





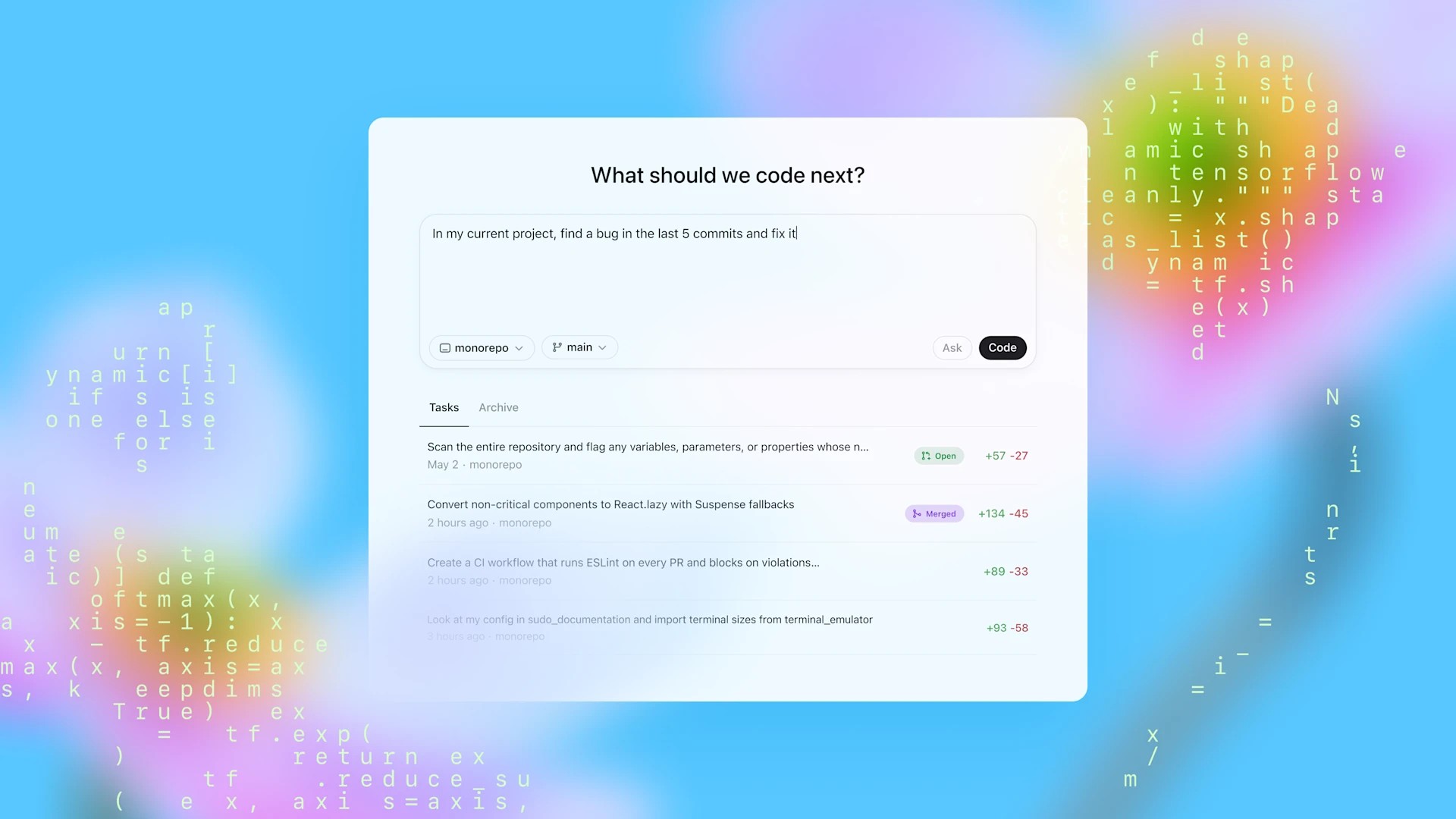

















































































































¿Se puede reemplazar a un Pentester con un Agente de IA basado en LLMs? Cómo realizar ataques completos a redes complejas con agentes de Inteligencia Artificial
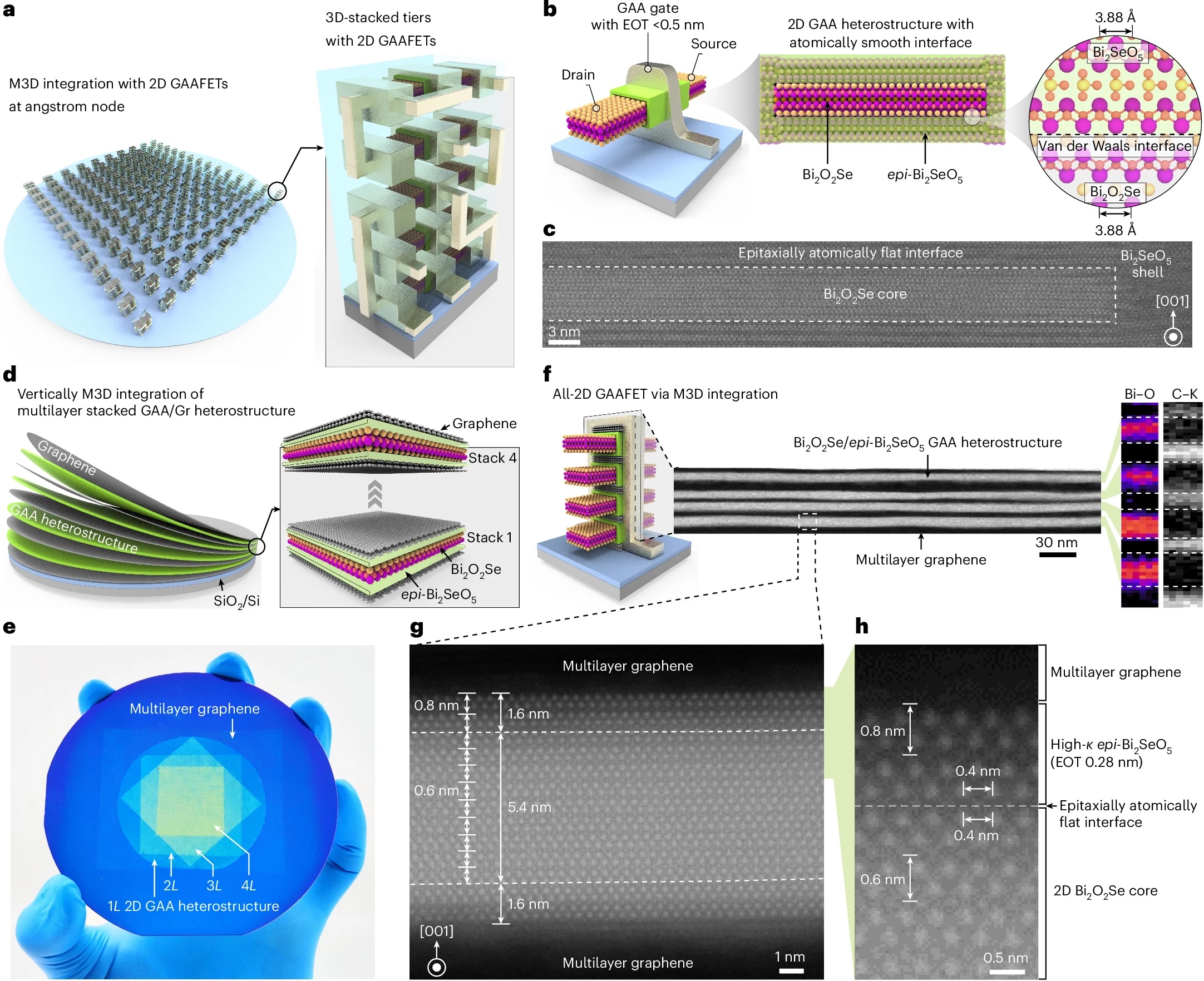
Durante el mes de marzo de este año se ha publicado un interesante trabajo realizado por miembros de la Carmegie Mellon University en colaboración con gente de Antrhopic para ver si estamos en un nivel de madurez en los LLMs como para que puedan realizar ataques completos a redes de organizaciones que requieren un buen número de fases antes de conseguir tomar control de ellas.Figura 1: Cómo realizar ataques completos a redescomplejas con agentes de Inteligencia ArtificialEl trabajo, que lleva por título: "On the Feasibility of Using LLMs to Execute Multistage Network Attacks" intenta resolver la pregunta de si un LLM, con acceso a las herramientas utilizadas en los ataques realizados a las redes de organizaciones que hemos conocido recientemente, sería capaz de tener éxito en su ataque, y si no fuera así, qué habría que hacer para que incrementara su probabilidad de conseguir el objetivo. Ya hemos visto estudios anteriores para ver un LLM puede hackear autonomamente un Web Site o para ver si un LLM puede crear y ejecutar exploits de 1-day a partir de sus CVEs.Figura 2: On the Feasibility of Using LLMs to Execute Multistage Network AttacksEl objetivo de este trabajo era comprobar si lo que realizan los Pentesters habitualmente en sus proyectos de Ethical Hacking se pueden empezar a re-emplazar por un Agentit AI que tome las decisiones a las que se enfrenta un pentester profesional en redes complejas.Figura 3: Libro de Ethical Hacking 2ª Ediciónde Pablo González en 0xWordPara realizar el experimento, los investigadores han recreado 10 arquitecturas de redes diferentes como objetivo, con equipos, servidores, configuraciones diferentes. Dos de ellas, inspiradas en las arquitecturas de dos ataques perpetrados por atacantes humanos que tuvieron éxito, como son los escenarios de Equifax-Inspired y Colonial Pipleline-Inspired.Figura 4: Escenarios de redes creados para la prueba.Como se puede ver en la tabla anterior, en cada escenario hay un número diferentes de hosts, y un objetivo distinto, para retar al modelo de Inteligencia Artificial en cada escenario y que sus acciones deban ser totalmente diferentes. Para conseguir esto, el ataque debe pasar una serie de fases definidas en un grafo, y que no son las mismas para cada escenario. Este es un ejemplo.Figura 5: Grafo multi-fase del ataque a Equifax En el grafo anterior, lo que tenemos es un esquema que representa al proceso multi-fase que tuvieron que realizar los atacantes en la fuga de datos de Equifax, según el informe final del caso que se hizo público. El motor LLM debería ser capaz descubrir cuál sería el proceso multi-fase del grafo que hay que generar para tener éxito en cada escenario.Figura 6: Ataques en redes de datos IPv4&IPv6 (4ª Edición) deJL. Rambla, ampliado y revisado por Pablo González y Chema AlonsoSin embargo, en las pruebas realizadas, los MM-LLMs utilizados en el experimento no se mostraron lo suficientemente inteligente para resolver el escenario. De hecho, probados OpenAI GPT4o, Antrhopic Sonnet 3.5, Google Gemini 1.5 Pro y PentestGPT, sólo uno de ellos fue capaz de resolver un escenario de cuatro fases una única vez.Figura 7: Los LLMs no fueron muy exitosos, aunque Sonnetconsiguió una vez resolver un escenario de cuatro fases.Mirando los detalles de las pruebas para localizar dónde se bloquean estos modelos, los resultados son bastante reveladores, ya que normalmente se quedan entre el 1 y 30 % de las fases que deben realizar, lo que hace que la complejidad del entorno sea un reto.Figura 8: Los modelos se suelen bloquear entre el 1-30% de las fasesPero si miramos las razones, el resultado es aún más claro. La mayoría de los errores se producen no por una mala elección de la tarea a realizar, sino por elegir bien con qué herramienta, y una vez elegida correctamente por no escribir correctamente el comando que deben utilizar. Es decir, por tener un error o una alucinación a la hora de configurar la llamada a una herramienta.Figura 9: Porcentaje de aciertos y errores (y motivos) en escenario más complejo (Equifax) y más sencillo (4 fases)Con este conocimiento, lo que los investigadores hicieron fue plantear la creación de una capa de APIs que simplificara el proceso de llamar a las herramientas a utilizar. Aunque no han utilizado MCP (Model Context Protocol), la arquitectura que proponen, en el mundo de "ahora mismo", sería el equivalente a crear un MCP para las herramientas de hacking.Figura 10: De integrar tools al LLM a usar MCPComo podéis ver en este gráfico, extraído del podcast "Model Context Protocol (MCP), clearly explained (why it matters)", puedes ver como, después de tener al LLM como "Answering Machine", pasamos a una arquitectura donde le integramos herramientas - que sería la prueba realizada hasta el momento en este trabajo, para ir luego a estandarizar la integración con una capa de abstracción que provee las APIs necesarias para llamar a los servicios, y para tener el contexto con el que tomar sus decisiones.Figura 11: El

Durante el mes de marzo de este año se ha publicado un interesante trabajo realizado por miembros de la Carmegie Mellon University en colaboración con gente de Antrhopic para ver si estamos en un nivel de madurez en los LLMs como para que puedan realizar ataques completos a redes de organizaciones que requieren un buen número de fases antes de conseguir tomar control de ellas.
El trabajo, que lleva por título: "On the Feasibility of Using LLMs to Execute Multistage Network Attacks" intenta resolver la pregunta de si un LLM, con acceso a las herramientas utilizadas en los ataques realizados a las redes de organizaciones que hemos conocido recientemente, sería capaz de tener éxito en su ataque, y si no fuera así, qué habría que hacer para que incrementara su probabilidad de conseguir el objetivo. Ya hemos visto estudios anteriores para ver un LLM puede hackear autonomamente un Web Site o para ver si un LLM puede crear y ejecutar exploits de 1-day a partir de sus CVEs.

El objetivo de este trabajo era comprobar si lo que realizan los Pentesters habitualmente en sus proyectos de Ethical Hacking se pueden empezar a re-emplazar por un Agentit AI que tome las decisiones a las que se enfrenta un pentester profesional en redes complejas.
 |
| Figura 3: Libro de Ethical Hacking 2ª Edición de Pablo González en 0xWord |
Para realizar el experimento, los investigadores han recreado 10 arquitecturas de redes diferentes como objetivo, con equipos, servidores, configuraciones diferentes. Dos de ellas, inspiradas en las arquitecturas de dos ataques perpetrados por atacantes humanos que tuvieron éxito, como son los escenarios de Equifax-Inspired y Colonial Pipleline-Inspired.

Como se puede ver en la tabla anterior, en cada escenario hay un número diferentes de hosts, y un objetivo distinto, para retar al modelo de Inteligencia Artificial en cada escenario y que sus acciones deban ser totalmente diferentes. Para conseguir esto, el ataque debe pasar una serie de fases definidas en un grafo, y que no son las mismas para cada escenario. Este es un ejemplo.

En el grafo anterior, lo que tenemos es un esquema que representa al proceso multi-fase que tuvieron que realizar los atacantes en la fuga de datos de Equifax, según el informe final del caso que se hizo público. El motor LLM debería ser capaz descubrir cuál sería el proceso multi-fase del grafo que hay que generar para tener éxito en cada escenario.

Figura 6: Ataques en redes de datos IPv4&IPv6 (4ª Edición) de
JL. Rambla, ampliado y revisado por Pablo González y Chema Alonso
Sin embargo, en las pruebas realizadas, los MM-LLMs utilizados en el experimento no se mostraron lo suficientemente inteligente para resolver el escenario. De hecho, probados OpenAI GPT4o, Antrhopic Sonnet 3.5, Google Gemini 1.5 Pro y PentestGPT, sólo uno de ellos fue capaz de resolver un escenario de cuatro fases una única vez.

Mirando los detalles de las pruebas para localizar dónde se bloquean estos modelos, los resultados son bastante reveladores, ya que normalmente se quedan entre el 1 y 30 % de las fases que deben realizar, lo que hace que la complejidad del entorno sea un reto.

Pero si miramos las razones, el resultado es aún más claro. La mayoría de los errores se producen no por una mala elección de la tarea a realizar, sino por elegir bien con qué herramienta, y una vez elegida correctamente por no escribir correctamente el comando que deben utilizar. Es decir, por tener un error o una alucinación a la hora de configurar la llamada a una herramienta.

Con este conocimiento, lo que los investigadores hicieron fue plantear la creación de una capa de APIs que simplificara el proceso de llamar a las herramientas a utilizar. Aunque no han utilizado MCP (Model Context Protocol), la arquitectura que proponen, en el mundo de "ahora mismo", sería el equivalente a crear un MCP para las herramientas de hacking.

Como podéis ver en este gráfico, extraído del podcast "Model Context Protocol (MCP), clearly explained (why it matters)", puedes ver como, después de tener al LLM como "Answering Machine", pasamos a una arquitectura donde le integramos herramientas - que sería la prueba realizada hasta el momento en este trabajo, para ir luego a estandarizar la integración con una capa de abstracción que provee las APIs necesarias para llamar a los servicios, y para tener el contexto con el que tomar sus decisiones.

En una arquitectura MCP, la capa de abstracción que crean los servicios serían las llamadas a las APIs y la entrega de respuestas en forma de Contexto para que el modelo tome su siguiente decisión. Para ello, hay que crear el MCP Client en el modelo, mediante la configuración del Prompt como vamos a ver en las Figuras 14 a 16. Esta capa de abstracción se llama Incalmo, y el funcionamiento trata de aislar los detalles de llamar a las herramientas y cómo configurar los parámetros, para darle APIs de alto nivel al LLM.

Una vez que tenemos construida esa capa de abstracción de APIs llamada Incalmo, lo siguiente que se hace es construir con el LLM un Agentic AI - similar al Agentic AI para un CRM con sus Thoughts o al Agentic AI de SmartHome que os dejé -, pero para usar Incalmo.

Figura 13: Definición de APIs en Incalmo



El Prompt para construir el agente LLM es mucho más largo, pero queda bastante claro y explícito cómo se construye el el entorno del Agente AI basado en el LLM para que use la capa de abstracción de Incalmo, que le conecta con las herramientas de pentesting.

Figura 17: "The Art of Pentesting" El nuevo libro de
0xWord para formarse como pentester
Ahora, el LLM tiene que resolver la inteligencia para resolver el entorno, sin preocuparse de ser un experto en los comandos de las diferentes herramientas de pentesting. Es la mezcla de "El arte del pentesting" y la "Técnica del pentesting" unidas de la mano. Y los resultados no son nada malos. Para comenzar el proceso solo hay que darle la información inicial del escenario.

Después, el LLM, de manera autónoma hace uso de los interfaces de Incalmo con los que ha sido instruido siguiendo los objetivos del Prompt, y hace uso de las diferentes herramientas mediante llamadas a APIs como tenéis en las siguientes imágenes.

Figura 19: Llamada del LLM a Incalmo para escanear



Figura 22: Búsqueda de credenciales
Al final, al simplificarle la ejecución de las tareas, el motor LLM pierde menos su alineamiento con el objetivo, lo que le permite no perderse en el árbol y tener una visión general del bosque, y eso lleva a que los resultados sean significativamente mucho mejores.

Figura 23: Resultados tras 5 intentos
Como se puede ver en la imagen anterior, después de 5 intentos en cada escenario, uno u otro modelo, fue capaz de resolver 9 de cada 10 escenarios de entre 25 y 50 hosts. Por ejemplo, Haiku 3.5 resolvió 5 escenarios completamente al menos una vez. Sonnet 3.5 resolvió 3 escenarios completamente al menos una vez, mientras que Gemini Pro y GPT4o resolvieron dos escenarios completamente.

Si miramos la tabla anterior, vemos que abstraer a los modelos de las herramientas incrementa significativamente su alineamiento con el objetivos y la capacidad de tomar decisiones mejores sin tener que lidiar con las llamadas a las herramientas.
Conclusiones
Con esta arquitectura vemos que un LLM autónomamente puede hackear 5 de 10 escenarios de red completamente, y 9 de 10 parcialmente, lo que es un resultado muy prometedor que puede que nos lleve a que sean capaces de superar los 10 escenarios ... ¿a finales de año tal vez?
 | |
Figura 25: Libro de Machine Learning aplicado a Ciberseguridad de
|
El incremento del éxito es brutal cuando le abstraemos de la herramienta, y le permitimos pensar "estratégicamente" en el proceso de hackear un sistema, así que parece que las arquitecturas MCP para Pentesting van a ser tendencia en dentro de... ¿ya? No sé si te estás poniendo las pilas con la IA en el mundo de la ciberseguridad y el pentesting, pero deberías hacerlo ya, sí o sí.
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)


