





























































![Apple to Craft Key Foldable iPhone Components From Liquid Metal [Kuo]](https://www.iclarified.com/images/news/96784/96784/96784-640.jpg)

![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)
















































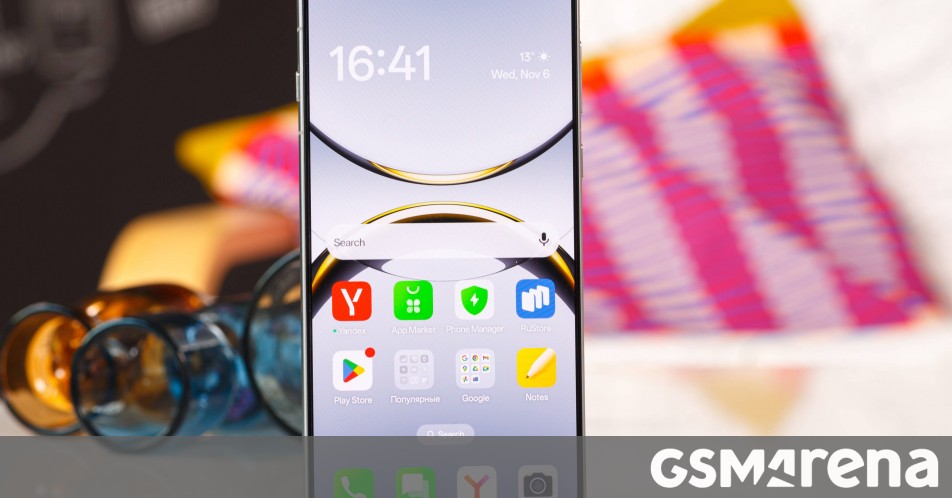
























































_Federico_Caputo_Alamy.jpg?#)
































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)

















































































































![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)

































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





.png?#)













































Decoding Text Like a Transformer: Mastering Byte-Pair Encoding (BPE) Tokenization
# Decoding Text Like a Transformer: Mastering Byte-Pair Encoding (BPE) Tokenization In the ever-evolving landscape of Natural Language Processing (NLP), language models are reshaping how machines interact with human language. The magic begins with **tokenization**, the foundational process of dissecting text into meaningful units — **tokens** — that these models can understand and learn from. While straightforward word-based tokenization might seem like the natural starting point, it quickly encounters limitations when faced with the vastness, complexities, and nuances inherent in human language. Enter **Byte-Pair Encoding (BPE)**, a subword tokenization technique that has become a cornerstone of modern NLP. Powering models like GPT, BERT, RoBERTa, and countless Transformer architectures, BPE offers an ingenious balance: efficient vocabulary compression and the ability to gracefully handle out-of-vocabulary (OOV) words. This article isn't just another surface-level explanation of BPE. We'll embark on a deep dive, not only to grasp how BPE functions, from the initial training phase to the final tokenization step, but also to rectify a widespread misconception about how BPE is applied to new, unseen text. Prepare to truly master this essential NLP technique. For a hands-on, interactive learning experience, be sure to explore our Colab Notebook: [Build and Push a Tokenizer](COLAB_NOTEBOOK_LINK_HERE - Remember to replace with the actual link to your Colab Notebook!) where you can train your very own BPE tokenizer and witness its power in action. ## What Makes Byte-Pair Encoding (BPE) So Powerful? Imagine the challenge of creating a vocabulary for a language model. A simplistic approach might be to include every single word from your training data. However, this quickly leads to an unmanageable vocabulary size, especially when working with massive datasets. Furthermore, what happens when the model encounters a word it has never seen during training — an out-of-vocabulary (OOV) word? Traditional word-based tokenization falters here. BPE offers an elegant solution by shifting focus from whole words to **subword units**. Instead of solely relying on words, BPE learns to recognize and utilize frequently occurring character sequences — subwords — as tokens. This clever strategy unlocks several key advantages: - **Vocabulary Efficiency**: BPE dramatically reduces vocabulary size compared to word-based approaches, enabling models to be more memory-efficient and train faster. - **Out-of-Vocabulary Word Mastery**: By breaking down words into subword tokens, BPE empowers models to process and understand even unseen words. The model can infer meaning from the combination of familiar subwords. - **Semantic Substructure Capture**: Subwords often carry inherent semantic meaning (prefixes like "un-", suffixes like "-ing", "-ly"). BPE's subword approach allows models to capture these meaningful components, leading to a richer understanding of word relationships. - **Cross-Lingual Adaptability**: BPE is remarkably language-agnostic and performs effectively across diverse languages, including those with complex morphology or without clear word boundaries (like Chinese or Finnish). ## Training Your BPE Tokenizer: A Hands-On Walkthrough The BPE training process is an iterative, data-driven journey, where the algorithm learns the most efficient subword representations directly from your text corpus. Let's break down the steps with a practical example, using the classic sentence: "the quick brown fox jumps over the lazy dog". ### Step 1: Initialize Tokens as Individual Characters (and Bytes!) We begin by treating each unique character in our training corpus as a fundamental token. For "the quick brown fox jumps over the lazy dog", the initial tokens would be characters: ['t', 'h', 'e', ' ', 'q', 'u', 'i', 'c', 'k', ' ', 'b', 'r', 'o', 'w', 'n', ' ', 'f', 'o', 'x', ' ', 'j', 'u', 'm', 'p', 's', ' ', 'o', 'v', 'e', 'r', ' ', 't', 'h', 'e', ' ', 'l', 'a', 'z', 'y', ' ', 'd', 'o', 'g'] Our initial vocabulary starts with these characters: [' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'] In real-world applications, especially for models like GPT-2 and RoBERTa, byte-level BPE is often employed for enhanced robustness. Byte-level BPE uses bytes as the initial vocabulary, ensuring that any possible character can be represented from the outset. This eliminates the problem of encountering truly "unknown" characters later on. ### Step 2: Count Pair Frequencies: Finding Common Token Partners Next, we analyze our corpus to determine the frequency of adjacent token pairs. We count how often each pair of consecutive tokens appears. For instance, in our example sentence, we'd count pairs like ('t', 'h'), ('h', 'e'), ('e', ' '), (' ', 'q'), and so on, across the entire (potentially larger) training corpus. Let's imagine we've pro

# Decoding Text Like a Transformer: Mastering Byte-Pair Encoding (BPE) Tokenization
In the ever-evolving landscape of Natural Language Processing (NLP), language models are reshaping how machines interact with human language. The magic begins with **tokenization**, the foundational process of dissecting text into meaningful units — **tokens** — that these models can understand and learn from.
While straightforward word-based tokenization might seem like the natural starting point, it quickly encounters limitations when faced with the vastness, complexities, and nuances inherent in human language. Enter **Byte-Pair Encoding (BPE)**, a subword tokenization technique that has become a cornerstone of modern NLP. Powering models like GPT, BERT, RoBERTa, and countless Transformer architectures, BPE offers an ingenious balance: efficient vocabulary compression and the ability to gracefully handle out-of-vocabulary (OOV) words.
This article isn't just another surface-level explanation of BPE. We'll embark on a deep dive, not only to grasp how BPE functions, from the initial training phase to the final tokenization step, but also to rectify a widespread misconception about how BPE is applied to new, unseen text. Prepare to truly master this essential NLP technique.
For a hands-on, interactive learning experience, be sure to explore our Colab Notebook: [Build and Push a Tokenizer](COLAB_NOTEBOOK_LINK_HERE - Remember to replace with the actual link to your Colab Notebook!) where you can train your very own BPE tokenizer and witness its power in action.
## What Makes Byte-Pair Encoding (BPE) So Powerful?
Imagine the challenge of creating a vocabulary for a language model. A simplistic approach might be to include every single word from your training data. However, this quickly leads to an unmanageable vocabulary size, especially when working with massive datasets. Furthermore, what happens when the model encounters a word it has never seen during training — an out-of-vocabulary (OOV) word? Traditional word-based tokenization falters here.
BPE offers an elegant solution by shifting focus from whole words to **subword units**. Instead of solely relying on words, BPE learns to recognize and utilize frequently occurring character sequences — subwords — as tokens. This clever strategy unlocks several key advantages:
- **Vocabulary Efficiency**: BPE dramatically reduces vocabulary size compared to word-based approaches, enabling models to be more memory-efficient and train faster.
- **Out-of-Vocabulary Word Mastery**: By breaking down words into subword tokens, BPE empowers models to process and understand even unseen words. The model can infer meaning from the combination of familiar subwords.
- **Semantic Substructure Capture**: Subwords often carry inherent semantic meaning (prefixes like "un-", suffixes like "-ing", "-ly"). BPE's subword approach allows models to capture these meaningful components, leading to a richer understanding of word relationships.
- **Cross-Lingual Adaptability**: BPE is remarkably language-agnostic and performs effectively across diverse languages, including those with complex morphology or without clear word boundaries (like Chinese or Finnish).
## Training Your BPE Tokenizer: A Hands-On Walkthrough
The BPE training process is an iterative, data-driven journey, where the algorithm learns the most efficient subword representations directly from your text corpus. Let's break down the steps with a practical example, using the classic sentence: "the quick brown fox jumps over the lazy dog".
### Step 1: Initialize Tokens as Individual Characters (and Bytes!)
We begin by treating each unique character in our training corpus as a fundamental token. For "the quick brown fox jumps over the lazy dog", the initial tokens would be characters:
['t', 'h', 'e', ' ', 'q', 'u', 'i', 'c', 'k', ' ', 'b', 'r', 'o', 'w', 'n', ' ', 'f', 'o', 'x', ' ', 'j', 'u', 'm', 'p', 's', ' ', 'o', 'v', 'e', 'r', ' ', 't', 'h', 'e', ' ', 'l', 'a', 'z', 'y', ' ', 'd', 'o', 'g']
Our initial vocabulary starts with these characters:
[' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
In real-world applications, especially for models like GPT-2 and RoBERTa, byte-level BPE is often employed for enhanced robustness. Byte-level BPE uses bytes as the initial vocabulary, ensuring that any possible character can be represented from the outset. This eliminates the problem of encountering truly "unknown" characters later on.
### Step 2: Count Pair Frequencies: Finding Common Token Partners
Next, we analyze our corpus to determine the frequency of adjacent token pairs. We count how often each pair of consecutive tokens appears. For instance, in our example sentence, we'd count pairs like ('t', 'h'), ('h', 'e'), ('e', ' '), (' ', 'q'), and so on, across the entire (potentially larger) training corpus.
Let's imagine we've processed a larger corpus and found the following pair frequencies (simplified for illustration):
- ('t', 'h'): 15 times
- ('e', ' '): 20 times
- ('q', 'u'): 10 times
### Step 3: Merge the Most Frequent Pair: Creating Subwords
The core of BPE training is the iterative merging of the most frequent token pair. Let's say, in our hypothetical frequency count, the pair ('e', ' ') is the most frequent. We create a new, merged token "e " (note the space) and update our vocabulary to include it.
### Step 4: Iterate and Build Merge Rules: Growing the Vocabulary
We repeat steps 2 and 3. In each iteration, we recalculate pair frequencies based on the updated corpus (which now includes merged tokens like "e "). We then identify the new most frequent pair (considering both original characters and previously merged tokens) and merge it. We also record the merge rule, for example: ('e', ' ') -> 'e '.
This iterative process continues until we reach a predefined vocabulary size or complete a set number of merge operations. The outcome is a vocabulary consisting of initial characters and learned subword tokens, along with an ordered list of merge rules, reflecting the sequence in which merges were learned.
### Python Example for BPE Training
python
from collections import defaultdict
Example corpus (imagine it's larger in reality)
corpus = [
"the quick brown fox jumps over the lazy dog",
"the slow black cat sits under the warm sun",
"the fast white rabbit runs across the green field",
]
1. Initialize word frequencies (using simple splitting for this example)
word_freqs = defaultdict(int)
for text in corpus:
for word in text.split(): # Simplistic split for demonstration
word_freqs[word] += 1
2. Initial Splits and Vocabulary (characters)
splits = {word: [char for char in word] for word in word_freqs.keys()}
alphabet = []
for word in word_freqs.keys():
for char in word:
if char not in alphabet:
alphabet.append(char)
alphabet.sort()
vocab = alphabet.copy() # Start vocab with alphabet
3. Function to compute pair frequencies (from previous tutorial)
def compute_pair_freqs(splits, word_freqs):
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
4. Function to merge pairs (from previous tutorial)
def merge_pair(a, b, splits, word_freqs):
for word in list(word_freqs.keys()):
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2:]
splits[word] = split
i += 1
else:
i += 1
return splits
merges = {} # Store merge rules
vocab_size = 50 # Desired vocab size (example)
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits, word_freqs)
if not pair_freqs:
break
best_pair = max(pair_freqs, key=pair_freqs.get)
splits = merge_pair(*best_pair, splits, word_freqs)
merges[best_pair] = "".join(best_pair)
vocab.append("".join(best_pair))
print("Learned Merges:", merges)
print("Final Vocabulary (partial):", vocab[:20], "...")
✏️ **Your Turn! (Understanding Checkpoint)**
Run the code snippet above (or in the Colab notebook!). Examine the merges dictionary and the vocab. Can you trace how the merge rules were learned based on pair frequencies? What are some of the initial merges you observe?
## Tokenizing New Text: Ordered Merge Rules are Key! (Correcting the Misconception)
With a trained BPE tokenizer and its ordered list of merge rules, we can now tokenize new, unseen text. This is where a critical point of confusion often arises.
### The Common Misconception: Longest-Match Greedy Tokenization (INCORRECT)
A frequently encountered, yet incorrect, description of BPE tokenization is a greedy, left-to-right longest-match approach. This flawed idea suggests that you scan the input text and try to find the longest possible substring that directly matches a token in your BPE vocabulary. This is fundamentally wrong and disregards the crucial order of learned merge rules.
### The Correct BPE Tokenization Algorithm: Sequential Rule Application
The accurate BPE tokenization method strictly adheres to the ordered sequence of merge rules learned during training. Here's the precise process:
1. **Initial Splitting**: Start by splitting the input word (or text, pre-tokenized into words) into individual characters (or bytes in byte-level BPE).
2. **Sequential Rule Application**: Iterate through your ordered list of merge rules. For each rule, scan through the current list of tokens and apply the merge wherever the rule's token pair is found. It's vital to apply one complete merge rule before moving on to the next rule in the ordered list.
3. **Repeat Until Exhausted**: Continue applying the merge rules, in order, until no more rules from your list can be applied to the current token sequence.
### Example: Tokenizing "tokenization" (Correct Method)
Initial split:
`['t', 'o', 'k', 'e', 'n', 'i', 'z', 'a', 't', 'i', 'o', 'n']`
Apply Rule 1: `('t', 'o') -> 'to'`
Result: `['to', 'k', 'e', 'n', 'i', 'z', 'a', 't', 'i', 'o', 'n']`
Apply Rule 2: `('k', 'e') -> 'ke'`
Result: `['to', 'ke', 'n', 'i', 'z', 'a', 't', 'i', 'o', 'n']`
Apply Rule 3: `('ke', 'n') -> 'ken'`
Result: `['to', 'ken', 'i', 'z', 'a', 't', 'i', 'o', 'n']`
Apply Rule 4: `('to', 'ken') -> 'token'`
Result: `['token', 'i', 'z', 'a', 't', 'i', 'o', 'n']`
Apply Rule 5: `('token', 'ization') -> 'tokenization'`
Result: `['token', 'ization']`
Final Tokens: `['token', 'ization']`
Contrast this with the incorrect longest-match approach. A longest-match algorithm might incorrectly tokenize "tokenization" as just "tokenization" if it happens to be in the vocabulary, even if the merge rules would have broken it down into `["token", "ization"]`. This highlights why understanding and implementing the ordered rule application is crucial for true BPE tokenization.
## Advantages of BPE: Reaping the Benefits
- **Vocabulary Efficiency**: BPE significantly reduces vocabulary size, making models more compact and faster to train.
- **Out-of-Vocabulary Robustness**: Handles unseen words gracefully by decomposing them into known subword units.
- **Linguistic Insight**: Captures meaningful subword components, enhancing the model's understanding of word structure and semantics.
- **Language Versatility**: Adaptable to diverse languages and linguistic structures.
## Conclusion: Mastering BPE — Tokenization Done Right
Byte-Pair Encoding is a cornerstone of modern NLP, enabling efficient and robust text processing for today's powerful language models. By understanding the correct training and, crucially, the ordered, rule-based tokenization process, you unlock a deeper appreciation for how these models process and interpret the nuances of human language.
Don't be misled by the simplified, and incorrect, longest-match tokenization description. Embrace the sequential, rule-driven approach of BPE to truly master this essential subword tokenization technique.
### Further Exploration:
- **Neural Machine Translation of Rare Words with Subword Units**
- **Tokenization Is More Than Compression**
- **Scaffold-BPE: Enhancing Byte Pair Encoding for Large Language Models with Simple
Embedding Initialization**
Keep learning and keep experimenting with BPE—your journey to mastering NLP starts here!







