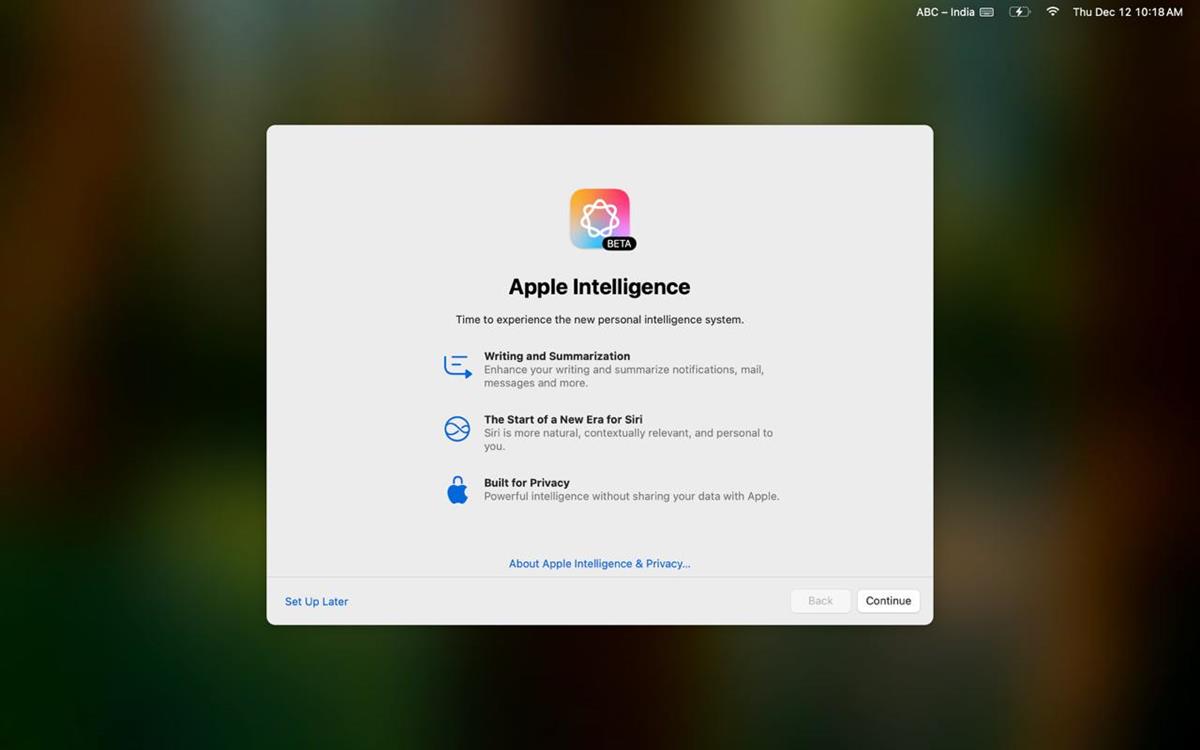
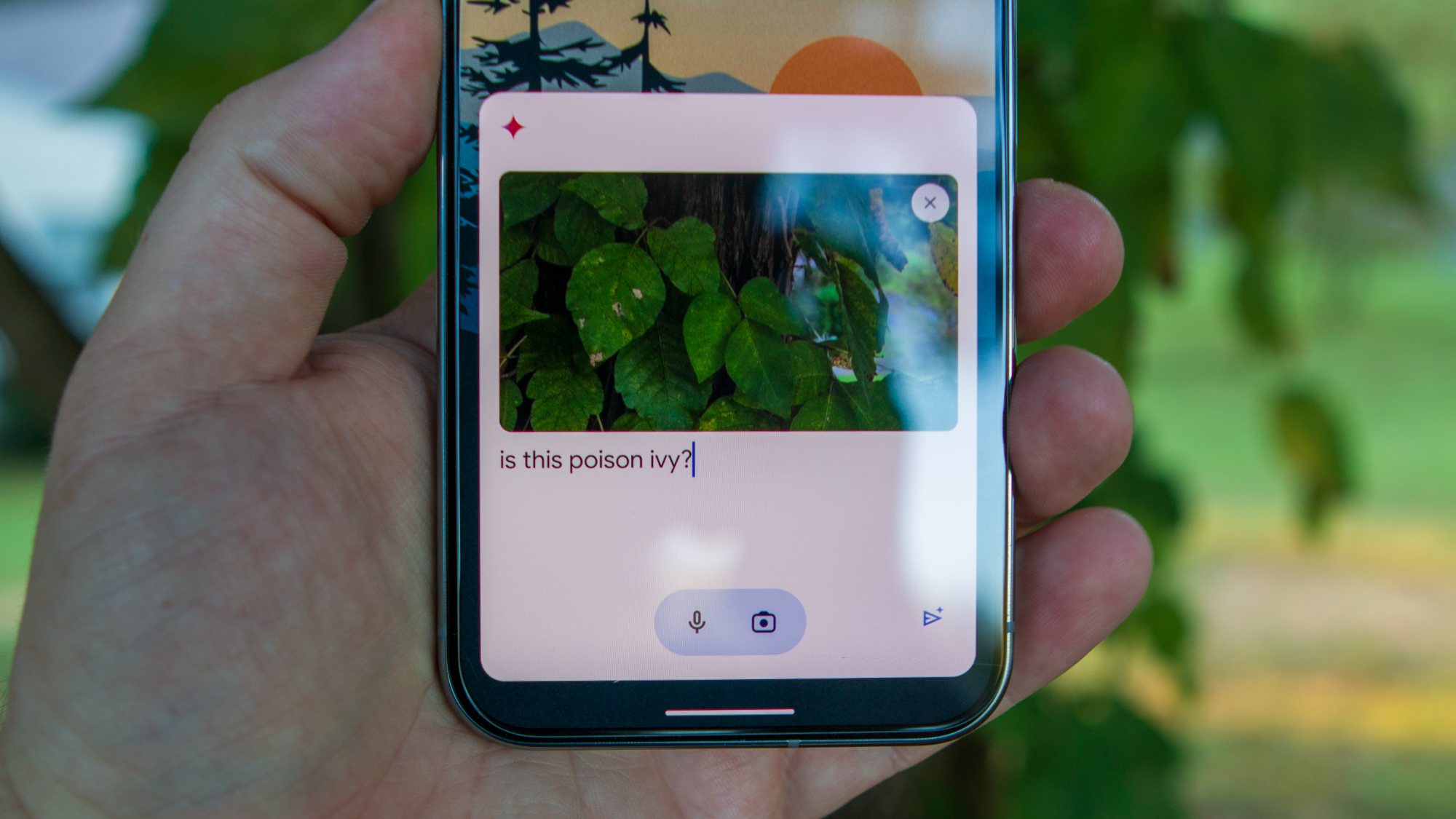
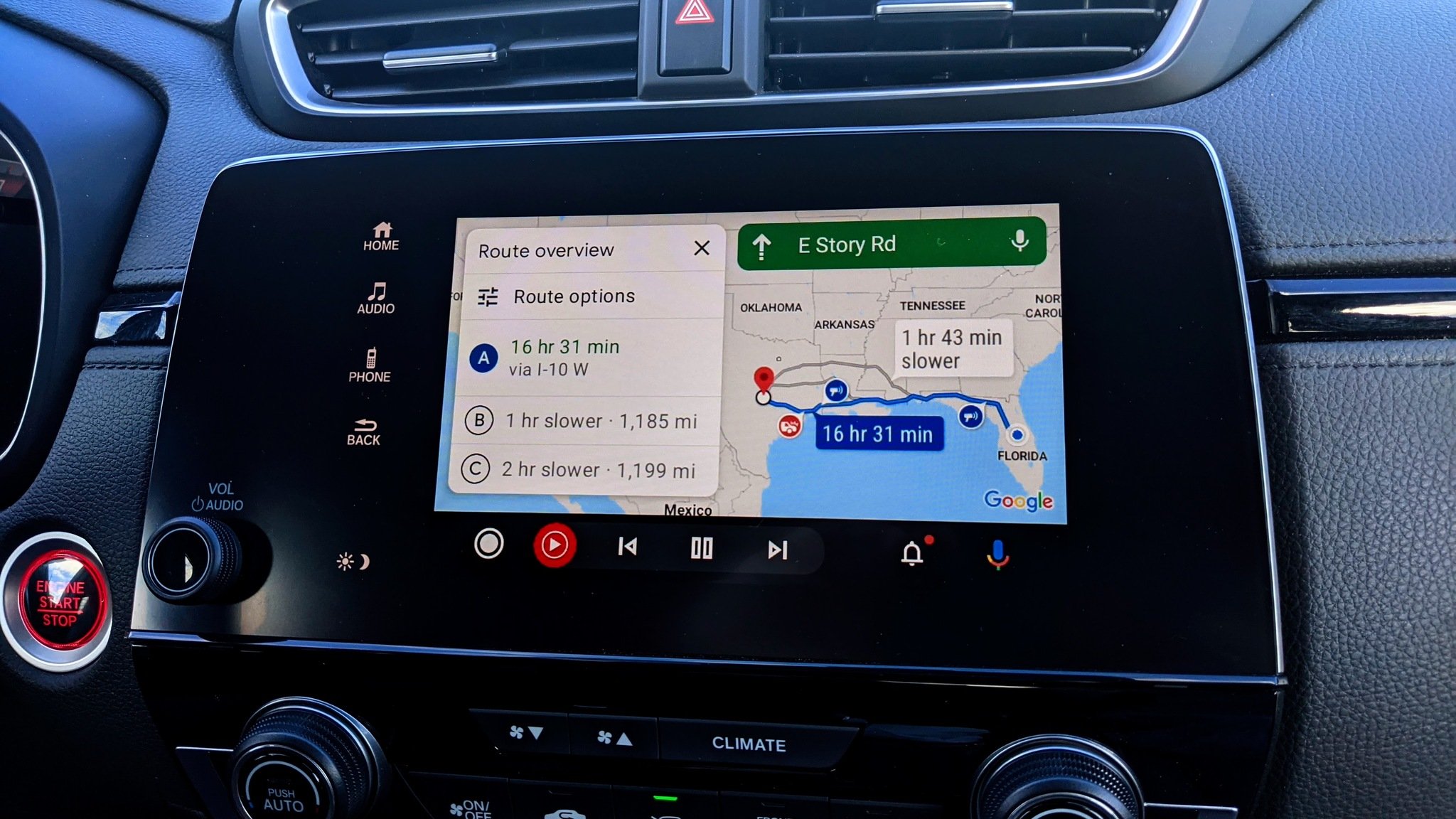
.webp?#)
.webp?#)






























































![iOS 19 Leak: First Look at Alleged VisionOS Inspired Redesign [Video]](https://www.iclarified.com/images/news/96824/96824/96824-640.jpg)

![OpenAI Announces 4o Image Generation [Video]](https://www.iclarified.com/images/news/96821/96821/96821-640.jpg)







































































































































































![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)

























































































































































































































RWKV-7: Advancing Recurrent Neural Networks for Efficient Sequence Modeling
Autoregressive Transformers have become the leading approach for sequence modeling due to their strong in-context learning and parallelizable training enabled by softmax attention. However, softmax attention has quadratic complexity in sequence length, leading to high computational and memory demands, especially for long sequences. While GPU optimizations mitigate this for short sequences, inference remains costly at […] The post RWKV-7: Advancing Recurrent Neural Networks for Efficient Sequence Modeling appeared first on MarkTechPost.

Autoregressive Transformers have become the leading approach for sequence modeling due to their strong in-context learning and parallelizable training enabled by softmax attention. However, softmax attention has quadratic complexity in sequence length, leading to high computational and memory demands, especially for long sequences. While GPU optimizations mitigate this for short sequences, inference remains costly at scale. Researchers have explored recurrent architectures with compressive states that offer linear complexity and constant memory use to address this. Advances in linear attention and state-space models (SSMs) have shown promise, with RNN-based approaches like RWKV-4 achieving competitive performance while significantly lowering inference costs.
Researchers from multiple institutions, including the RWKV Project, EleutherAI, Tsinghua University, and others, introduce RWKV-7 “Goose,” a novel sequence modeling architecture that establishes new state-of-the-art (SoTA) performance at the 3 billion parameter scale for multilingual tasks. Despite being trained on significantly fewer tokens than competing models, RWKV-7 achieves comparable English language performance while maintaining constant memory usage and inference time per token. The architecture extends the delta rule by incorporating vector-valued state gating, adaptive in-context learning rates, and a refined value replacement mechanism. These improvements enhance expressivity, enable efficient state tracking, and allow recognition of all regular languages, exceeding the theoretical capabilities of Transformers under standard complexity assumptions. To support its development, the researchers release an extensive 3.1 trillion-token multilingual corpus, alongside multiple pre-trained RWKV-7 models ranging from 0.19 to 2.9 billion parameters, all available under an open-source Apache 2.0 license.
RWKV-7 introduces key innovations layered on the RWKV-6 architecture, including token-shift, bonus mechanisms, and a ReLU² feedforward network. The model’s training corpus, RWKV World v3, enhances its English, code, and multilingual capabilities. In addition to releasing trained models, the team provides proof that RWKV-7 can solve problems beyond TC₀ complexity, including S₅ state tracking and regular language recognition. This demonstrates its ability to handle computationally complex tasks more efficiently than Transformers. Furthermore, the researchers propose a cost-effective method to upgrade the RWKV architecture without full retraining, facilitating incremental improvements. The development of larger datasets and models will continue under open-source licensing, ensuring broad accessibility and reproducibility.
The RWKV-7 model employs a structured approach to sequence modeling, denoting model dimensions as D and using trainable matrices for computations. It introduces vector-valued state gating, in-context learning rates, and a refined delta rule formulation. The time-mixing process involves weight preparation using low-rank MLPs, with key components like replacement keys, decay factors, and learning rates designed for efficient state evolution. A weighted key-value (WKV) mechanism facilitates dynamic state transitions, approximating a forget gate. Additionally, RWKV-7 enhances expressivity through per-channel modifications and a two-layer MLP, improving computational stability and efficiency while preserving state-tracking capabilities.

RWKV-7 models were assessed using the LM Evaluation Harness on various English and multilingual benchmarks, demonstrating competitive performance with state-of-the-art models while utilizing fewer training tokens. Notably, RWKV-7 outperformed its predecessor in MMLU and significantly improved multilingual tasks. Additionally, evaluations of recent internet data confirmed its effectiveness in handling information. The model excelled in associative recall, mechanistic architecture design, and long-context retention. Despite constraints in training resources, RWKV-7 demonstrated superior efficiency, achieving strong benchmark results while requiring fewer FLOPs than leading transformer models.
In conclusion, RWKV-7 is an RNN-based architecture that achieves state-of-the-art results across multiple benchmarks while requiring significantly fewer training tokens. It maintains high parameter efficiency, linear time complexity, and constant memory usage, making it a strong alternative to Transformers. However, it faces limitations such as numerical precision sensitivity, lack of instruction tuning, prompt sensitivity, and restricted computational resources. Future improvements include optimizing speed, incorporating chain-of-thought reasoning, and scaling with larger datasets. The RWKV-7 models and training code are openly available under the Apache 2.0 License to encourage research and development in efficient sequence modeling.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit.
The post RWKV-7: Advancing Recurrent Neural Networks for Efficient Sequence Modeling appeared first on MarkTechPost.







