































































![OpenAI Announces 4o Image Generation [Video]](https://www.iclarified.com/images/news/96821/96821/96821-640.jpg)

![Apple to Avoid EU Fine Over Browser Choice Screen [Report]](https://www.iclarified.com/images/news/96813/96813/96813-640.jpg)










![Do you care about Find My Device privacy settings? [Poll]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/06/Chipolo-One-Point-with-Find-My-Device-app.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











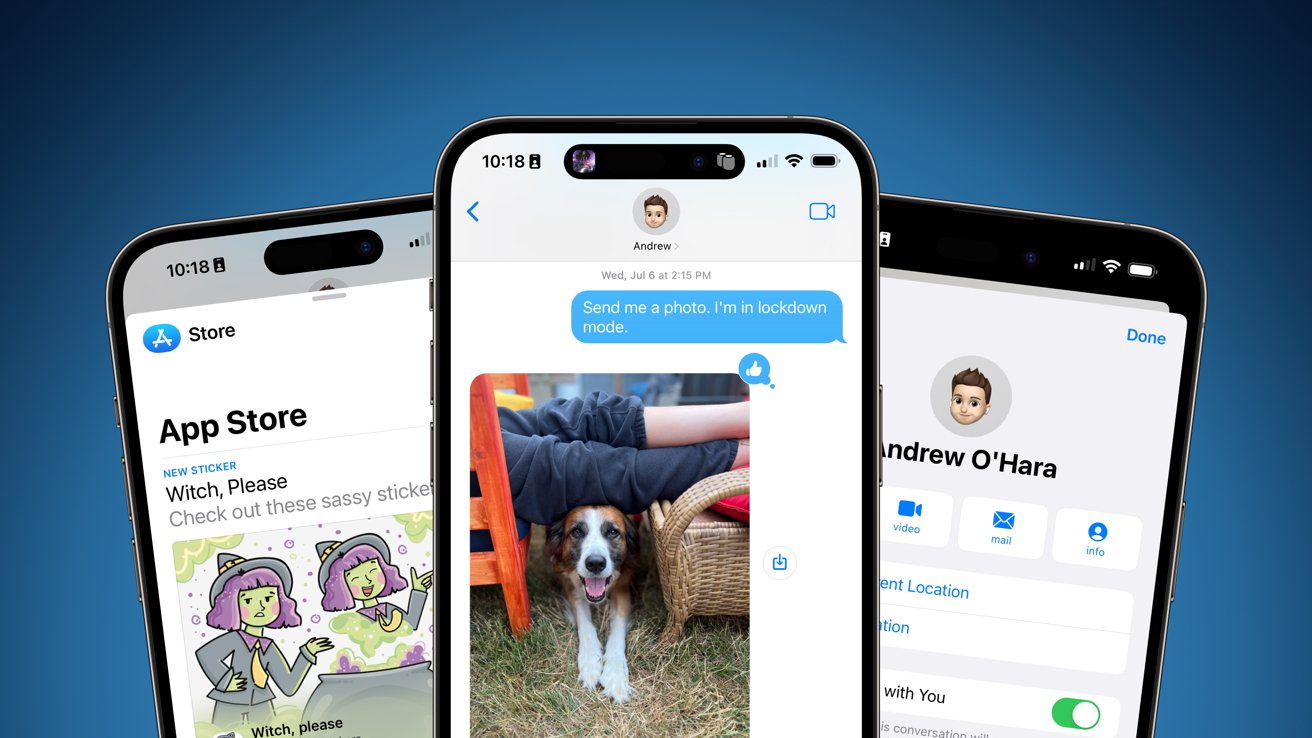
-xl-xl.jpg)















































































































































![[The AI Show Episode 140]: New AGI Warnings, OpenAI Suggests Government Policy, Sam Altman Teases Creative Writing Model, Claude Web Search & Apple’s AI Woes](https://www.marketingaiinstitute.com/hubfs/ep%20140%20cover.png)
![[The AI Show Episode 139]: The Government Knows AGI Is Coming, Superintelligence Strategy, OpenAI’s $20,000 Per Month Agents & Top 100 Gen AI Apps](https://www.marketingaiinstitute.com/hubfs/ep%20139%20cover-2.png)













































































































![Is there an idiom for specifying axes and dimensions of array(-like) parameters? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)












































.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)
.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)


























































Stable Reinforcement Learning Method Reduces Training Data Needs for Language Models by 90%
This is a Plain English Papers summary of a research paper called Stable Reinforcement Learning Method Reduces Training Data Needs for Language Models by 90%. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview Tapered Off-Policy REINFORCE (TOPOR) offers a stable reinforcement learning method for large language models Combines off-policy optimization with importance tapering to reduce variance Achieves better performance than alternative methods while using less training data Works with both human-labeled and automatically generated preference data Addresses key stability issues in traditional REINFORCE algorithms Plain English Explanation Training large language models (LLMs) to align with human preferences is challenging. Traditional methods like REINFORCE (a basic reinforcement learning approach) are unstable—they can easily go off track during training. The researchers developed [Tapered Off-Policy REINFORCE... Click here to read the full summary of this paper
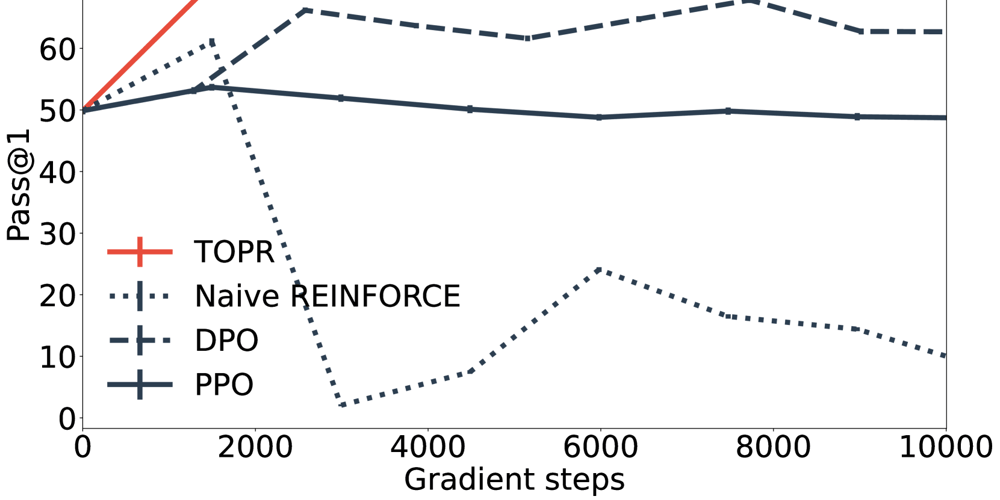
This is a Plain English Papers summary of a research paper called Stable Reinforcement Learning Method Reduces Training Data Needs for Language Models by 90%. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- Tapered Off-Policy REINFORCE (TOPOR) offers a stable reinforcement learning method for large language models
- Combines off-policy optimization with importance tapering to reduce variance
- Achieves better performance than alternative methods while using less training data
- Works with both human-labeled and automatically generated preference data
- Addresses key stability issues in traditional REINFORCE algorithms
Plain English Explanation
Training large language models (LLMs) to align with human preferences is challenging. Traditional methods like REINFORCE (a basic reinforcement learning approach) are unstable—they can easily go off track during training.
The researchers developed [Tapered Off-Policy REINFORCE...







