














































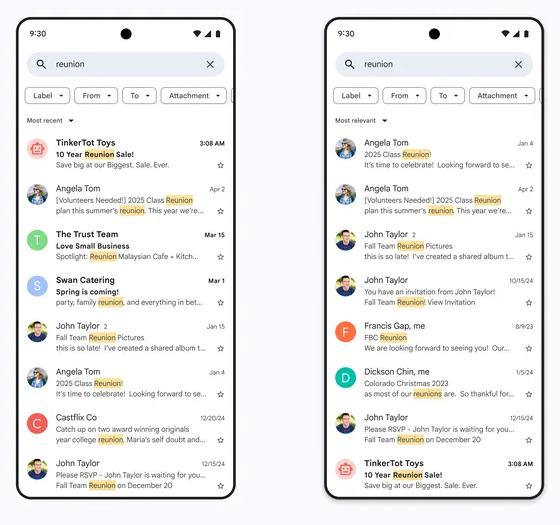















![Apple to Craft Key Foldable iPhone Components From Liquid Metal [Kuo]](https://www.iclarified.com/images/news/96784/96784/96784-640.jpg)

![Apple to Focus on Battery Life and Power Efficiency in Future Premium Devices [Rumor]](https://www.iclarified.com/images/news/96781/96781/96781-640.jpg)








































































































_Federico_Caputo_Alamy.jpg?#)
































































![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


![[The AI Show Episode 138]: Introducing GPT-4.5, Claude 3.7 Sonnet, Alexa+, Deep Research Now in ChatGPT Plus & How AI Is Disrupting Writing](https://www.marketingaiinstitute.com/hubfs/ep%20138%20cover.png)

















































































































![From hating coding to programming satellites at age 37 with Francesco Ciulla [Podcast #165]](https://cdn.hashnode.com/res/hashnode/image/upload/v1742585568977/09b25b8e-8c92-4f4b-853f-64b7f7915980.png?#)

































.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





.png?#)













































The AI Copyright Heist: Why Google Wants to Rewrite the Rules—For Itself
The post The AI Copyright Heist: Why Google Wants to Rewrite the Rules—For Itself appeared first on Android Headlines.

Rhinopithecus bieti, also known affectionately by locals as the golden hair monkey, is a primate found in the southern Chinese province of Yunnan. The loss of their habitats has forced these primates to adapt to extreme altitudes with below-freezing temperatures and extremely thin air. As a result, these monkeys have developed unique facial features: vibrant pink lips and the absence of nasal bones, resulting in their “snub-nosed” moniker. They are also considered endangered.
As Tim Flach, photographer and President of the Association of Photographers, puts it, they look like they’ve had cosmetic surgery. Photographing these monkeys was not easy. Flach had to venture into the mountains for days before, by sheer luck or fate, he managed to snap a winning photo that made it into his book.
Flach’s efforts to achieve his masterpieces are similar to those of many artists—photographers, graphic designers, painters, journalists, and novelists—who have gone to painstaking, time-consuming, and costly lengths to achieve their work. They didn’t just press a magic button to make it all happen. But now? Google wants them to hand their creations over—for free.
That’s the essence of Google’s recent policy proposal on artificial intelligence (AI).
Crying out that the AI industry is held back by regulations and copyright law, Google has crafted a policy proposal that puts forth its own ideas on how the AI industry should be governed. Google is spinning a fairy tale, one where it plays the benevolent hero. Except that this proposal favors Google in every single way imaginable. Remember Google’s “don’t be evil” mantra? Turns out, there’s a footnote: “Unless there’s profit to be made.”
Navigating Copyright and Fair Use: Is Google Exploiting Legal Loopholes?
A few years ago, Flach, received a phone call. His work had been “stolen” by AI. Speaking to The Times, Flach didn’t mince words. “This harvesting of our work… it’s the same as a parasite that sucks the light out of its host without invitation.”
He was told that he was one of the most “scraped” artists in the world, another way of saying that companies have used his photos—without his permission—to train their AI systems. In Flach’s case, his photos were used to train Midjourney, an image generator that uses AI to create images on the fly. Adding insult to injury, the system didn’t just steal his work; it let users replicate his entire photographic style with the click of a button.
I reached out to Flach to get his thoughts on Google’s policy proposal. Flach called Google’s policy statement “egregious from a creators’ perspective.”
“For me copyright is the lifeblood of my professional career; it gives me the power and opportunity to control and licence my work, which in turn means that any income I make I can invest back into my business which allows me to carry on photographing and contributing to conservation projects.”
It’s common for artists to sell their styles as presets. Selling presets is a legitimate way for artists to profit from their style. But Google? It doesn’t want to buy presets, it wants to take them without paying a cent under the guise of “balanced copyright rules.”
Google insists that these so-called “balanced copyright rules” are “critical” for AI to unlock scientific and social advances. It also downplays any impact on rightsholders, claiming the harm will be minimal. But the real giveaway? Google’s true concern isn’t fairness: It’s about avoiding “highly unpredictable, imbalanced, and lengthy negotiations.”
Is Fair Use Really Fair?
But this is where it gets tricky. Basic “fair use” law allows the limited use of copyrighted material without obtaining permission. To put it simply: Using an image as my desktop wallpaper? Fair use. Printing and selling a thousand copies? Copyright infringement.
Google will have a hard time defending this, though. A recent ruling in Thomson Reuters v. Ross Intelligence makes that clear. Judge Stephanos Bibas set a precedent: Training AI with copyrighted data is not “fair use.”
But beyond the legal battles, this raises a deeper philosophical question: Is AI truly “learning” from human work, or is it merely replicating it?
“I think the key distinction lies in intent and scale,” Flach tells me. “A budding photographer or student studying Ansel Adams is engaging in a deeply human, interpretative process. They learn, internalise, and then create something new through their own lens—literally and figuratively.”
“AI, on the other hand, doesn’t ‘learn’ in that way. It ingests vast amounts of work, including copyrighted material, and then generates outputs without necessarily transforming it in a way that reflects individual creativity. If an AI is trained on my images and can produce something indistinguishable from my work, is that really learning, or is it replication?”
The Copyright Controversy: Google’s Longstanding Battle with Content Creators
This isn’t the first time Google has been accused of using copyrighted data and profiting from it. Google has long been accused of exploiting copyrighted content—like displaying website snippets in search results. While this made life easier for users, it siphoned traffic away from publishers, cutting into their ad revenue.
This battle escalated in 2024 when a group of artists sued Google, claiming its Imagen AI was trained on their work without permission.
Google isn’t alone in this, either. Getty Images accused Stability AI of scraping millions of images from its website without consent. It’s not just limited to images. The New York Times sued OpenAI and Microsoft for unauthorized use of its articles to train GPT large language models.
But why do these companies risk legal battles just to scrape data? Because, like a well-read scholar, an AI’s intelligence is only as good as its sources.
The accuracy and success of AI models depend on how much data it has been trained on. The more an AI learns how we write and draw, the better it becomes at mimicking us, making it more valuable. Plus, there’s only so much truly “free” data out there, like books, artwork, and music that are in the public domain.
This is why companies turn to copyrighted data, which includes articles written and published by news organizations, videos uploaded to YouTube by content creators, images drawn by artists and shared on Instagram, and photographs taken by photographers like Flach.
Playing By A Different Set of Rules
This wouldn’t be an issue if AI companies played by the same rules like Spotify paying record labels for music or news agencies licensing Getty images. But instead of compensating creators, these companies are bypassing them entirely.
Flach acknowledges that licensing AI training data could be a path forward, but only after companies are held accountable for past copyright violations. Without transparency, he argues, creators will continue to be exploited in the shadows. “The main issue is about transparency over what creative works are being used to train, weight, and fine-tune certain GAI (generative artificial intelligence) programs and how I as a creator can protect my photographs from being exploited without my permission or compensation, and whether a program released to users unfairly competes with my profession as a photographer.”
If these AI giants refuse to pay for content, the least they could do is follow Meta’s lead—giving users the right to opt-out. But even that seems too much to ask.
But individuals and organizations with copyrighted materials aren’t the only ones Google wants to screw over. In its policy proposal, Google wants more oversight of AI patents. The company claims that this is to discourage “low-quality” patents. Google also calls for the Inter Partes Review (IPR) process to continue, allowing companies to challenge invalid AI-related patents to avoid patent roadblocks.
It sounds like a good thing, but the reality of it is that Google wants to use these as weapons to challenge the patents from smaller firms that have fewer resources.
Big Tech: Taking A Page Out of Big Pharma’s Playbook
For years, pharmaceutical giants have used legal loopholes and aggressive patent tactics to suppress competition, extend monopolies, and block innovation. Now, Big Tech is following the same playbook with AI.
In the pharmaceutical industry, patents are weapons. Companies use strategies like evergreening, where they make minor tweaks to existing drugs (such as changing a pill’s coating) to extend patents and block generics from entering the market. They also file patent thickets. This consists of dozens of overlapping patents on a single drug to bury competitors in litigation. Lastly, they also use litigation as a weapon. They drown smaller biotech firms in lawsuits they can’t afford, forcing them to sell or shut down.
These tactics have kept life-saving medications expensive and delayed cheaper alternatives for years. Now, Google and other AI giants are applying the same legal warfare to artificial intelligence.
Google’s recent AI policy proposal isn’t just about copyright, it’s also about patents. The company claims it wants more oversight of AI patents to discourage “low-quality” filings and promote innovation.
Google’s Power Grab
But let’s call this what it really is: A power grab.
Smaller AI firms rely on patents to protect their inventions. It’s one of the only ways they can compete against trillion-dollar giants like Google. If Google can challenge and invalidate those patents, it can crush potential competitors before they become a threat. It will also allow them to freely absorb their technology without paying for it. It could also lead to the elimination of licensing negotiations entirely.
The AI industry is still young. Right now, we’re at a crossroads. If Google succeeds in shaping patent rules, copyright laws, and AI governance in its favor, we risk creating a closed AI ecosystem. One where startups never get a chance to compete. One where artists, writers, and researchers have no leverage and AI becomes monopolized by a handful of mega-corporations.
In the pharmaceutical world, these tactics have kept life-saving drugs out of reach for those who need them most. In AI, they could lock out independent creators, limit technological progress (the very thing Google’s policy proposal is complaining about), and centralize power in the hands of a few.
So What’s Next? The Future of AI, Copyright, and Government Oversight
If Google gets its way, what does this mean for content creators, journalists, and artists? Uncompensated data scraping could become the norm. AI-generated content could also flood the market, reducing demand for original work. Creators could lose control over their own styles, voices, and artistic identities.
Flach warns me that this isn’t just a copyright issue, it’s an existential threat to creative industries. “The danger is that this becomes a slippery slope where high-quality creative work is devalued because ‘the machine can do it.’ And once that happens, where does it leave the next generation of artists and photographers?”
The good news is that some governments are already taking a harder stance against AI exploitation. For example, the EU’s AI Act introduces stricter rules on AI transparency and training data usage. The UK and certain US states are exploring legislation that forces AI companies to disclose what data they train on.
Flach acknowledges that compensation for past copyright violations may be difficult. But he argues that failing to push back now sets a dangerous precedent. “The reality is that the genie is already out of the bottle, and clawing back fair compensation is going to be an uphill battle. But that doesn’t mean it shouldn’t be pursued. If we don’t at least push for accountability now, we set a precedent that devalues creative work going forward.”
Conclusion: A Crossroads for AI and Creativity
AI has the potential to change the creative landscape forever. But who benefits from it, and more importantly, at whose expense? Google and other AI giants want a world where they take, create, and profit without paying the people who made it possible in the first place.
If AI is the future, then it’s up to artists, journalists, and policymakers to ensure it’s a future where creativity is valued and not exploited. As Flach puts it, “We need governments across the globe to recognise the impact these programs are having in exploiting our works for profit and supplanting creators’ professional careers in the process.”
The post The AI Copyright Heist: Why Google Wants to Rewrite the Rules—For Itself appeared first on Android Headlines.






