





































![Apple Watch Series 10 Prototype with Mystery Sensor Surfaces [Images]](https://www.iclarified.com/images/news/96892/96892/96892-640.jpg)





































































































_Andrew_Angelov_Alamy.jpg?#)









































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)















































































































![Is this a suitable approach to architect a flutter app? [closed]](https://i.sstatic.net/4hMHGb1L.png)



















![From broke musician to working dev. How college drop-out Ryan Furrer taught himself to code [Podcast #166]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743189826063/2080cde4-6fc0-46fb-b98d-b3d59841e8c4.png?#)































-1280x720.jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















































Using TF-IDF Vectors With PHP & PostgreSQL
Vectors in PostgreSQL are used to compare data to find similarities, outliers, groupings, classifications and other things. pg_vector is a popular extension for PostgreSQL that adds vector functionality to PostgreSQL. What is TF-IDF? TF-IDF stands for Term Frequency-Inverse Document Frequency. It's a way to compare the importance of a word in a document compared to a collection of documents. Term Frequency Term frequency refers to how often a word is used within a document. In a 100 word document, if the word 'test' occurs 5 times, then the term frequency would be 5/100 = 0.05 Inverse Document Frequency Inverse Document Frequency measures how unique a word is across a group of documents. Common words like "the" or "and" appear in almost all documents, so they are assigned a low IDF score. Rare, specific words are assigned a higher IDF score. The TF-IDF score is TF * IDF. Normalizing TF-IDF A drawback to using TF-IDF is that it unfairly advantages long documents over short documents. Longer documents can accumulate higher TF-IDF scores simply because they contain more words, not necessarily because the word is more relevant. This can be corrected by normalizing the score based on the document length. TD-IDF score / total words in document. PHP Implementation Guide To create vectors in PHP, select all articles from a database and loop through them. foreach ($articles as $article) { $articleText = $article['description']; $tokenizedDocuments[$article['id']] = $this->tokenizeArticle($articleText); $this->updateDocumentFrequencies($documentFrequencies, $words); } Break up the document into an array of words. Additional word processing could be done here if required. protected function tokenizeArticle(string $text): array { $text = strtolower($text); $text = preg_replace('/[^\w\s]/', '', $text); $words = preg_split('/\s+/', trim($text)); return $words; } Create an array to keep track of the word frequency across all documents. protected function updateDocumentFrequencies(array &$documentFrequencies, array $words): void { $uniqueWords = array_unique($words); foreach ($uniqueWords as $word) { if (!isset($documentFrequencies[$word])) { $documentFrequencies[$word] = 0; } $documentFrequencies[$word]++; } } Once the articles have been processed, create the embedding vector protected function createEmbeddings( array $articles, array $tokenizedDocuments, array $documentFrequencies, ): void { $totalDocuments = count($articles); foreach ($articles as $article) { $articleId = $article['id']; $words = $tokenizedDocuments[$articleId]; $embedding = $this->calculateEmbedding( $words, $documentFrequencies, $totalDocuments ); } } CaclulateEmbedding() is where the main calculations for TF-IDF score is done. protected function calculateEmbedding( array $words, array $documentFrequencies, int $totalDocuments ): array { $termFrequencies = array_count_values($words); $totalWords = count($words); $embedding = array_fill(0, $this->dimension, 0.0); foreach ($termFrequencies as $word => $count) { $tf = $count / $totalWords; $idf = log($totalDocuments / ($documentFrequencies[$word] + 1)); $tfidf = $tf * $idf; $index = abs(crc32($word) % $this->dimension); $embedding[$index] += $tfidf; } return $this->normalizeVector($embedding); } Dimensions The number chosen for dimensions is critical to good quality TF-IDF. The number should be large enough to hold the number of unique words in any of your documents. 768 or 1536 are good numbers for medium sized documents. As a general rule about 20 - 30% of words in a document are unique. 1536 equates to about a 20 to 30 page document. Calculate TF Divide the number of times a word occurs in a document by the total words in the document. $tf = $count / $totalWords; Calculate IDF Since IDF is the inverse of the document frequency, we use log to calculate the score $idf = log($totalDocuments / ($documentFrequencies[$word] + 1)); Calculate TF-IDF $tfidf = $tf * $idf; TF-IDF array TF-IDF arrays do not store values in order, instead they are stored in a calculated array key. This ensures that the same word will always appear in the same array position across all documents. While it is possible to calculate duplicate array keys, as long as the vectors dimension size chosen is appropriate for the size of the document, duplicates are rare and is generally represents a similar word. To calculate the position, use crc32 to generate an integer representation of the word and then divide it by the dimension size, and use the remainder as the array key position. This will give a good spread of spaces that are filled with the TF-IDF
Vectors in PostgreSQL are used to compare data to find similarities, outliers, groupings, classifications and other things.
pg_vector is a popular extension for PostgreSQL that adds vector functionality to PostgreSQL.
What is TF-IDF?
TF-IDF stands for Term Frequency-Inverse Document Frequency. It's a way to compare the importance of a word in a document compared to a collection of documents.
Term Frequency
Term frequency refers to how often a word is used within a document. In a 100 word document, if the word 'test' occurs 5 times, then the term frequency would be 5/100 = 0.05
Inverse Document Frequency
Inverse Document Frequency measures how unique a word is across a group of documents.
Common words like "the" or "and" appear in almost all documents, so they are assigned a low IDF score. Rare, specific words are assigned a higher IDF score.
The TF-IDF score is TF * IDF.
Normalizing TF-IDF
A drawback to using TF-IDF is that it unfairly advantages long documents over short documents.
Longer documents can accumulate higher TF-IDF scores simply because they contain more words, not necessarily because the word is more relevant.
This can be corrected by normalizing the score based on the document length.
TD-IDF score / total words in document.
PHP Implementation Guide
To create vectors in PHP, select all articles from a database and loop through them.
foreach ($articles as $article) {
$articleText = $article['description'];
$tokenizedDocuments[$article['id']] = $this->tokenizeArticle($articleText);
$this->updateDocumentFrequencies($documentFrequencies, $words);
}
Break up the document into an array of words. Additional word processing could be done here if required.
protected function tokenizeArticle(string $text): array
{
$text = strtolower($text);
$text = preg_replace('/[^\w\s]/', '', $text);
$words = preg_split('/\s+/', trim($text));
return $words;
}
Create an array to keep track of the word frequency across all documents.
protected function updateDocumentFrequencies(array &$documentFrequencies, array $words): void
{
$uniqueWords = array_unique($words);
foreach ($uniqueWords as $word) {
if (!isset($documentFrequencies[$word])) {
$documentFrequencies[$word] = 0;
}
$documentFrequencies[$word]++;
}
}
Once the articles have been processed, create the embedding vector
protected function createEmbeddings(
array $articles,
array $tokenizedDocuments,
array $documentFrequencies,
): void {
$totalDocuments = count($articles);
foreach ($articles as $article) {
$articleId = $article['id'];
$words = $tokenizedDocuments[$articleId];
$embedding = $this->calculateEmbedding(
$words,
$documentFrequencies,
$totalDocuments
);
}
}
CaclulateEmbedding() is where the main calculations for TF-IDF score is done.
protected function calculateEmbedding(
array $words,
array $documentFrequencies,
int $totalDocuments
): array {
$termFrequencies = array_count_values($words);
$totalWords = count($words);
$embedding = array_fill(0, $this->dimension, 0.0);
foreach ($termFrequencies as $word => $count) {
$tf = $count / $totalWords;
$idf = log($totalDocuments / ($documentFrequencies[$word] + 1));
$tfidf = $tf * $idf;
$index = abs(crc32($word) % $this->dimension);
$embedding[$index] += $tfidf;
}
return $this->normalizeVector($embedding);
}
Dimensions
The number chosen for dimensions is critical to good quality TF-IDF. The number should be large enough to hold the number of unique words in any of your documents. 768 or 1536 are good numbers for medium sized documents. As a general rule about 20 - 30% of words in a document are unique. 1536 equates to about a 20 to 30 page document.
Calculate TF
Divide the number of times a word occurs in a document by the total words in the document.
$tf = $count / $totalWords;
Calculate IDF
Since IDF is the inverse of the document frequency, we use log to calculate the score
$idf = log($totalDocuments / ($documentFrequencies[$word] + 1));
Calculate TF-IDF
$tfidf = $tf * $idf;
TF-IDF array
TF-IDF arrays do not store values in order, instead they are stored in a calculated array key. This ensures that the same word will always appear in the same array position across all documents.
While it is possible to calculate duplicate array keys, as long as the vectors dimension size chosen is appropriate for the size of the document, duplicates are rare and is generally represents a similar word.
To calculate the position, use crc32 to generate an integer representation of the word and then divide it by the dimension size, and use the remainder as the array key position.
This will give a good spread of spaces that are filled with the TF-IDF scores.
Normalizing
Earlier we talked about normalizing as word frequency/docuiment length, while it can be calculated this way, normalizing is more commonly calculated using the Euclidean norm formula: √(x₁² + x₂² + ... + xₙ²)
The normalizeVector method is a PHP representation of this formula.
protected function normalizeVector(array $vector): array
{
$magnitude = sqrt(array_sum(array_map(function ($x) {
return $x * $x;
}, $vector)));
if ($magnitude > 0) {
return array_map(function ($x) use ($magnitude) {
return $x / $magnitude;
}, $vector);
}
return $vector;
}
The final vector may look something like this:
[0.052876625,0,0,0,0,0,0,0,0,0,0,0,0.013156515,0,0,0,0,0,0,0,0,0,0,0,0,0,0,-0.012633555,0,0,0,0,0.0065987236,0,0 ...]
This is known as a sparse vector. A sparse vector has a lot of empty array keys whereas a dense vector is much more filled in.
Dense vectors can improve the quality of the vector. One method of doing this is to include bi-grams in the vector along with the single words.
For example:
This is known as a sparse vector would include each word [this,is,known,as,a,sparse,vector] adding bi-grams would include [this_is,is_known,known_as,as_a,a_sparse,sparse_vector] which adds more context to the words by taking into account the words around them.
Creating Queries in PostgreSQL
Once vectors have been generated for your documents, it's time to store them in PostgreSQL.
Selecting the right dimension for your document is also critical here, once you choose a dimension size, all vectors going into the field have to be the same dimension.
ALTER TABLE "articles"
ADD COLUMN "embedding" vector(1536);
Types of Comparisions
There are three types of comparisons in PostgreSQL
Euclidean (L2) distance: <-> : Measures how far apart two vectors are. Smaller numbers mean vectors are more similar. Good for finding similar products etc.
Cosine similarity: <=> : Measures the angle between vectors, ignoring their magnitude. Smaller numbers mean vectors are more similar in direction. Good for text similarity where length shouldn't matter.
Inner product: <#> : Measures how much vectors "align" with each other. Larger numbers mean vectors are more similar (opposite of the others!). Useful for normalized comparisons.
Try them all with your data to find the one that best suits your use case.
Creating a recommendation system
One of the use cases of vectors is to create a recommendation system, in this case to find articles that are related in some way to the one you are currently reading.
To do this, we need to order the rows by the comparison to find the ones most relevant to the current article.
In this query, first, the embedding of the current article needs to be selected and then compare other articles to it, to find the most relevant.
For a recommendation, filtering out the current article from the query makes sense.
WITH
search_article AS (
SELECT embedding
FROM articles
WHERE id = 12
)
SELECT id,title
FROM articles
WHERE id <> 12
ORDER BY embedding <-> (
SELECT embedding
FROM search_article
)
LIMIT 4;
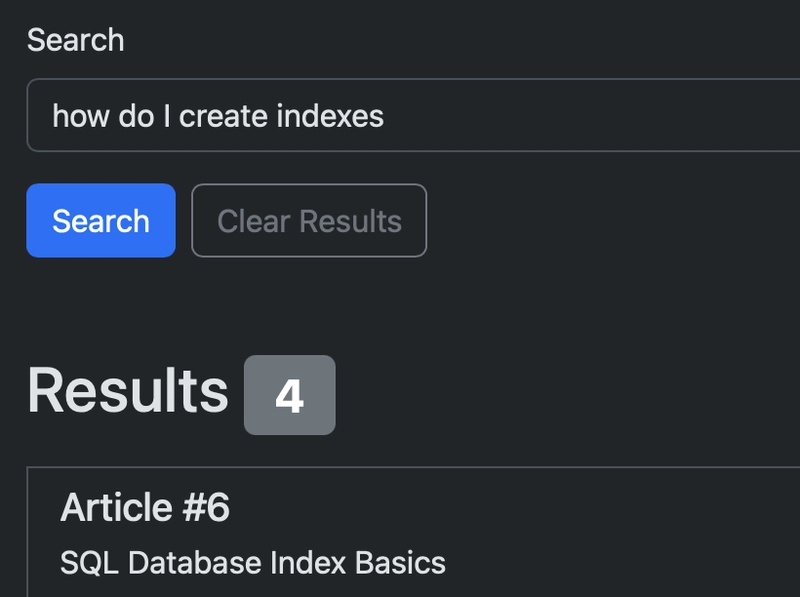
Creating a search engine
Vectors can be used to create a search engine for your documents. Comparing articles with the user entered question or keywords.
To do this, The user entered question would need to be converted into a vector using the term frequencies of your current articles (recommend this be stored in the database so you are not calculating them every time a search query is run). The user vector would need to be the same dimension size as the articles.
Create a query to compare the user vector to the stored vectors
SELECT id,title
FROM articles
ORDER BY embedding <=> :embedding
LIMIT 4;
Other use cases
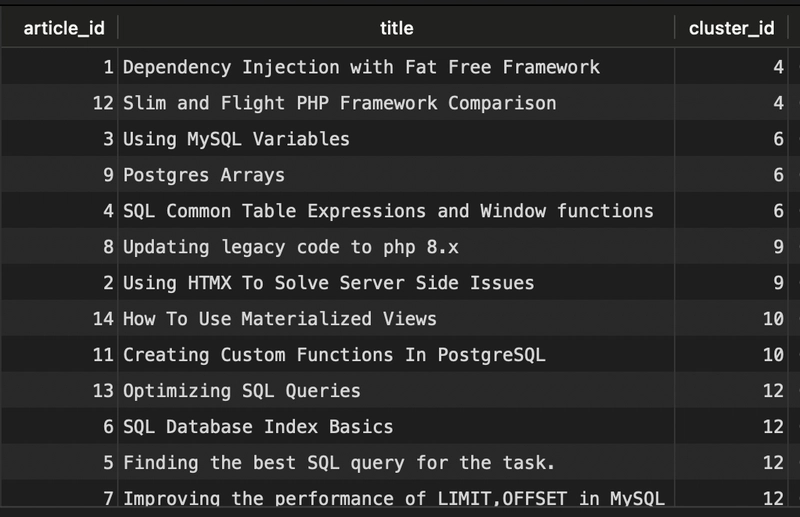
Classifying Articles
A more complex use case for vectors would be to classify documents to put similar articles together. You may not have specific tags/keywords to classify documents against, but articles can still be classified into similar items.
This results in similar articles having the same cluster id
Finding Anomalies
If users post articles about tech, and suddenly someone posts an article about places to buy plushies, that would be an anomaly and might be worth checking to see if it fits the site's requirements.
To implement an anomaly checker, a distance threshold would need to be set and anything further away than the threshold would be flagged for manual review.
WITH
article_distances AS (
SELECT
id,
title,
embedding <-> (
SELECT AVG(embedding)::vector(1536)
FROM articles
) AS distance_from_average
FROM articles
)
SELECT id, title, distance_from_average
FROM article_distances
WHERE distance_from_average > 0.75
ORDER BY distance_from_average DESC;
This query calculates the "average" embedding across all articles (representing your typical content) and then finds articles that are significantly different from this average.
Experiment with the threshold to find what is right for your use case.
Conclusion
Vectors are both complex and powerful, well planned vectors can help automate many use cases or add features to your website.
TF-IDF, while it is the method I chose here, it's not the only vector type. Open AI has their own model for generating vectors from text, as does Ollama. These may or may not be better for your use case.
It's important to experiment with different approaches - test various dimension sizes, comparison methods, and even vector generation techniques to find what works best for your specific needs.