_Andrew_Angelov_Alamy.jpg?#)

























































![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)

![Get Up to 69% Off Anker and Eufy Products on Final Day of Amazon's Big Spring Sale [Deal]](https://www.iclarified.com/images/news/96888/96888/96888-640.jpg)
![Apple Officially Releases macOS Sequoia 15.4 [Download]](https://www.iclarified.com/images/news/96887/96887/96887-640.jpg)

























![watchOS 11.4 was briefly available, and was pulled by Apple [u]](https://photos5.appleinsider.com/gallery/60061-123253-watchOS-11-on-Apple-Watch-Ultra-xl.jpg)



















































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)
















































































































![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)

















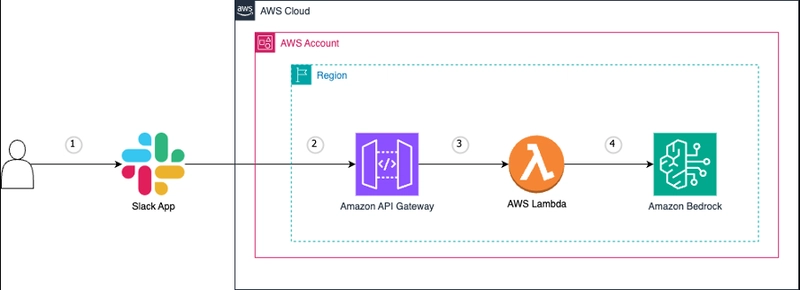
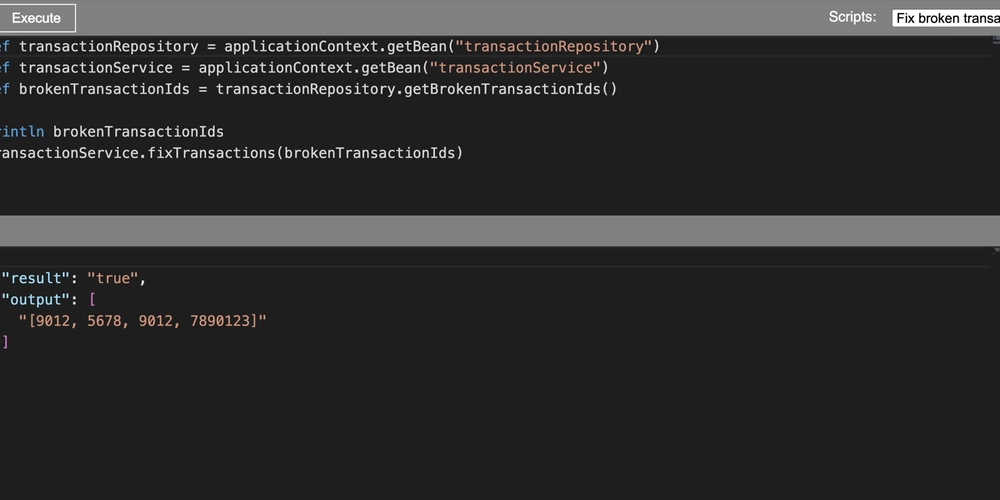

![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)



























-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)























































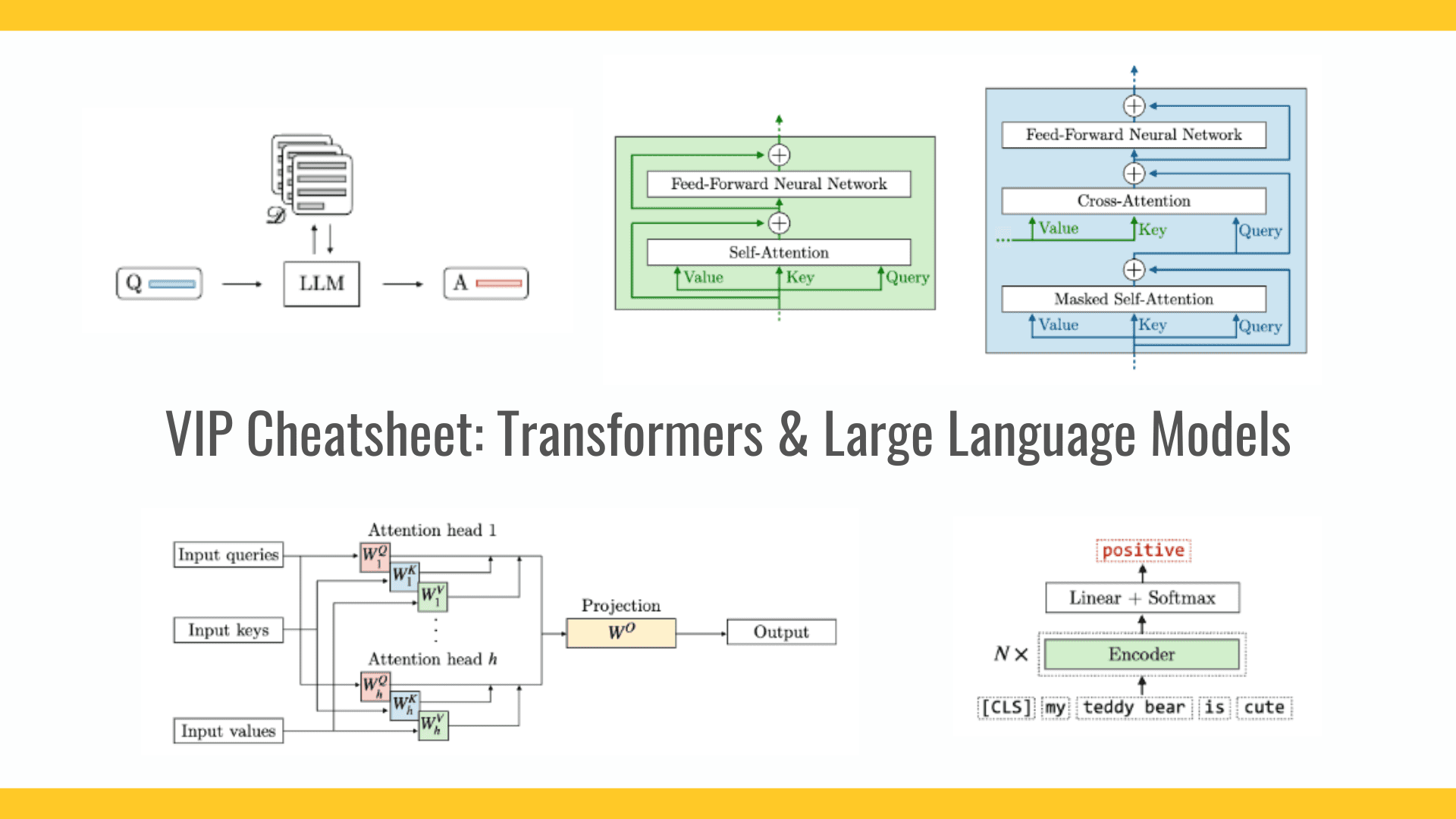
Using a Cache to Optimize Query Processing
Consider a setup where the data backend consists of a farm of Query Processors. Each Query Processor serves complex queries from a Web Server, using raw data from an underlying database. These requests typically involve compute-heavy, multi-second operations. The challenge is to leverage a cache mechanism to reduce request latency with minimal changes to the original design. The main bottleneck is the Query Processor. Improving user experience by quickly reducing latency would typically involve adding more hardware to the Query Processors, since horizontal scaling is not viable without significant refactoring of the software architecture. Introducing a Cache and Design Trade-offs Assuming query results can tolerate some staleness (e.g., a few hours), we can introduce a distributed Key-Value cache, such as Redis, between the Query Processor and the raw data database. In this architecture, we build a unique key for each query and store the key and the query result (value) in the cache. As always in software engineering, the devil is in the details. Here are some key design trade-offs: Staleness vs. Latency: Keep queries in the cache long enough to achieve a high hit ratio and reduce latency, but not so long that the results become too stale. Insertion Cost: Inserting a key in the cache can be costly, especially if the cache grows too fast and eviction kicks in. A common technique is to insert new keys with a TTL (Time-To-Live), so that keys are reclaimed as soon as the TTL expires. Choosing the right TTL is a delicate balance between avoiding eviction costs and maintaining a good hit ratio. Choosing the Query Key: Selecting the query key is crucial. A pure hash balances values evenly across cache shards, avoiding hot spots. However, adding some discrimination to the key can help with tasks like cleaning up keys by version of the product or other properties. The risk is skewing the load on one of the shards, but the benefits can outweigh this risk. I encourage you to explore these concepts further and consider how they might apply to your own systems. Implementing a well-designed cache can be a game-changer for performance optimization without requiring major architectural changes. This article is also available on LinkedIn, where you can join the discussion
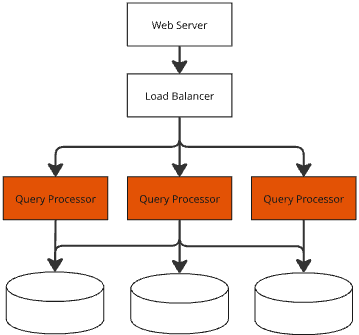
Consider a setup where the data backend consists of a farm of Query Processors. Each Query Processor serves complex queries from a Web Server, using raw data from an underlying database. These requests typically involve compute-heavy, multi-second operations. The challenge is to leverage a cache mechanism to reduce request latency with minimal changes to the original design.
The main bottleneck is the Query Processor. Improving user experience by quickly reducing latency would typically involve adding more hardware to the Query Processors, since horizontal scaling is not viable without significant refactoring of the software architecture.
Introducing a Cache and Design Trade-offs
Assuming query results can tolerate some staleness (e.g., a few hours), we can introduce a distributed Key-Value cache, such as Redis, between the Query Processor and the raw data database. In this architecture, we build a unique key for each query and store the key and the query result (value) in the cache.
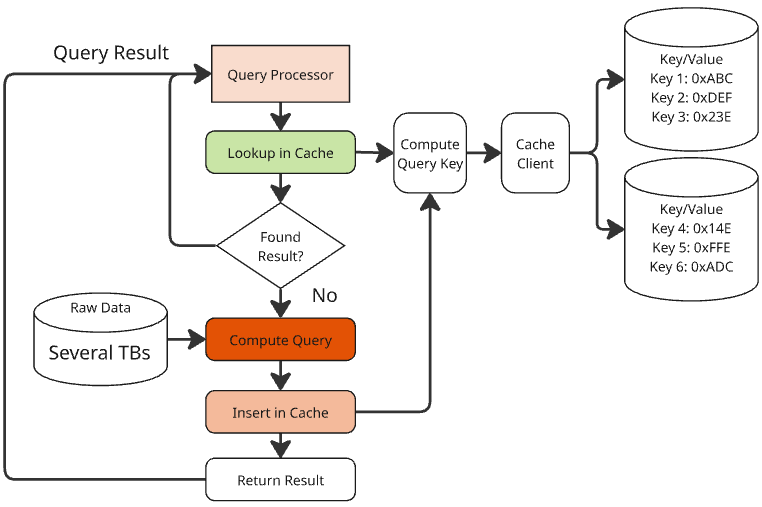
As always in software engineering, the devil is in the details. Here are some key design trade-offs:
Staleness vs. Latency: Keep queries in the cache long enough to achieve a high hit ratio and reduce latency, but not so long that the results become too stale.
Insertion Cost: Inserting a key in the cache can be costly, especially if the cache grows too fast and eviction kicks in. A common technique is to insert new keys with a TTL (Time-To-Live), so that keys are reclaimed as soon as the TTL expires. Choosing the right TTL is a delicate balance between avoiding eviction costs and maintaining a good hit ratio.
Choosing the Query Key: Selecting the query key is crucial. A pure hash balances values evenly across cache shards, avoiding hot spots. However, adding some discrimination to the key can help with tasks like cleaning up keys by version of the product or other properties. The risk is skewing the load on one of the shards, but the benefits can outweigh this risk.
I encourage you to explore these concepts further and consider how they might apply to your own systems. Implementing a well-designed cache can be a game-changer for performance optimization without requiring major architectural changes.
This article is also available on LinkedIn, where you can join the discussion