 = 20 )(LB=35−3×5=20)
- The upper limit is (UB=35+3×5=50)( U_B = 35 + 3 \times 5 = 50 )(UB=35+3×5=50)
Result (R)Score:(sB=40)( R ) Score: ( s_B = 40 )(R)Score:(sB=40)
-
Normalized Score Calculation:
nB=40−2050−20=2030≈0.667n_B = \frac{40 - 20}{50 - 20} = \frac{20}{30} \approx 0.667 nB=50−2040−20=3020≈0.667Aggregating the Scores:
For the final composite score for result (R)( R )(R) across both queries:
Sfinal=nA+nB=0.667+0.667≈1.334 S_{\text{final}} = n_A + n_B = 0.667 + 0.667 \approx 1.334 Sfinal=nA+nB=0.667+0.667≈1.334This composite score (Sfinal)( S_{\text{final}} )(Sfinal) reflects the overall relevance of (R)( R )(R) by combining evidence from multiple queries on a common normalized scale.
This method ensures that each query’s scores are normalized to a standard scale, making it fair and consistent to add them together and highlight results that perform well across different queries.
Summary
RRF Method:
RRF doesn’t look at raw scores; it solely relies on the rank positions. Results that appear near the top in multiple queries are rewarded with a higher cumulative score. This approach helps ensure that consistently high-ranked results across various query contexts are deemed more relevant overall.
Formula Recap:
RRF(r)=∑i=1N1k+ri(r) \text{RRF}(r) = \sum_{i=1}^{N} \frac{1}{k + r_i(r)} RRF(r)=i=1∑Nk+ri(r)1DBSF Method:
This approach ensures that the scores from different queries are comparable, and that consistently high-scoring results are emphasized when their scores are summed.
Normalization Formula (for one query):
n=min(max(s−(μ−3σ)6σ, 0), 1) n = \min\left(\max\left(\frac{s - (\mu - 3\sigma)}{6\sigma},\, 0\right),\, 1\right) n=min(max(6σs−(μ−3σ),0),1)Final Aggregated Score (across queries):
Sfinal=∑q∈queriesnq S_{\text{final}} = \sum_{q \in \text{queries}} n_{q} Sfinal=q∈queries∑nq