































































![OpenAI Announces 4o Image Generation [Video]](https://www.iclarified.com/images/news/96821/96821/96821-640.jpg)

![Apple to Avoid EU Fine Over Browser Choice Screen [Report]](https://www.iclarified.com/images/news/96813/96813/96813-640.jpg)










![Do you care about Find My Device privacy settings? [Poll]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/06/Chipolo-One-Point-with-Find-My-Device-app.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











-xl-xl.jpg)















































































































































![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)













































































































![Is there an idiom for specifying axes and dimensions of array(-like) parameters? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)












































.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)
.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


























































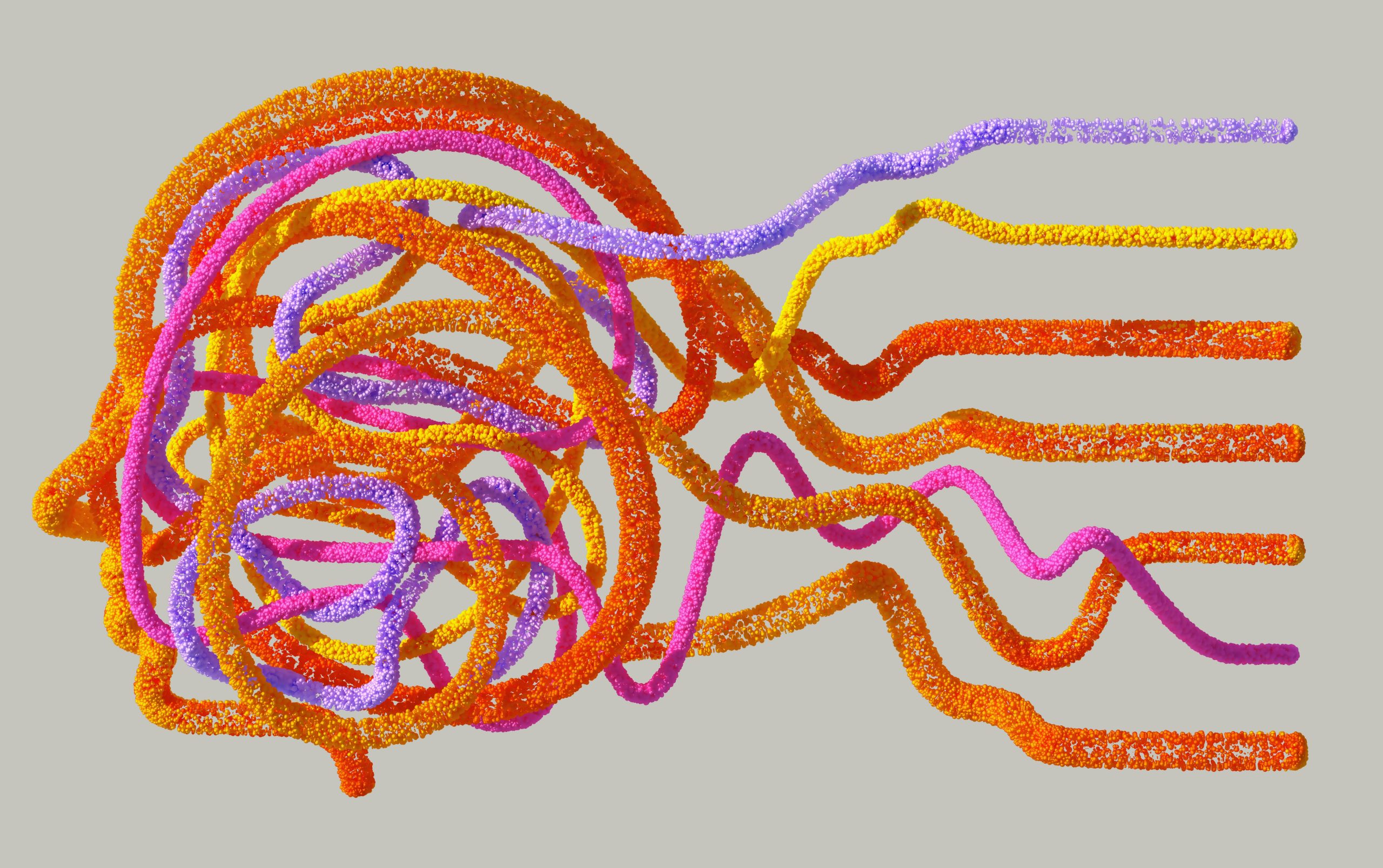
TokenSet: A Dynamic Set-Based Framework for Semantic-Aware Visual Representation
Visual generation frameworks follow a two-stage approach: first compressing visual signals into latent representations and then modeling the low-dimensional distributions. However, conventional tokenization methods apply uniform spatial compression ratios regardless of the semantic complexity of different regions within an image. For instance, in a beach photo, the simple sky region receives the same representational capacity […] The post TokenSet: A Dynamic Set-Based Framework for Semantic-Aware Visual Representation appeared first on MarkTechPost.

Visual generation frameworks follow a two-stage approach: first compressing visual signals into latent representations and then modeling the low-dimensional distributions. However, conventional tokenization methods apply uniform spatial compression ratios regardless of the semantic complexity of different regions within an image. For instance, in a beach photo, the simple sky region receives the same representational capacity as the semantically rich foreground. Pooling-based approaches extract low-dimensional features but lack direct supervision on individual elements, often yielding suboptimal results. Correspondence-based methods that employ bipartite matching suffer from inherent instability, as supervisory signals vary across training iterations, leading to inefficient convergence.
Image tokenization has evolved significantly to address compression challenges. Variational Autoencoders (VAEs) pioneered mapping images into low-dimensional continuous latent distributions. VQVAE and VQGAN advanced this by projecting images into discrete token sequences, while VQVAE-2, RQVAE, and MoVQ introduced hierarchical latent representations through residual quantization. FSQ, SimVQ, and VQGAN-LC tackled representation collapse when scaling codebook sizes. Other methods like set modeling have evolved from traditional Bag-of-Words (BoW) representations to more complex techniques. Techniques like DSPN use Chamfer loss, while TSPN and DETR employ Hungarian matching, though these processes often generate inconsistent training signals.
Researchers from the University of Science and Technology of China and Tencent Hunyuan Research have proposed a fundamentally new paradigm for image generation through set-based tokenization and distribution modeling. Their TokenSet approach dynamically allocates coding capacity based on regional semantic complexity. This unordered token set representation enhances global context aggregation and improves robustness against local perturbations. Moreover, they introduced Fixed-Sum Discrete Diffusion (FSDD), the first framework to simultaneously handle discrete values, fixed sequence length, and summation invariance, enabling effective set distribution modeling. Experiments show the method’s superiority in semantic-aware representation and generation quality.

Experiments are conducted on the ImageNet dataset using 256 × 256 resolution images, with results reported on the 50,000-image validation set using the Frechet Inception Distance (FID) metric. TiTok’s strategy is followed for tokenizer training, applying data augmentations including random cropping and horizontal flipping. The model is trained on ImageNet for 1000k steps with a batch size of 256, equivalent to 200 epochs. Training incorporates a learning rate warm-up phase followed by cosine decay, gradient clipping at 1.0, and an Exponential Moving Average with a 0.999 decay rate. A discriminator loss is included to enhance quality and stabilize training, with only the decoder trained during the final 500k steps. MaskGIT’s proxy code facilitates the training process.
The results show key strengths of the TokenSet approach. Permutation-invariance is confirmed through both visual and quantitative evaluation. All reconstructed images appear visually identical regardless of token order, with consistent quantitative results across different permutations. This validates that the network successfully learns permutation invariance even when trained on only a subset of possible permutations. Each token integrates global contextual information with a theoretical receptive field encompassing the entire feature space by decoupling inter-token positional relationships and eliminating sequence-induced spatial biases. Moreover, the FSDD approach uniquely satisfies all desired properties simultaneously, resulting in superior performance metrics.
In conclusion, the TokenSet framework represents a paradigm shift in visual representation by moving away from serialized tokens toward a set-based approach that dynamically allocates representational capacity based on semantic complexity. A bijective mapping is established between unordered token sets and structured integer sequences through a dual transformation mechanism, allowing effective modeling of set distributions using FSDD. Moreover, the set-based tokenization approach offers distinct advantages, introducing possibilities for image representation and generation. This direction opens new perspectives for developing next-generation generative models, with future work planned to analyze and unlock the full potential of this representation and modeling approach.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post TokenSet: A Dynamic Set-Based Framework for Semantic-Aware Visual Representation appeared first on MarkTechPost.






