.webp?#)
.webp?#)






























































![iOS 19 Leak: First Look at Alleged VisionOS Inspired Redesign [Video]](https://www.iclarified.com/images/news/96824/96824/96824-640.jpg)

![OpenAI Announces 4o Image Generation [Video]](https://www.iclarified.com/images/news/96821/96821/96821-640.jpg)







































































































































































![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)


























































































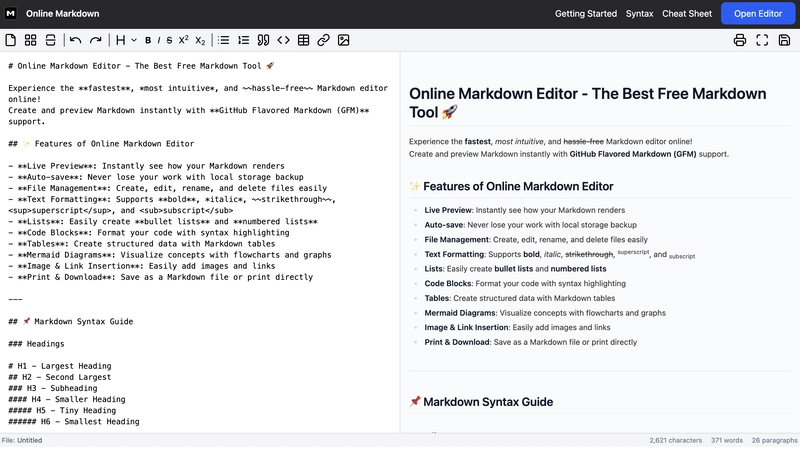































































































































Sets are the Data Type Your Code Needs
At Turing, we have seven months to teach you programming and software engineering. While we cover a lot of ground, there are still plenty of fascinating topics that don’t make it into the core curriculum. This blog series explores intriguing ideas and concepts we’re passionate about—but don’t typically get to teach. This blog was originally posted here. What are sets? Put into the simplest terms, a set is a unique unordered collection. It's the implementation of the set from mathematical theory, which you might have studied in school. In practical terms, the set helps us efficiently determine whether an item is a part of the collection or not. We can contrast this with an array, which is concerned with what position is the item at. Why are sets? Most of the things we can use sets for, we already do with arrays. The problem is that doing so can be incredibly inefficient. In terms of computational efficiency, we can think about the #uniq method. Finding unique elements in an array requires Ruby to scan through the entire array. If we were to use the #include? method, we still scan through the entire array, but we also have to scan through any duplicates that exist in the array as well. Arrays with duplicate elements also add to memory overhead. These duplicate items consume additional memory but don’t have any new information. Think about an array with a million copies of the string, "Athena" - this array uses a million references to the same data. There may be some object sharing taking place to cut down this overhead, and a million strings isn’t THAT much memory, but we can see how this can balloon for sure when we are storing complex objects and not just simple strings. We can also encounter some incredibly annoying bugs. When we remove an element from an array, using #delete only removes the first instance in which it encounters the element! You have to end up checking the entire collection to make sure you got all of the things using the #count method, which adds complexity. Photo by Timo Volz / Unsplash How do sets fix this? We get improved computational efficiency, because, under the hood, sets are implemented using hashes - each item in a set is the key in a hash. (We don’t use the values). So when we look to see if a set includes an item, it’s just a hash lookup, which is an O(1) constant time operation, regardless of how large our set is. WOWOWOWOW. Gone are the days where you have to scan an entire collection to see if it had the thing you were looking for. Memory overhead is a thing of the past. Sets store only unique elements, and it will not add additional copies no matter how many times you add the same thing to it. If you have a large array full of the same data and convert it to a set, the size of that set is just one. Remember the potential for bugs we were just talking about earlier? Removing elements from a set removes it completely. It obviates the need to go back and ensure that you’ve in fact removed everything. When you add elements to a set, you can’t create duplicates. Summary of Key Benefits So before we get into the code and implementation, let’s recap the key advantages, and recap just why we want to use sets when it’s the right choice. Guaranteed Uniqueness - this one’s the main benefit. Uniqueness is enforced, so never again will we have to worry about duplicates ruining our data or logic. Performance Advantages - we get almost constant time lookup performance regardless of the size of the data we are working with, as compared to the linear time performance that we get with arrays. Mathematical Set Operations - we’ll get into this later, but we get access to set math, which allows us to perform operations such as union, intersection, and difference without having to do it by hand. Clear Code Intent - I always say that Ruby code should be written in a way that your code should express your intent. How better to let people know that this collection of data needs to be unique than by using a set? Photo by Joshua Fuller / Unsplash Getting Started With Sets in Ruby The first thing we have to do to get started with using sets in Ruby is to add the library. require 'set' Why? Because sets are not part of the core library, but they are part of the Ruby standard library. I like to think of the difference between the two as such: Things that are in the core library are things you will need in nearly every single project you work on. Strings, arrays, hashes, your basic mathematic operations, enumerables. Things that are in the standard library are things that you MIGHT need. Sets, the JSON stuff, CSV, FileIO, Benchmark, Date, and so on and so forth. There are a number of ways we can create a set. We can just create an empty set. set = Set.new puts set.inspect # => # We can create a set from an array! numbers = [1, 2, 3, 2, 1] set = Set.new(numbers) puts set.inspect # => # Note that when we have

At Turing, we have seven months to teach you programming and software engineering. While we cover a lot of ground, there are still plenty of fascinating topics that don’t make it into the core curriculum. This blog series explores intriguing ideas and concepts we’re passionate about—but don’t typically get to teach.
This blog was originally posted here.
What are sets?
Put into the simplest terms, a set is a unique unordered collection. It's the implementation of the set from mathematical theory, which you might have studied in school. In practical terms, the set helps us efficiently determine whether an item is a part of the collection or not. We can contrast this with an array, which is concerned with what position is the item at.
Why are sets?
Most of the things we can use sets for, we already do with arrays. The problem is that doing so can be incredibly inefficient. In terms of computational efficiency, we can think about the #uniq method. Finding unique elements in an array requires Ruby to scan through the entire array. If we were to use the #include? method, we still scan through the entire array, but we also have to scan through any duplicates that exist in the array as well.
Arrays with duplicate elements also add to memory overhead. These duplicate items consume additional memory but don’t have any new information. Think about an array with a million copies of the string, "Athena" - this array uses a million references to the same data. There may be some object sharing taking place to cut down this overhead, and a million strings isn’t THAT much memory, but we can see how this can balloon for sure when we are storing complex objects and not just simple strings.
We can also encounter some incredibly annoying bugs. When we remove an element from an array, using #delete only removes the first instance in which it encounters the element! You have to end up checking the entire collection to make sure you got all of the things using the #count method, which adds complexity.
Photo by Timo Volz / Unsplash
How do sets fix this?
We get improved computational efficiency, because, under the hood, sets are implemented using hashes - each item in a set is the key in a hash. (We don’t use the values). So when we look to see if a set includes an item, it’s just a hash lookup, which is an O(1) constant time operation, regardless of how large our set is. WOWOWOWOW. Gone are the days where you have to scan an entire collection to see if it had the thing you were looking for.
Memory overhead is a thing of the past. Sets store only unique elements, and it will not add additional copies no matter how many times you add the same thing to it. If you have a large array full of the same data and convert it to a set, the size of that set is just one.
Remember the potential for bugs we were just talking about earlier? Removing elements from a set removes it completely. It obviates the need to go back and ensure that you’ve in fact removed everything. When you add elements to a set, you can’t create duplicates.
Summary of Key Benefits
So before we get into the code and implementation, let’s recap the key advantages, and recap just why we want to use sets when it’s the right choice.
Guaranteed Uniqueness - this one’s the main benefit. Uniqueness is enforced, so never again will we have to worry about duplicates ruining our data or logic.
Performance Advantages - we get almost constant time lookup performance regardless of the size of the data we are working with, as compared to the linear time performance that we get with arrays.
Mathematical Set Operations - we’ll get into this later, but we get access to set math, which allows us to perform operations such as union, intersection, and difference without having to do it by hand.
Clear Code Intent - I always say that Ruby code should be written in a way that your code should express your intent. How better to let people know that this collection of data needs to be unique than by using a set?

Photo by Joshua Fuller / Unsplash
Getting Started With Sets in Ruby
The first thing we have to do to get started with using sets in Ruby is to add the library.
require 'set'
Why? Because sets are not part of the core library, but they are part of the Ruby standard library. I like to think of the difference between the two as such: Things that are in the core library are things you will need in nearly every single project you work on. Strings, arrays, hashes, your basic mathematic operations, enumerables. Things that are in the standard library are things that you MIGHT need. Sets, the JSON stuff, CSV, FileIO, Benchmark, Date, and so on and so forth.
There are a number of ways we can create a set. We can just create an empty set.
set = Set.new
puts set.inspect # => #
We can create a set from an array!
numbers = [1, 2, 3, 2, 1]
set = Set.new(numbers)
puts set.inspect # => #
Note that when we have an array and that we make a set out of it, it removes any duplicates in the array upon creation of the set.
We have ourselves a #to_set method.
numbers = [1, 2, 3, 2, 1]
set = numbers.to_set
puts set.inspect # => #
And finally with a block.
set = Set.new do |s|
s << 1
s << 2
s << 3
s << 2
s << 1
end
puts set.inspect # => #
Again, notice that with all of these examples, when we create a set, any duplicates found are removed. The set will only contain unique values.
Your First Set Steps
So we now know how to create a set. And no we are not going to make you draw the rest of the owl by jumping into set math. Let's just start at the beginning.
Just like with an array, we can use the shovel operator to add things to a set
fruits = Set.new
puts fruits.inspect # => #
fruits << "apple"
puts fruits.inspect # => #
Instead of push, we also have an #add method. Conceptually, push doesn’t really work here, because sets aren’t an ordered collection.
fruits.add("banana")
puts fruits.inspect # => #
As we have said before, adding a duplicate DOES NOTHING.
fruits << "apple"
puts fruits.inspect # => #
We can add multiple things at a time using the #merge method.
fruits.merge(["orange", "grape", "banana"])
puts fruits.inspect # => #
We’ve added elements and now we should remove them.
colors = Set.new(["red", "green", "blue", "yellow"])
colors.delete("green")
puts colors.inspect # => #
We can also delete items with a conditional.
colors = Set.new(["red", "green", "blue", "yellow"])
colors.delete_if { |color| color.length > 3 }
puts colors.inspect # => #
Finally, we can check membership. #include? and #member? are the same thing.
animals = Set.new(["dog", "cat", "bird"])
puts animals.include?("cat") # => true
puts animals.member?("cat") # => true
puts animals.include?("cat") # => false
puts animals.member?("cat") # => false
Set Operations
So this is where the rubber meets the road. We’ve mentioned previously set operations, but this is what it will look like in code.
Union is where you want to get all of the elements that exist in either set.
set_a = Set.new([1, 2, 3, 4])
set_b = Set.new([3, 4, 5, 6])
union = set_a | set_b
puts union.inspect # => #
Intersection is when you want elements in BOTH sets.
set_a = Set.new([1, 2, 3, 4])
set_b = Set.new([3, 4, 5, 6])
intersection = set_a & set_b
puts intersection.inspect # => #
Difference is when you want elements in set_a but NOT set_b.
set_a = Set.new([1, 2, 3, 4])
set_b = Set.new([3, 4, 5, 6])
difference = set_a - set_b
puts difference.inspect # => #
Finally, we have symmetric difference. I’ve actually never heard this term before, and upon looking it up, I found other names for it that you might find familiar - Disjunctive Union or Exclusive OR.
set_a = Set.new([1, 2, 3, 4])
set_b = Set.new([3, 4, 5, 6])
sym_difference = set_a ^ set_b
puts sym_difference.inspect # => #
Iterating Over Sets
Thankfully, we can use our love, enumerables on sets.
We can keep things simple.
planets = Set.new(["Mercury", "Venus", "Earth", "Mars"])
planets.each do |planet|
puts "Planet: #{planet}"
end
We can use other methods.
planets = Set.new(["Mercury", "Venus", "Earth", "Mars"])
large_planets = planets.select { |planet| planet.length > 5 }
puts large_planets.inspect # => #
I also suppose we can turn our set back into an array if we really needed to.
planets = Set.new(["Mercury", "Venus", "Earth", "Mars"])
planets_array = planets.to_a
puts "Array: #{planets_array}" # => Array: ["Mercury", "Venus", "Earth", "Mars"]
When do we use sets over arrays?
We want to use a set when uniqueness is a core part of what we are trying to do.
We want to check membership or if an element is included in the collection SUPER FAST.
We want access to set operations. This is a real-world example with roles:
require 'set'
employees = Set.new(["Alice", "Bob", "Charlie"])
managers = Set.new(["Bob", "Diana"])
# Employees who are also managers
employee_managers = employees & managers
puts employee_managers.inspect # => #
# Everyone (employees and managers)
all_staff = employees | managers
puts all_staff.inspect # => #
# Employees who aren't managers
regular_employees = employees - managers
puts regular_employees.inspect # => #
# People who are either employees or managers, but not both
exclusive_roles = employees ^ managers
puts exclusive_roles.inspect # => #
- You want to reduce memory overhead from duplicates.
When do we use arrays over sets?
Let’s think about the reverse. We want to use arrays when:
Order matters.
When repeated elements represent real data - when duplicates are meaningful.
When position of data in your collection matters.
You need Array methods.
Additional Resources
This blog was written by Turing instructor, Mike Dao.
Be sure to follow Turing School of Software and Design on Instagram, X, and LinkedIn - @Turing_School