































































![OpenAI Announces 4o Image Generation [Video]](https://www.iclarified.com/images/news/96821/96821/96821-640.jpg)

![Apple to Avoid EU Fine Over Browser Choice Screen [Report]](https://www.iclarified.com/images/news/96813/96813/96813-640.jpg)










![Do you care about Find My Device privacy settings? [Poll]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/06/Chipolo-One-Point-with-Find-My-Device-app.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











-xl-xl.jpg)















































































































































![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)













































































































![Is there an idiom for specifying axes and dimensions of array(-like) parameters? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)












































.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)
.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


























































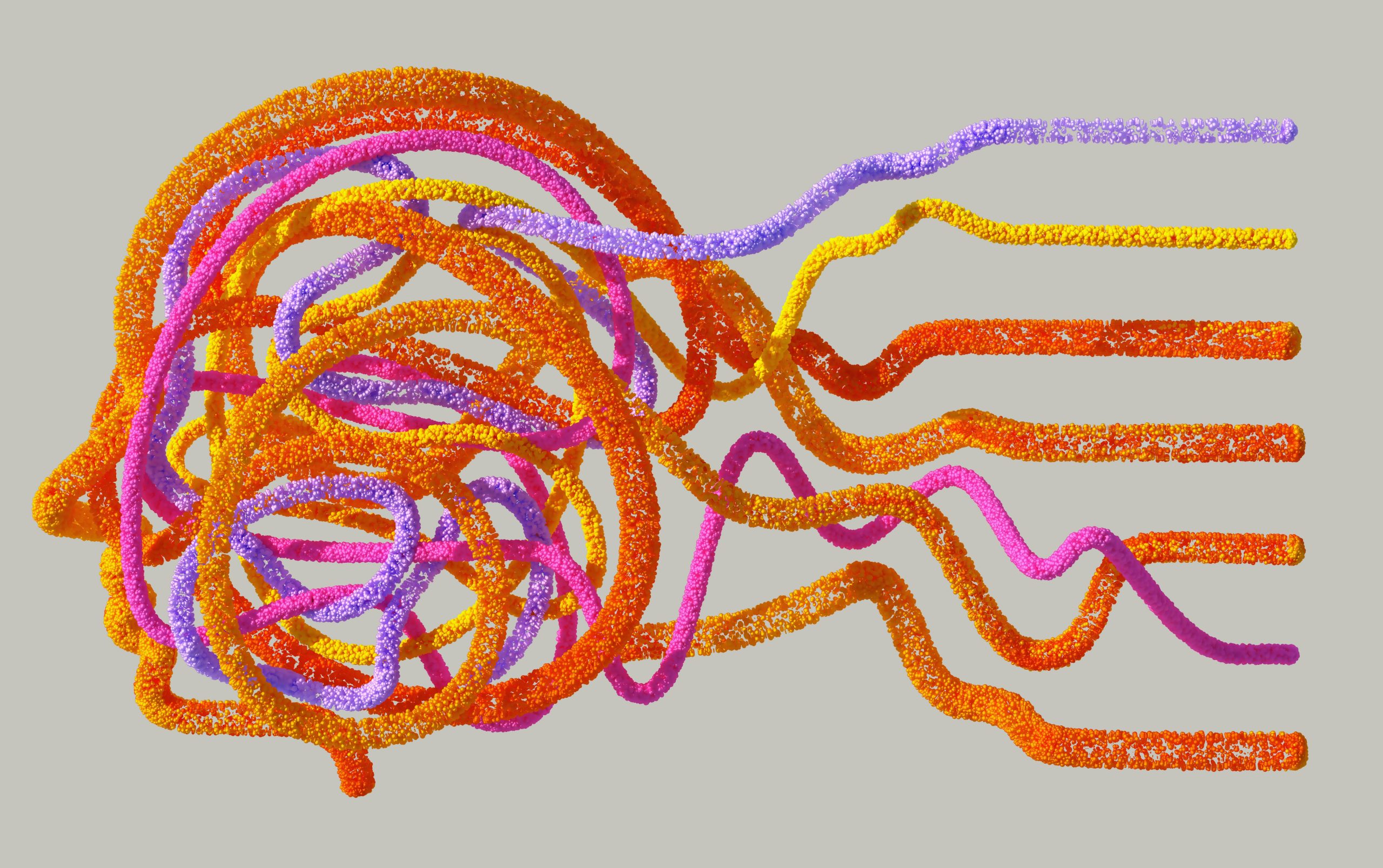
This AI Paper from NVIDIA Introduces Cosmos-Reason1: A Multimodal Model for Physical Common Sense and Embodied Reasoning
Artificial intelligence systems designed for physical settings require more than just perceptual abilities—they must also reason about objects, actions, and consequences in dynamic, real-world environments. These systems must understand spatial arrangements, cause-and-effect relationships, and the progression of events over time. In applications like robotics, self-driving vehicles, or assistive technologies, AI must comprehend its surroundings’ physical […] The post This AI Paper from NVIDIA Introduces Cosmos-Reason1: A Multimodal Model for Physical Common Sense and Embodied Reasoning appeared first on MarkTechPost.

Artificial intelligence systems designed for physical settings require more than just perceptual abilities—they must also reason about objects, actions, and consequences in dynamic, real-world environments. These systems must understand spatial arrangements, cause-and-effect relationships, and the progression of events over time. In applications like robotics, self-driving vehicles, or assistive technologies, AI must comprehend its surroundings’ physical constraints and affordances to make intelligent and safe decisions. This fusion of perception with structured reasoning about physical dynamics forms the backbone of Physical AI.
A core issue for such systems is their inability to conclude physical environments using integrated visual and contextual information. Although vision-language models have made significant progress, they still struggle to determine whether a task has been completed, what action should follow next, or whether a proposed action is feasible. The gap between perception and decision-making becomes especially critical when AI needs to operate independently and interpret tasks from complex visual scenarios. These systems remain unreliable in high-stakes or fast-changing environments without mechanisms to verify their reasoning.

Existing models such as LLaVA, GPT-4o, and Gemini 2.0 Flash are proficient in handling text and visual data but underperform physically grounded reasoning. Tasks like identifying temporal order, spatial continuity, or object permanence are rarely handled effectively. Popular benchmarks often fail to evaluate such scenarios, offering limited insight into a model’s ability to reason about physical events or agent actions. Moreover, current systems usually rely on textual cues rather than making decisions based on visual evidence, leading to inconsistent or incorrect conclusions when applied to the physical world.
Researchers from NVIDIA introduced Cosmos-Reason1, a family of vision-language models developed specifically for reasoning about physical environments. These models were released in two sizes: 8 billion and 56 billion parameters. The models were built with a structured approach that included defining ontologies for physical common sense, constructing specialized training data, and designing a comprehensive suite of evaluation benchmarks. These benchmarks test capabilities such as action prediction, task verification, and judgment of physical feasibility. The research team developed datasets including BridgeData V2, RoboVQA, RoboFail, AgiBot, HoloAssist, and AV to rigorously evaluate the models.

Cosmos-Reason1 uses a hybrid Mamba-MLP-Transformer architecture that integrates both vision and language components. The training process was conducted in multiple phases. Initially, a vision encoder and language model were pretrained and fine-tuned using general supervised data. Then, a physical AI-specific supervised fine-tuning (SFT) phase introduced datasets focused on space, time, and object interactions. The final reinforcement learning (RL) phase applied rule-based rewards to improve performance in areas like arrow of time detection, spatial puzzles, and object permanence. The RL setup used a modular framework that leveraged distributed computing to scale training efficiently. The model responses were structured using tags, allowing reward systems to evaluate both correctness and reasoning structure. Each question had up to nine model-generated responses, and RL training continued for 500 iterations using a global batch size of 128 questions.
Evaluation of Cosmos-Reason1 showed a substantial performance increase compared to other models. In the physical common sense benchmark, Cosmos-Reason1-56B achieved an average accuracy of 60.2%, outperforming OpenAI o1, which scored 59.9%. The 8B variant also improved, reaching 52.3%. Cosmos-Reason1-56B scored an average of 63.7% for embodied reasoning tasks, up from a 53.5% baseline. Benchmarks like RoboVQA and HoloAssist showed strong gains, with the 56B model scoring 80.0% and 57.8%, respectively. Cosmos-Reason1-8B improved to 68.7% on intuitive physics tasks, showing strong gains in object permanence and spatial puzzle reasoning. However, the model faced challenges on datasets like RoboFail due to a lack of sufficiently diverse training examples.


In conclusion, this research introduces a targeted and layered strategy to advance AI systems that reason about physical interactions. The researchers at NVIDIA created a scalable training method combined with a comprehensive evaluation to tackle long-standing gaps in embodied reasoning. Cosmos-Reason1 demonstrates how structured fine-tuning and reinforcement learning can build AI systems more aligned with real-world physical logic and agent behavior.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post This AI Paper from NVIDIA Introduces Cosmos-Reason1: A Multimodal Model for Physical Common Sense and Embodied Reasoning appeared first on MarkTechPost.







